独家 | 手把手教你运用深度学习构建视频人脸识别模型(Python实现)

作者:Faizan Shaikh
翻译:季洋
校对:王雨桐
本文约2700字,建议阅读10+分钟。
本文将展示如何使用开源工具完成一个人脸识别的算法。
引言
“计算机视觉和机器学习已经开始腾飞,但是大多数人并不清楚计算机在识别一张图片的时候,它到底看到了什么。”
——麦克.克里奇
计算机视觉这个精彩领域在最近几年突飞猛进,目前已经具备了一定的规模。大量的应用已经在全世界被广泛使用 —— 而这也仅仅是个开始!
在这个领域中,我最赞赏的一件事就是对开源的接纳。即使是那些技术大佬们也乐于与大家分享新的突破和创新,从而使这些技术不再“曲高和寡”。
其中一项技术就是人脸识别,它可以解决很多现实问题(如果被正确又合乎伦理地使用)。本文将展示如何使用开源工具完成一个人脸识别的算法。以下是的一个有趣的演示,这也为接下来的内容做好铺垫:

所以,你准备好了吗?精彩才刚刚开始!
提示:如果你想要了解计算机视觉的复杂性, 下面这个深度学习的计算机视觉是很好的起步课程。
Computer Vision using Deep Learning
https://trainings.analyticsvidhya.com/courses/course-v1:AnalyticsVidhya+CVDL101+CVDL101_T1 /about
内容
人脸识别中有前景的应用
系统准备—— 硬件/软件要求
硬件安装
软件安装
探究Python的实现
简单演练
人脸识别案例
人脸识别中有前景的应用
我找到了一些经典的人脸识别技术应用案例。你一定碰到过类似的例子,但并没有意识到这些场景背后到底使用了什么技术!
例如,对于每一张上传到平台的图像,Facebook都用自动生成的标签建议替代手动给图像加标签。Facebook使用了一个简单的人脸识别算法来分析图像中人脸的像素,同时将它和相关用户做比较。我们将学习如何创建一个人脸识别模型,但是在我们描述相关的技术细节之前,先来探讨一些其它的应用案例。
我们现在常常用最新的“人脸解锁”功能来解锁手机。这是一个很小的人脸识别技术案例,以帮助维护个人数据安全。同样的想法可以应用于更大范围,使相机能够在抓取图像的同时识别人脸。

人脸识别技术还应用于广告、医疗、银行等行业中,只是不太被人所知。在大多数公司,甚至在很多会议中,进入时都需要佩戴身份识别卡。但是我们能否找到一种无需佩戴任何身份识别卡就能进出的方法呢?人脸识别非常有助于这个想法的实现。人们只需要看着镜头,系统就会自动判断他是否具备权限。
另一个有趣的人脸识别应用是计算参与活动(如会议或音乐会)的人数。这并不是手动计算参加者的数量,我们可以安装一个摄像机,它能够捕捉参加者影像并计算人员总数。如此可以使得过程自动化,同时也能节省大量人力。这个技术非常实用,不是吗?

你可以想出更多类似的应用 ——在下面的留言中和我们分享吧!
本文将侧重于人脸识别的实践应用,对算法如何运作只作注释。如果你想了解更多,可以浏览下面这篇文章:
Understanding and Building an Object Detection Model from Scratch in Python
https://www.analyticsvidhya.com/blog/2018/06/understanding-building-object-detection-model-python/
系统准备 —— 硬件/软件要求
现在你知道了人脸识别技术可以实现的应用,让我们看看如何能够通过可用的开源工具来实现它。这就能体现领域的优势了 —— 分享开源代码的意愿和行动都是其他领域无法比拟的。
针对本文,以下列出了我使用的和推荐使用的系统配置如下:
一个网络摄像头(罗技 Logitech C920)用来搭建一个实时人脸识别器,并将其安装在联想E470 ThinkPad系列笔记本(英特尔酷睿5第7代内核Core i5 7th Gen)。你也可以使用笔记本电脑自带的摄像头,或电视监控系统摄像头。在任意系统上做实时的视频分析都可以,并不一定是我正在使用的配置。
使用图形处理器(GPU)来加速视频处理会更好。
在软件方面,我们使用Ubuntu 18.04操作系统安装所有必要的软件。
为了确保搭建模型前的每件事都安排妥当,接下来我们将详细探讨如何配置。
步骤一:硬件安装
首要的事就是检查网络摄像头是否正确安装。在Ubuntu上有一个简单小技巧 —— 看一下相应的设备在操作系统中是否已经被注册。你可以照着以下的步骤来做:
步骤1.1:在连接网络摄像头到笔记本电脑之前,通过在命令提示符窗口输入命令ls /dev/video* 来检查所有连接上的视频设备。这将列出那些已经连接入系统的视频设备。

步骤1.2:连接网络摄像头并再次执行这一命令。

如果网络摄像头被成功连接,将显示一个新的设备。
步骤1.3:另一件你可以做的事是使用任一网络摄像头软件来检查摄像头能否正常工作,Ubuntu中你可以用“Cheese”来检查。
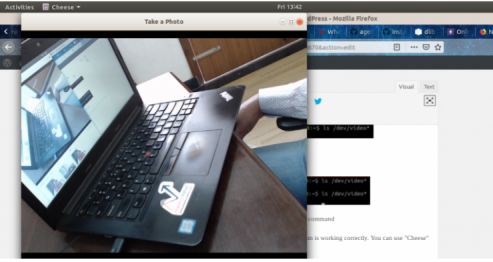
这里我们可以看出网络摄像头已经安装成功啦!硬件部分完成!
步骤二:软件安装
步骤2.1:安装Python
本文中的代码是用Python 3.5编写。尽管有多种方法来安装Python,我还是建议使用Anaconda —— 数据科学中最受欢迎的Python发行版。
Anaconda下载链接:
https://www.anaconda.com/download/
步骤2.2:安装OpenCV
OpenCV(Open Source Computer Vision) 是一个旨在创建计算机视觉应用的软件库。它包含大量预先写好的图像处理功能。要安装OpenCV,需要一个该软件库的pip安装:
pip3 install opencv-python
步骤2.3:安装face_recognition应用程序接口
最后,我们将会使用face_recognition,它号称是世界上最简单的人脸识别应用程序Python接口。安装如下:
pip install dlib pip install face_recognition
让我们开始探索它的实现吧。
既然你已经配置好了系统,是时候探究真正的使用了。首先,我们将快速地创建程序,然后分段来解释我们做了什么。
简单流程
首先,创建一个face_detector.py文件同时复制下面的代码:
# import librariesimport cv2import face_recognition# Get a reference to webcam video_capture = cv2.VideoCapture("/dev/video1")# Initialize variablesface_locations = []while True: # Grab a single frame of video ret, frame = video_capture.read() # Convert the image from BGR color (which OpenCV uses) to RGB color (which face_recognition uses) rgb_frame = frame[:, :, ::-1] # Find all the faces in the current frame of video face_locations = face_recognition.face_locations(rgb_frame) # Display the results for top, right, bottom, left in face_locations: # Draw a box around the face cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) # Display the resulting image cv2.imshow('Video', frame) # Hit 'q' on the keyboard to quit! if cv2.waitKey(1) & 0xFF == ord('q'): break# Release handle to the webcamvideo_capture.release()cv2.destroyAllWindows()
然后,用如下命令执行这个Python文件:
python face_detector.py
如果一切运行正确,会弹出一个新窗口,以运行实时的人脸识别。
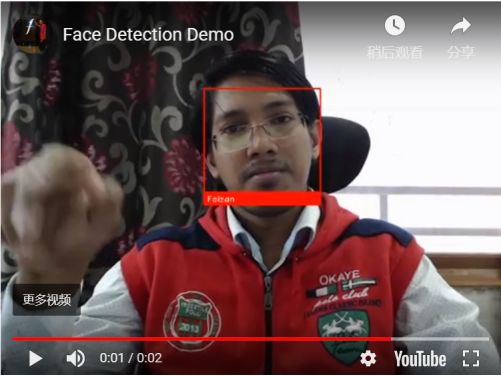
总结一下,以上的代码做了这些:
首先,我们配置了运行影像分析的硬件。
接下来我们逐帧地捕捉实时影像。
然后我们处理每一帧并且提取图像中所有人脸的位置。
最后,我们以视频形式描绘出这些帧,同时标注人脸的位置。
这很简单,不是吗? 如果你想深入了解更多细节,我已经对各代码段做了详尽注解。你可以随时回顾我们做了什么。
人脸识别案例
有趣的事情并没有结束!我们还能做一件很酷的事情 —— 结合以上代码实现一个完整的案例。并且不需要从零开始,我们仅仅需要对代码做一些小的改动。
例如,你想搭建一个自动的摄像头定位系统,来实时跟踪演讲者的位置。根据他的位置,系统会转动摄像头使得演讲者总是处于视频的中间。
我们怎么做到这一点?第一步就是要搭建一个可辨识视频中人(们)的系统,并且重点放在演讲者的位置。

让我们来看一下如何才能实现这个案例。本文将以一个Youtube上的影片为例,视频记录了一个演讲者在2017年数据黑客峰会(DataHack Summit 2017)上的演讲。
首先,我们引入必要的代码库:
import cv2 import face_recognition
然后,读入影片并得到影片长度:
input_movie = cv2.VideoCapture("sample_video.mp4") length = int(input_movie.get(cv2.CAP_PROP_FRAME_COUNT))
随后我们新建一个输出文件,使其拥有和输入文件相似的分辨率和帧频。
载入演讲者的一个影像样本,来识别视频中的主角:
image = face_recognition.load_image_file("sample_image.jpeg") face_encoding = face_recognition.face_encodings(image)[0] known_faces = [ face_encoding, ]
做完这些,现在我们可以执行一个循环来完成如下步骤:
从影片中提取一帧影像
找到所有的人脸并完成识别
新建一个影片,来将源帧图像和标注演讲者脸部的位置合并起来
让我们看看这部分代码:
# Initialize variablesface_locations = []face_encodings = []face_names = []frame_number = 0while True: # Grab a single frame of video ret, frame = input_movie.read() frame_number += 1 # Quit when the input video file ends if not ret: break # Convert the image from BGR color (which OpenCV uses) to RGB color (which face_recognition uses) rgb_frame = frame[:, :, ::-1] # Find all the faces and face encodings in the current frame of video face_locations = face_recognition.face_locations(rgb_frame, model="cnn") face_encodings = face_recognition.face_encodings(rgb_frame, face_locations) face_names = [] for face_encoding in face_encodings: # See if the face is a match for the known face(s) match = face_recognition.compare_faces(known_faces, face_encoding, tolerance=0.50) name = None if match[0]: name = "Phani Srikant" face_names.append(name) # Label the results for (top, right, bottom, left), name in zip(face_locations, face_names): if not name: continue # Draw a box around the face cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) # Draw a label with a name below the face cv2.rectangle(frame, (left, bottom - 25), (right, bottom), (0, 0, 255), cv2.FILLED) font = cv2.FONT_HERSHEY_DUPLEX cv2.putText(frame, name, (left + 6, bottom - 6), font, 0.5, (255, 255, 255), 1) # Write the resulting image to the output video file print("Writing frame {} / {}".format(frame_number, length)) output_movie.write(frame)# All done!input_movie.release()cv2.destroyAllWindows()
这段代码将输出如下类似的结果:
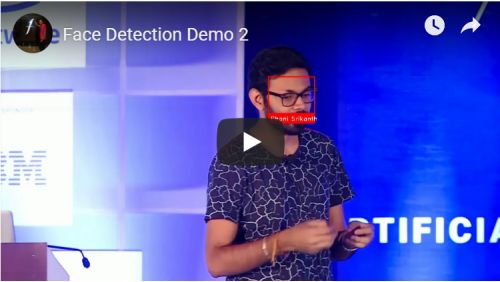
人脸识别真的是一件了不起的事情!
总结
恭喜!你现在已经掌握了如何为一些现实场景搭建人脸识别系统。深度学习是一个如此令人着迷的领域,而我非常期待看到它未来的发展。
在这篇文章中,我们学习了如何在真实情境中运用开源工具来构建实时人脸识别系统。我希望你能创造更多类似的应用,并且自己尝试更多的案例。相信我,还有很多东西要学习,而他们真的很趣!
一如既往,如果你有任何问题或建议尽管在下面的留言部分提出来吧!
原文标题:
Building a Face Detection Model from Video using Deep Learning (Python Implementation)
原文链接:
https://www.analyticsvidhya.com/blog/2018/12/introduction-face-detection-video-deep-learning-python/
译者简介

季洋,苏州某IT公司技术总监,从业20年,现在主要负责Java项目的方案和管理工作。对大数据、数据挖掘和分析项目跃跃欲试却苦于没有机会和数据。目前正在摸索和学习中,也报了一些线上课程,希望对数据建模的应用场景有进一步的了解。不能成为巨人,只希望可以站在巨人的肩膀上了解数据科学这个有趣的世界。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织




