WWW21最新「比较学习」教程,135页PPT阐述从排名数据中学习

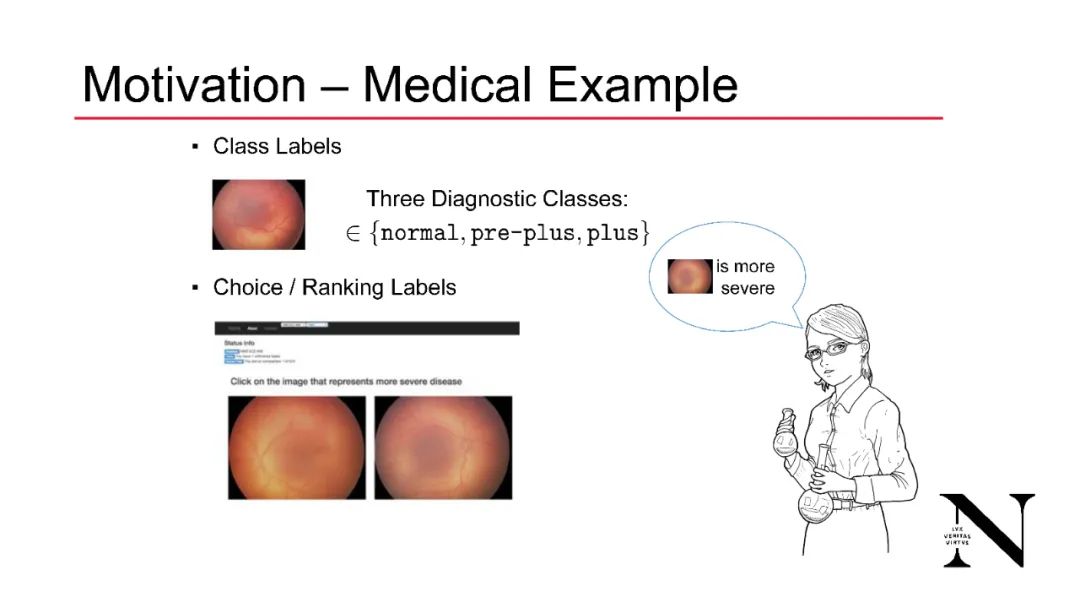
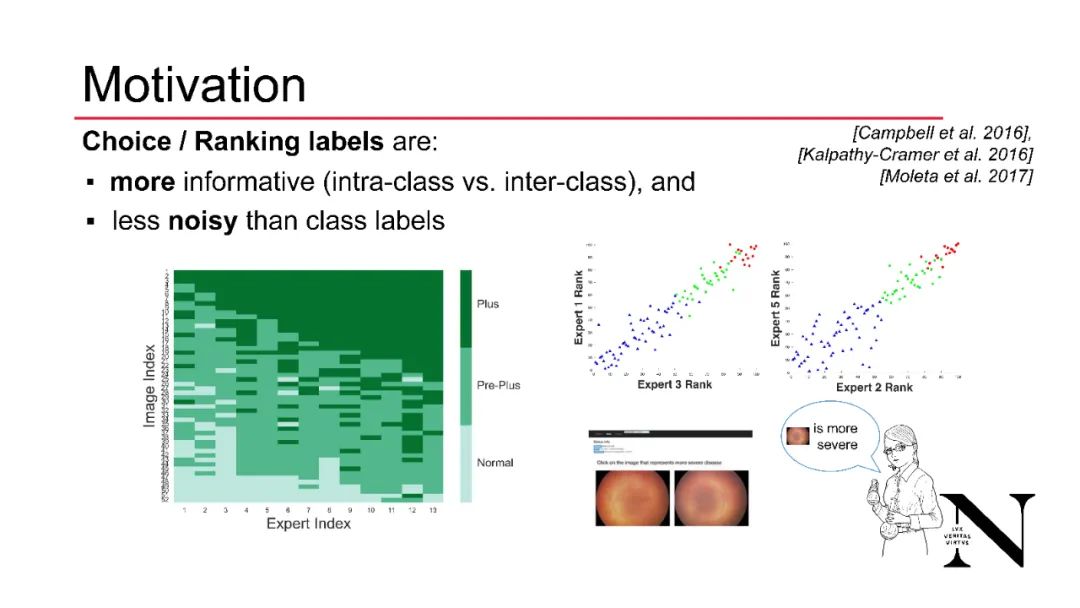
人类生成的类别标签通常是嘈杂的,因为从多个专家收集的数据在不同标签之间表现出不一致。为了改善这一效果,一种方法是要求标记者对样本进行比较或排序:当类别标签被排序时,面对两个或更多样本的标记者可以根据类别的从属关系对它们按w.r.t.的相对顺序进行排序。比较比类别标签更能提供信息,因为它们捕捉了类别之间和类别内部的关系;后者并不仅仅通过类别标签来揭示。此外,在实践中,比较标签的可变性减少了:这在许多领域的实验中都观察到了,这是因为人们经常发现做出相对判断比做出绝对判断更容易。
然而,从比较中学习带来了计算上的挑战回归排名特征是一个计算密集型任务。从𝑁样本之间的成对比较中学习对应于对𝑂(𝑁^2)比较标签的推理。更一般地,从大小为K的样本子集的排名中学习对应于对𝑂(𝑁^K)标签的推理。这需要显著改善性能,例如,最大似然估计(MLE)算法在这样的数据集。最后,收集排名也是劳动密集型的。这正是因为要标记的势集的大小为K的空间的大小为𝑂(𝑁^K)。
本教程将回顾经典的和最近的方法来解决从比较中学习的问题,更广泛地说,从排名数据中学习。将特别关注排名回归设置,即排名是从样本特征回归。
https://neu-spiral.github.io/LearningFromComparisons/
Parametric models: Bradley-Terry, Plackett-Luce, Thurstone.
Non-parametric Models: noisy-permutation model, Mallows model, matrix factorization methods.
Maximum Likelihood Estimation and spectral algorithms.
Ranking regression and variational inference methods applied to comparisons.
Sample complexity guarantees for ranking regression.
Deep neural network models and accelerated learning methods.
Active learning from comparisons.













专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LC135” 就可以获取《WWW21最新「比较学习」教程,135页PPT阐述从排名数据中学习》专知下载链接







