博客 | 当 AI 开始学习艺术创作,我们应该觉得担心吗?

这里是 AI 研习社,我们的博客版块已经正式推出了!欢迎大家来多多交流~
https://club.leiphone.com/page/blog
(戳文末阅读原文直接进)
社长为你推荐来自 AI 研习社精华博客,如果你也有随手写技术文章的习惯,欢迎在AI 研习社社区写博文。
以下为今天的精华博客
作者:雪莉•休斯敦
随着深度学习爆发式的成功,算法渐渐的被引入了一个人类认为相对安全的领域 —— 创造引人注目的艺术。
在过去的几年中,AI 产生的艺术得到了蓬勃的发展,这些示例也同时出现在了 RobotArt 和 NVIDIA's DeepArt 论坛上:

尽管这些算法模型是令人拍案叫绝的技术成就,但是人们就 AI 或机器学习是否能真正地像人类一样进行艺术创作还存有疑惑。一些人认为通过数学建模进行像素的堆积或识别乐章中相互连接的片段并不是真正的创造力。他们眼中,AI 缺少了点人味。但是,谁又能说的清楚,人类的大脑到底是如何实现这些创造的,真的比机器更出色吗?我们怎么能确信一个画家或者一个音乐家不是使用数学的方式或模型——类似于算法中的神经网络那样,通过多次的练习、训练实现作品的呢?
虽然这个问题在短期内看起来无法解决,但是通过对这个问题的研究和模型实现过程的学习,我们可以探究到更多有趣的东西。在这篇来自 The Gradient 博客的文章中,作者讨论了几个近期的深度学习模型成果,包括一些视觉作品和音乐作品。着重讨论风格迁移和音乐模型,最后还会介绍下发展前景。雷锋网 AI 科技评论对文章编译如下。
风格迁移
这个词看起来也许已经非常眼熟了,公认的最著名的 AI 艺术应用成果。下面是一个很常见的例子:

这张图片是什么意思?我们可以认为图片由两个部分组成:内容和风格。内容可以理解为左边小图所描述的:斯坦福大学的主楼;风格则可以参照中间小图中的:梵高的代表作,漩涡状、彩色夜晚的星空。风格迁移就是将一幅图片中的风格转移并生成到另外一张图片中。
假设,有图片 c 和 s,从 c 中我们提取新图片的内容,从 s 中提取风格。假设 y 是生成的图片。那么 y 具有 c 的内容,同时具有 s 的风格。从机器学习的视角来考虑这个问题的话,抽象两个函数,我们希望最小化 y 和 c 的内容误差,同时最小化 y 和 s 的风格误差。
那么,如何推导和生成内容误差和风格误差(Content loss&Style loss)这两个函数呢?要解决这个问题,首先需要使用数学的方式对内容和风格(Content&Style)进行定义。Gatys、Ecker、Bethge在他们的标志性的风格迁移论文对这个问题进行了解答,并使用卷积神经网络(CNNs)定义了这些函数。

以 VGG19 模型为例,将图像输入一个已经训练好的分类CNN网络。由于网络已经经过了初始化训练,网络中越高的层就可以提取出越复杂的图像特征。作者在文中指出,可以通过网络中的特征拓扑来表示一张图片的内容。同时,风格可以通过特征拓扑的关联来描述。这些关联性被存储在一个称为格拉姆矩阵(Gram Matrix)的矩阵中。
基于这种表示方法,作者将生成图像的特征映射与内容图像之间的 Euclidean 距离求和,以表现内容误差。然后,计算每层特征映射的格拉姆矩阵的 Euclidean 距离的总和,以计算风格误差。通过确定配置内容误差和风格误差不同的权重,以获得更好的图片视觉效果。
设定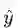

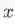
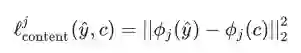
假设
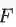
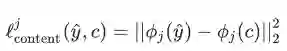
最后,将所有 L 层总误差和使用不同的权重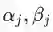
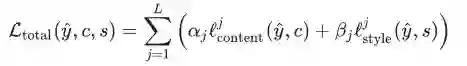
由此可见,全局的网络误差函数是带有权重的风格误差和内容误差的总和。在这里,
前馈式风格迁移
每一幅图像的风格迁移任务都是一个不同的优化过程,而且会需要不少的时间,因为要从随机噪声出发,逐步逼近最终想要的完美的图像。事实上,该论文的原始算法生成一幅图像就花费了大约两个小时,人们开始对算法的运行速度提出要求。幸运的是,Johnson, Alahi, 和 Li 在2016发表了一篇后续论文,描述了一种实时执行风格转换的方法。
不同于从 0 生成一副图像并最小化误差函数,Johnson 等人使用了一种前馈式的方法,通过训练一个神经网络来直接的将特定的风格转移到一张图像上。他们的模型具有两个组成部分——一个图像变换网络和一个误差网络。图像变换网络使用一张正常的图片,并输出相同的图片风格。不同的是,这种新的模型使用了一个预训练的误差网络。这种网络计算了特征重铸误差,即在内容上计算特征误差,同时在风格上计算分割重铸误差(使用格拉姆矩阵)。
Johnson等人使用微软的 COCO 数据集对图像变换网络进行训练,输出不同的图片风格(比如梵高的《星空》)。由这个网络产生的图片与之前的论文的结果几乎一致,但是在生成 500 张 256*256 像素的图片的任务中竟有 1060 倍的速度的提升。每张照片的生成只需要50ms:

在未来,风格转换可以推广到其他媒介,如音乐或诗歌。例如,音乐家可以重新想象一首流行歌曲,如艾德·希兰的《你的形状》,听起来像爵士乐。或者可以将现代的斯拉姆诗歌转换成莎士比亚抑扬五音格风格。目前,我们在这些领域没有足够的数据来训练好的模型,但这只是时间问题。
音乐建模
生成音乐建模是一个困难的问题,但我们已经探索了很久。
当谷歌的开源 AI 音乐项目 Magenta 刚刚启动时,它只能产生简单的旋律。然而,到了2017年的夏天,Performance RNN,这个基于LSTM的递归神经网络(RNN)出世了,它可以模仿复调音乐,同时完成定时和动态。
因为歌曲可以被看作是音符序列,所以音乐是被设计成学习序列模式的 RNN 的理想用例。我们可以通过一系列的音乐来训练一个 RNN 网络(即,一系列向量表示音符),然后从训练过 RNN 的进行旋律采样。你可以在 Magenta 的 GITHUB 页面上查看一些演示和预先训练的模型。
早期通过 Magenta 和其他音乐产生的作品可以产生单声道旋律,或者表达不同时间长度的单音,至少在一个维度上是可调的。这些模型与用于生成文本的语言模型相似:在文本生成中,模型产生代表单词的矢量,而在音乐 成中,模型产生相应的代表音符的矢量。
一个矢量可以对应很多的音符信息,那么如何通过一个个的矢量构建出一段旋律呢?假设我们想要构建一段由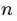
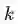
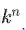

这样的搭配和可能性是非常多的,因此在这边还是考虑单音的音乐,即在同一时间只有一种音阶。大多数我们现在听的音乐都是复调的。复调的音乐是指在同一时间段内由多个音阶组成,对应着我们所熟知的和弦,或者多个乐器在同一时间同时演奏。这样的话,可行的音乐序列的数量可使用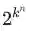
除此之外,还有一个问题。如果你曾经注意过电脑播放的音乐——甚至是人类编排的——听起来还是很机械(robotic)。而当人类真实的演奏时,根据不同的感情,演奏者会适当的加长或剪短每个音符的演奏时长(即速度或声音强度)。为了实现这一点,研发人员还需要教会机器如何进行速率和音量的调整。Performance RNN 网络于是可以仿照人类的方式调整它们的速度、播放的音量。
那么,如何通过训练让机器学会带有「情绪」地播放音乐呢?事实上,目前有个专门的数据集用作这方面的训练。雅马哈 Yamaha 电子钢琴竞赛的数据库就包含了现场表演的 MIDI 数据:每首曲子都以音阶的方式进行录制,同时包含了速率信息和时长信息。因此,除了学习在什么时间点上播放什么音阶,Performance RNN 还可以学习人类的演奏方式进行合理的播放。在链接中可以找到一些真实的案例。
现有的研究成果相较于真实人类的水平可以类比作一个六岁的孩子用一个手指进行弹奏和一个钢琴家带有情感的演奏复杂乐章之间的区别。还需要进行更多的研究:目前,很多由 Performance RNN 生成的音乐还是很机械的,因为它们还没有像人类那样使用重复的乐章或和弦进行表达。未来的研究可能可以探索鼓样本或其他乐器。
但是,仅仅是现有的成就,这些已经训练成功的模型已经足以帮助人们进行音乐创作了。
AI 艺术创作的未来
机器学习和艺术的跨界研究在过去的几年中迅速发展,这甚至是纽约大学(NYU)的一门课程的主题。深度学习的兴起对很多领域产生了极大的影响,包括:图像、音乐和文本。雷锋网 AI 科技评论去年的一篇文章中也介绍了用 AI 创作抽象艺术作品(并在读者中引发了一定争议)的研究。
这里我们只讨 AI 艺术创作的蓝图。在未来,我们可以期待机器学习成为艺术家的创作工具,如在草图中进行填色、「自动完成」图像、生成诗歌或小说的提纲或框架等。
随着日益强大的机器计算能力,我们可以训练来自不同媒体越来越多的数据,包括音频、视频或很多其他的形式等。我们现在已经有一些模型生成的案例,文本与音频和视频同步。Mor 等人的「音乐翻译网」可以在乐器和风格流派之间进行一种声学风格的转换(链接)。并且 Luan 等人还实现了适用于高分辨率照片的真实感风格转换。可以通过这种方式实现的机器媒体的潜在应用是巨大的。
尽管,就 AI 创作的艺术是否是真实的艺术这个话题是永无止境的。但是,也许我们可以从另外一个角度看待这个问题。通过将人类创作过程进行的数学化,我们也许更近一步的了解到人类的创作如此深远悠长的真正原因了。
想阅读更多博文?
欢迎点击“阅读原文”
或者移步 AI 研习社社区~



