谷歌提出元奖励学习,两大基准测试刷新最优结果

新智元报道
新智元报道
来源:Google Blog
编辑:元子
【新智元导读】RL算法由于奖励不明确,智能体可能会收到“利用环境中的虚假模式”的正反馈,这就有可能导致奖励黑客攻击。谷歌提出了使用开发元奖励学习(MeRL)来解决未指定奖励的问题,通过优化辅助奖励函数向智能体提供更精确的反馈。
强化学习(RL)为优化面向目标的行为,提供了统一且灵活的框架。
并且在解决诸如:玩视频游戏、连续控制和机器人学习等具有挑战性的任务方面,取得了显着成功。
RL算法在这些应用领域的成功,往往取决于高质量和密集奖励反馈的可用性。
然而,将RL算法的适用性,扩展到具有稀疏和未指定奖励的环境,是一个持续的挑战。
需要学习智能体从有限的反馈中,概括例如如何学习正确行为的问题。
在这种问题设置中研究RL算法性能的一种自然方法,是通过自然语言理解任务。
为智能体提供自然语言输入,并且需要生成复杂的响应,以实现输入过程中指定的目标,同时仅接收“成功-失败”的反馈。
例如一个“盲”智能体,任务是通过遵循一系列自然语言命令(例如,“右,上,上,右”)到达迷宫中的目标位置。
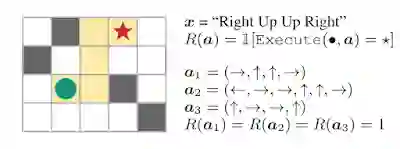
给定输入文本,智能体(绿色圆圈)需要解释命令,并基于这种解释采取动作以生成动作序列(a)。
如果智能体人达到目标(红色星级),则获得1的奖励,否则返回0。
由于智能体无法访问任何可视信息,因此智能体解决此任务,并概括为新指令的唯一方法,是正确解释指令。
在这些任务中,RL智能体需要学习从稀疏(只有少数轨迹导致非零奖励)和未指定(无目的和意外成功之间的区别)奖励。
重要的是,由于奖励不明确,智能体可能会收到“利用环境中的虚假模式”的正反馈,这就有可能导致奖励黑客攻击,在实际系统中部署时会导致意外和有害的行为。
在“学习从稀疏和未指定的奖励中进行概括”中,使用开发元奖励学习(MeRL)来解决未指定奖励的问题,通过优化辅助奖励函数向智能体提供更精确的反馈。
《Learning to Generalize from Sparse and Underspecified Rewards》论文地址:
https://arxiv.org/abs/1902.07198
MeRL与使用“新探索策略收集到成功轨迹”的记忆缓冲区相结合,从而通过稀疏奖励学习。
这个方法的有效性在语义分析中得到证明,其目标是学习从自然语言到逻辑形式的映射(例如,将问题映射到SQL程序)。
本文研究了弱监督问题设置,其目标是从问答配对中自动发现逻辑程序,而不需要任何形式的程序监督。
例如下图中找出“哪个国家赢得最多银牌?”,智能体需要生成类似SQL的程序,以产生正确的答案(即“尼日利亚”)。
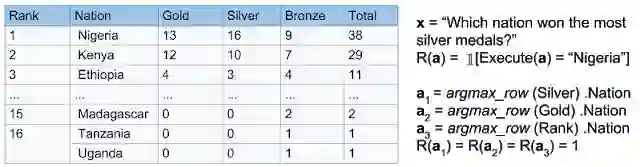
所提出的方法在WikiTableQuestions和WikiSQL基准测试中实现了最先进的结果,分别将先前的工作提升了1.2%和2.4%。
MeRL自动学习辅助奖励函数,而无需使用任何专家演示(例如,ground-truth计划),使其更广泛适用并且与先前的奖励学习方法不同。
高级概述:
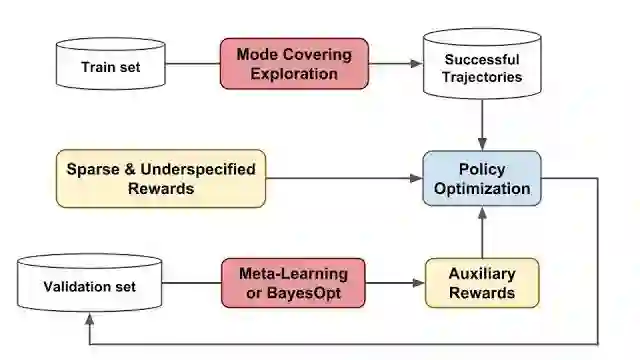
元奖励学习(MeRL)
MeRL在处理不明确奖励方面发现,虚假轨迹和实现意外成功的程序,对智能体的泛化性能不利。
例如,智能体可能解决上述迷宫问题的特定实例。但是,如果它在训练期间学会执行虚假动作,提供看不见的指令则可能导致其失败。
为了缓解这个问题,MeRL优化了更精确的辅助奖励函数,可以根据行动轨迹的特征区分意外、或非意外的成功。
通过元学习最大化训练的智能体在保持验证集上的表现,来优化辅助奖励。
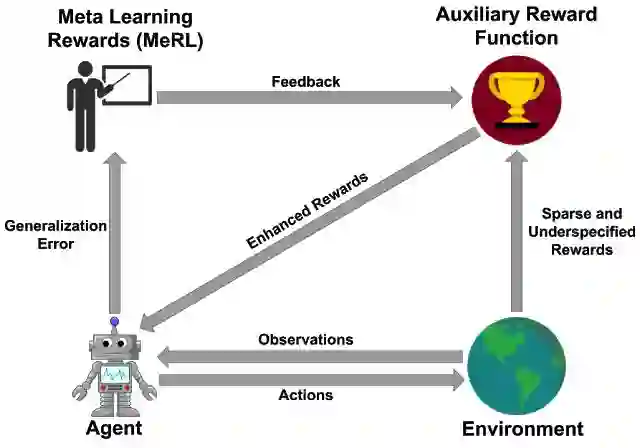
从稀疏奖励中学习
要从稀疏的奖励中学习,有效的探索如何找到一组成功轨迹,至关重要。
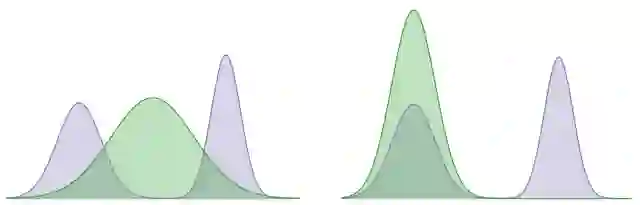
论文通过利用Kullback-Leibler(KL)发散的两个方向来解决这一挑战,这是一种衡量两种不容概率分布的方法。
在下面的示例中,使用KL散度来最小化固定双峰(阴影紫色)和学习高斯(阴影绿色)分布之间的差异,这可以分别代表智能体的最优策略分布,和学习的策略的分布。
KL对象的一个学习方向,试图覆盖两种模式的分布,而其他目标学习的分布,则在寻求特定模式(即,它更喜欢A模式而不是B模式)。
我们的方法利用模式覆盖了KL关注多个峰值以收集多样化的成功轨迹和模式的倾向,寻求KL在轨迹之间的隐含偏好,以学习强有力的策略。
结论
设计区分最佳和次优行为的奖励函数对于将RL应用于实际应用程序至关重要。
这项研究在没有任何人为监督的情况下向奖励函数建模方向迈出了一小步。
在未来的工作中,我们希望从自动学习密集奖励函数的角度解决RL中的信用分配问题。
致谢
这项研究是与Chen Liang和Dale Schuurmans合作完成的。 我们感谢Chelsea Finn和Kelvin Guu对该论文的评论。
参考链接:
https://ai.googleblog.com/2019/02/learning-to-generalize-from-sparse-and.html
更多阅读
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。




