本文提
出一种利用生成
模型作为图片先验的梯度攻击方法GGL,由来自美国田纳西大学,美国橡树岭国家实验室,和谷歌共同完成,论文已被 CVPR 2022 接收。
联邦学习 (federated learning) 是一种在中心服务器 (server)的协调下利用分散在各用户 (client)的本地数据集协同训练模型的一种分布式训练模式。为保证参与方隐私,训练过程中,训练数据不会离开本地,取而代之的是模型相关的信息(例如模型架构,参数梯度)会被共享至服务器端,从而降低了数据泄露的风险。
然而这种梯度共享的训练方案并非绝对安全:尽管避免了中央服务器直接接触用户数据,服务器仍可使用梯度攻击从交换的参数梯度中复原用户的本地训练数据。方法是先随机生成虚拟训练数据,并以此生成虚拟梯度,再以缩小虚拟梯度与真实梯度差距为优化目标通过梯度下降反复迭代,即可还原用户私人数据。此种攻击被称为梯度泄露(gradient leakage)[1] 或梯度逆转(gradient inversion)[2]。
为防御此种梯度攻击,一些研究提出用户在上传前可先对梯度信息添加噪声扰动或者进行有损变换(例如梯度裁剪或梯度稀疏化处理)来更好的保障信息安全。此前研究 [3] 也表明混淆数据表征(data representation)并依此生成梯度信息亦可有效防止梯度泄露。
那么如何检验此类隐私防御的安全性?最直观的想法是可引入先验信息来补偿防御造成的信息损失。基于这一思想,本文探索一种新的梯度攻击方式 – 生成式梯度泄露(Generative Gradient Leakage,GGL)。相较于传统梯度攻击,GGL 通过借助生成对抗网络(Generative Adversarial Network, GAN)在公开数据集上提取的先验信息以及适应性梯度变换,可以从更少量有噪音的梯度信息中复原隐私数据,从而获得更强的防御耐受力。我们希望这种方法可作为一种实证研究的手段来帮助审计隐私防御下的数据泄露。
这项由美国田纳西大学,美国橡树岭国家实验室,和谷歌共同完成的研究已被 CVPR 2022 接收。
![]()
给定训练数据 x,从其交换的梯度信息 y 中恢复训练数据的过程可被视为一个逆问题:
![]()
其中
![]() 是前向运算符,用来计算损失并返回模型梯度。当用户在本地采取防御措施时,问题变为:
是前向运算符,用来计算损失并返回模型梯度。当用户在本地采取防御措施时,问题变为:
![]()
其中
![]() 是用户施加的有损梯度变换,而
是用户施加的有损梯度变换,而
![]() 是随机噪声。由于此问题高度非线性且不适定,以往的方法试图通过如下形式来求解:
是随机噪声。由于此问题高度非线性且不适定,以往的方法试图通过如下形式来求解:
![]()
其中
![]() 是一种距离度量,而
是一种距离度量,而
![]() 是标准图像先验(如 total variation)。尽管这种方法可以有效从真实梯度中还原训练图像,当面临低保真且有噪声的梯度信息时,往往难以还原出真实的自然图片。
是标准图像先验(如 total variation)。尽管这种方法可以有效从真实梯度中还原训练图像,当面临低保真且有噪声的梯度信息时,往往难以还原出真实的自然图片。
![]()
近年来深度学习模型已在压缩感知中被作为图片先验广泛运用。受此启发,本文利用在公开数据集上预训练的生成模型(GAN)作为先验,在 GAN 的潜在空间中寻找最接近真实图片梯度的隐形表达,以此来降低搜索空间并提升生成图片质量,同时在优化过程中可以采取相同变换进行适应性攻击。给定预训练生成模型
![]() ,我们求解以下优化问题:
,我们求解以下优化问题:
![]()
其中
![]() 为 GAN 的潜在空间,而
为 GAN 的潜在空间,而
![]() 是正则化项。
由于此优化问题非凸,选取合适的优化策略对于求解后生成的图像质量非常重要。此前梯度攻击中多选取基于梯度的优化算法,如 Adam 和 L-BFGS。然而这类优化器的效果非常依赖起始点的选择,往往需要多次尝试才能找到相对合适的解。并且我们发现,对于复杂的生成器,梯度优化算法非常容易收敛至局部最优,导致最后还原效果很差。因此,我们探索了两种无梯度的优化算法,即 Bayesian Optimization (BO) 和 Covariance Matrix Adaptation Evolution Strategy (CMA-ES)。
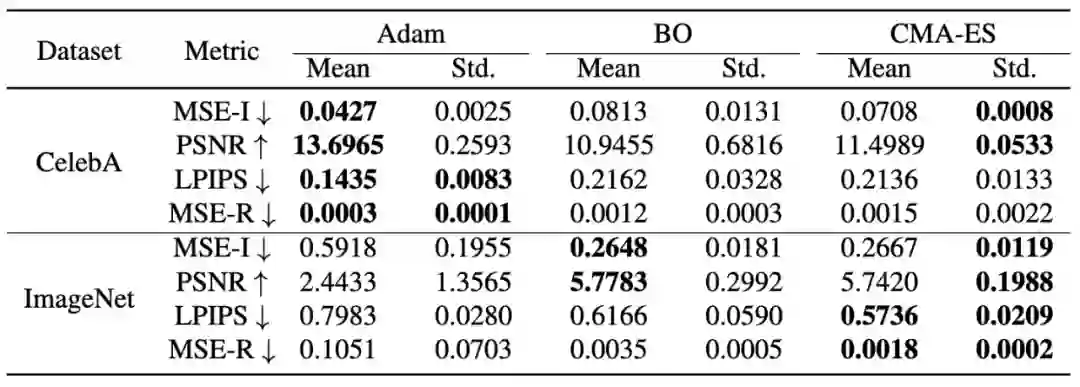
本文在 ImageNet 图像分类和 CelebA 人脸数据集上进行了实验验证。图 1 和表 1 分别定性和定量地比较了不同优化方法的还原效果。可以看出基于梯度和无梯度优化算法在 CelebA 数据集上还原效果相近。然而,在更复杂的 ImageNet 数据集上,无梯度优化方法的还原结果明显优于基于梯度的算法,其中,CMA-ES 还原效果最优。因此,GGL 选取 CMA-ES 在作为默认优化器进行后续实验。
是正则化项。
由于此优化问题非凸,选取合适的优化策略对于求解后生成的图像质量非常重要。此前梯度攻击中多选取基于梯度的优化算法,如 Adam 和 L-BFGS。然而这类优化器的效果非常依赖起始点的选择,往往需要多次尝试才能找到相对合适的解。并且我们发现,对于复杂的生成器,梯度优化算法非常容易收敛至局部最优,导致最后还原效果很差。因此,我们探索了两种无梯度的优化算法,即 Bayesian Optimization (BO) 和 Covariance Matrix Adaptation Evolution Strategy (CMA-ES)。
本文在 ImageNet 图像分类和 CelebA 人脸数据集上进行了实验验证。图 1 和表 1 分别定性和定量地比较了不同优化方法的还原效果。可以看出基于梯度和无梯度优化算法在 CelebA 数据集上还原效果相近。然而,在更复杂的 ImageNet 数据集上,无梯度优化方法的还原结果明显优于基于梯度的算法,其中,CMA-ES 还原效果最优。因此,GGL 选取 CMA-ES 在作为默认优化器进行后续实验。
![]()
![]()
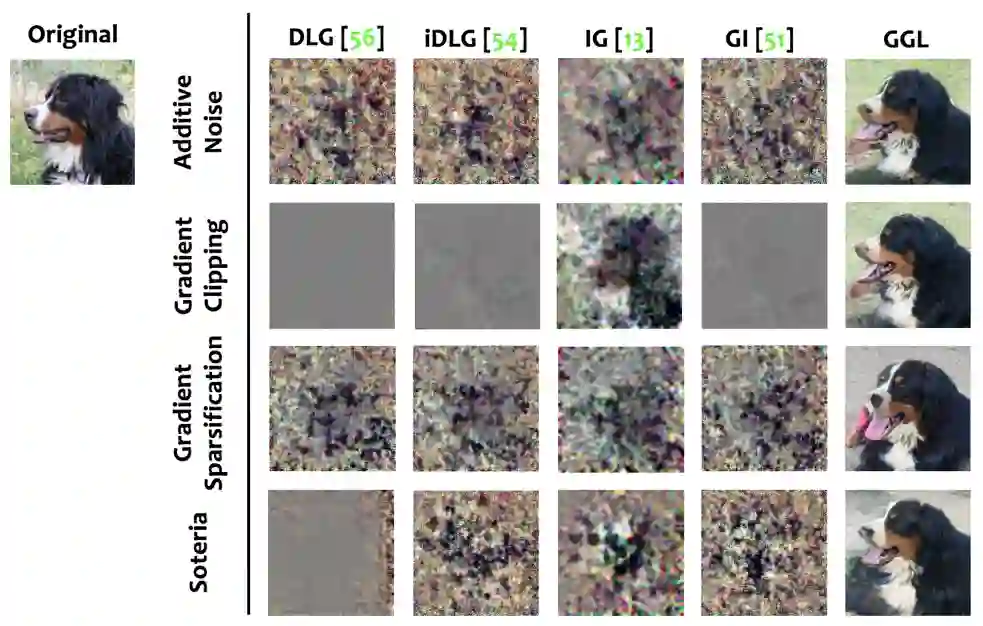
图 3 和图 4 分别在 CelebA 和 ImageNet 数据集上比较了 GGL 和现存攻击方法在面对不同防御的情况下的还原效果。从视觉比较及表 2 的定量结果中可以看到,相比于其他还原方法,借助于生成模型的图片先验,GGL 即便是在面对较强的防御方法时也可以从有损失的梯度中有效还原出大部分的图片信息。
![]()
![]()
![]()
图 5 展示了 GGL 面对梯度噪声和梯度剪裁,以及两者结合的防御情况下的还原效果。可以看到,与仅添加噪声或梯度剪裁相比,当面对梯度噪声 + 剪裁时,GGL 还原图片的质量有所下降,但仍可一定程度上还原原始图片的信息。
![]()
通过利用在公开数据集上提取的先验信息以及适应性梯度变换,GGL 在面对一些隐私防御时仍可有效还原出大部分图片信息,从而可以作为一种审计隐私手段来分析数据泄露风险。
[1] Zhu, Ligeng, et al. "Deep leakage from gradients." Advances in Neural Information Processing Systems. 2019.
[2] Geiping, Jonas, et al. "Inverting gradients-how easy is it to break privacy in federated learning?." Advances in Neural Information Processing Systems. 2020.
[3] Sun, Jingwei, et al. "Soteria: Provable defense against privacy leakage in federated learning from representation perspective." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

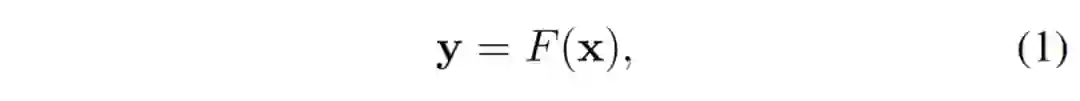
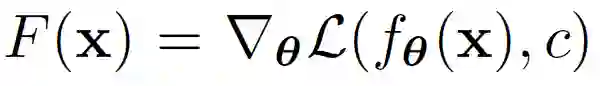 是前向运算符,用来计算损失并返回模型梯度。当用户在本地采取防御措施时,问题变为:
是前向运算符,用来计算损失并返回模型梯度。当用户在本地采取防御措施时,问题变为:
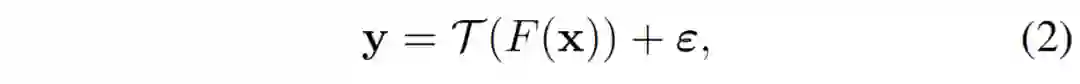
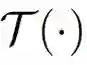 是用户施加的有损梯度变换,而
是用户施加的有损梯度变换,而
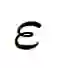 是随机噪声。由于此问题高度非线性且不适定,以往的方法试图通过如下形式来求解:
是随机噪声。由于此问题高度非线性且不适定,以往的方法试图通过如下形式来求解:
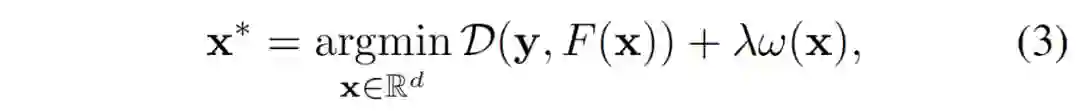
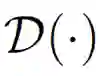 是一种距离度量,而
是一种距离度量,而
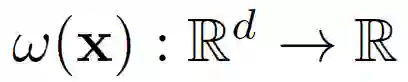 是标准图像先验(如 total variation)。尽管这种方法可以有效从真实梯度中还原训练图像,当面临低保真且有噪声的梯度信息时,往往难以还原出真实的自然图片。
是标准图像先验(如 total variation)。尽管这种方法可以有效从真实梯度中还原训练图像,当面临低保真且有噪声的梯度信息时,往往难以还原出真实的自然图片。

 ,我们求解以下优化问题:
,我们求解以下优化问题:
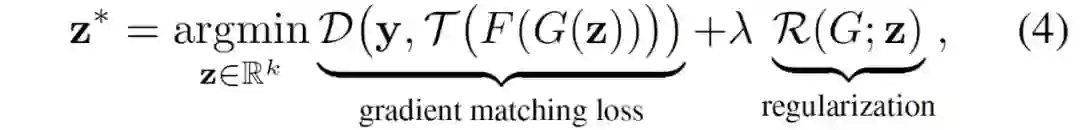
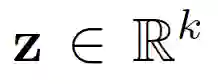 为 GAN 的潜在空间,而
为 GAN 的潜在空间,而
 是正则化项。
是正则化项。