R语言文本特征工程:词袋模型

作者:黄天元,复旦大学博士在读,目前研究涉及文本挖掘、社交网络分析和机器学习等。希望与大家分享学习经验,推广并加深R语言在业界的应用。
邮箱:huang.tian-yuan@qq.com
Bag of words,中文译作词袋模型,即把文本的单词分开之后,统计每个单词出现的次数,然后作为该文本的特征表示。我们引用网上的一个图片来解释:
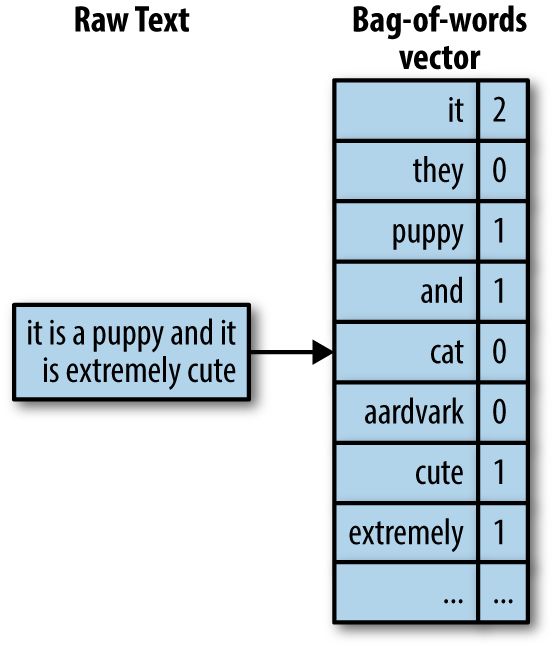
把原始文本转化为词袋模型的表示。Courtesy Zheng & Casari (2018)
下面我们会自己构造数据然后举一个实际例子,首先加载包:
library(pacman)
p_load(tidyverse,tidytext)第一步,我们先手动创造一个数据集:
corpus = c('The sky is blue and beautiful.',
'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!' )
labels = c('weather', 'weather', 'animals', 'animals', 'weather', 'animals')
tibble(Document = corpus,Category = labels,) -> corpus_df
corpus_df %>%
mutate(id = 1:n()) -> corpus_df
corpus_df## # A tibble: 6x 3
## Document Category id
## <chr> <chr> <int>
## 1 The sky is blue and beautiful. weather 1
## 2 Love this blue and beautiful sky! weather 2
## 3 The quick brown fox jumps over the lazy dog. animals 3
## 4 The brown fox is quick and the blue dog islazy! animals 4
## 5 The sky is very blue and the sky is verybeautiful today weather 5
## 6 The dog is lazy but the brown fox is quick! animals 6
因为这里有多个文本,因此要先根据文本分组,再来进行词袋模型分词。
corpus_df %>%
group_by(id) %>%
unnest_tokens(word,Document) %>%
count(word,sort = T) %>%
ungroup() -> bag_of_words_raw中文里面有“的”、“了”等等不携带信息的词,而英文则有the/is等词,我们不希望把它们考虑进去,因此需要去掉。这里我们用包里面自带的停止词包,然后取出它们。
data("stop_words")
bag_of_words_raw %>%
anti_join(stop_words) %>%
arrange(id) -> bag_of_words_tidy## Joining, by = "word"
现在让我们看看转化后的格式是什么样的。
bag_of_words_tidy %>%
print(n = Inf)## # A tibble: 27x 3
## idword n
## <int> <chr> <int>
## 1 1 beautiful 1
## 2 1 blue 1
## 3 1 sky 1
## 4 2 beautiful 1
## 5 2 blue 1
## 6 2 love 1
## 7 2 sky 1
## 8 3 brown 1
## 9 3 dog 1
## 10 3fox 1
## 11 3jumps 1
## 12 3lazy 1
## 13 3quick 1
## 14 4blue 1
## 15 4brown 1
## 16 4dog 1
## 17 4fox 1
## 18 4lazy 1
## 19 4quick 1
## 20 5sky 2
## 21 5beautiful 1
## 22 5 blue 1
## 23 6brown 1
## 24 6dog 1
## 25 6fox 1
## 26 6lazy 1
## 27 6quick 1
也许有时候你需要的是文档-词矩阵,那么好,我们来变形:
bag_of_words_tidy %>%
spread(word,n,fill = 0) -> bag_of_words_dtm
bag_of_words_dtm## # A tibble: 6x 11
## idbeautiful blue brown dog fox jumps lazy love quick sky
## <int> <dbl><dbl> <dbl> <dbl> <dbl> <dbl> <dbl><dbl> <dbl> <dbl>
## 1 1 1 1 0 0 0 0 0 0 0 1
## 2 2 1 1 0 0 0 0 0 1 0 1
## 3 3 0 0 1 1 1 1 1 0 1 0
## 4 4 0 1 1 1 1 0 1 0 1 0
## 5 5 1 1 0 0 0 0 0 0 0 2
## 6 6 0 0 1 1 1 0 1 0 1 0
这样,我们就可以随心所欲地在R里面使用词袋模型了。不过真实的应用中,文档-词矩阵会特别大,我们可以用cast_dfm或cast_dtm函数把它变成一个稀疏矩阵,然后再处理。这取决于你后续要用什么分析,因为特定的文本包中具有特定的矩阵格式。词袋模型是典型的文本数据特征工程方法,可以不用,不能不会,因为它是后面n元模型、word2vec的基础。

往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
登录查看更多
相关内容

专知会员服务
62+阅读 · 2019年10月26日
Arxiv
11+阅读 · 2019年4月1日
Arxiv
4+阅读 · 2018年11月5日
Arxiv
8+阅读 · 2018年8月22日


相关VIP内容
专知会员服务
62+阅读 · 2019年10月26日
相关资讯
相关论文
Arxiv
11+阅读 · 2019年4月1日
Arxiv
4+阅读 · 2018年11月5日
Arxiv
8+阅读 · 2018年8月22日