中文情感分析 (Sentiment Analysis) 的难点在哪?现在做得比较好的有哪几家?
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要25分钟
跟随小博主,每天进步一丢丢


链接:
假设分析的对象是iphone5s的手机评论。从京东、亚马逊或者中关村都可以找到这款手机的评论。大致都如图所示。

情感分析(Sentiment Analysis)
第一步,就是确定一个词是积极还是消极,是主观还是客观。这一步主要依靠词典。
英文已经有伟大词典资源:SentiWordNet. 无论积极消极、主观客观,还有词语的情感强度值都一并拿下。
但在中文领域,判断积极和消极已经有不少词典资源,如Hownet,NTUSD但用过这些词典就知道,效果实在是不咋滴(最近还发现了大连理工发布的情感词汇本体库,不过没用过,不好评价)。中文这方面的开源真心不够英文的做得细致有效。而中文识别主客观,那真的是不能直视。
中文领域难度在于:词典资源质量不高,不细致。另外缺乏主客观词典。
有词典的时候,好办。直接去匹配看一个句子有什么词典里面的词,然后加总就可以计算出句子的情感分值。
但由于不同领域有不同的情感词,比如看上面的例子,“蓝屏”这个词一般不会出现在情感词典之中,但这个词明显表达了不满的情绪。因此需要另外根据具体领域构建针对性的情感词典。
如果不那么麻烦,就可以用有监督的机器学习方法。把一堆评论扔到一个算法里面训练,训练得到分类器之后就可以把评论分成积极消极、主观客观了。
分成积极和消极也好办,还是上面那个例子。5颗星的评论一般来说是积极的,1到2颗星的评论一般是消极的,这样就可以不用人工标注,直接进行训练。但主客观就不行了,一般主客观还是需要人来判断。加上中文主客观词典不给力,这就让机器学习判断主客观更为困难。
中文领域的难度:还是词典太差。还有就是用机器学习方法判断主客观非常麻烦,一般需要人工标注。
另外中文也有找到过资源,比如这个用Python编写的类库:SnowNLP. 就可以计算一句话的积极和消极情感值。但我没用过,具体效果不清楚。
这一步需要从评论中找出产品的属性。拿手机来说,屏幕、电池、售后等都是它的属性。到这一步就要看评论是如何评价这些属性的。比如说“屏幕不错”,这就是积极的。“电池一天都不够就用完了,坑爹啊”,这就是消极的,而且强度很大。
这就需要在情感分析的基础上,先挖掘出产品的属性,再分析对应属性的情感。
分析完每一条评论的所有属性的情感后,就可以汇总起来,形成消费者对一款产品各个部分的评价。
接下来还可以对比不同产品的评价,并且可视化出来。如图。
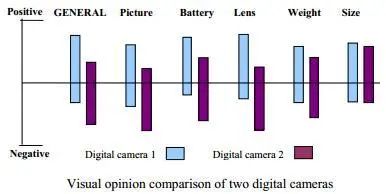
中文这个领域的研究其实很完善了,技术也很成熟。但需要完善前期情感分析的准确度。
链接:
文档粒度(document level):文档级情感分类是指为观点型文档标记整体的情感倾向/极性,即确定文档整体上传达的是积极的还是消极的观点。因此,这是一个二元分类任务,也可以形式化为回归任务,例如为文档按 1 到 5 星评级。一些研究者也将其看成一个五类分类任务。
句子粒度(sentence level):语句级情感分类用来标定单句中的表达情感。正如之前所讨论的,句子的情感可以用主观性分类和极性分类来推断,前者将句子分为主观或客观的,而后者则判定主观句子表示消极或积极的情感。在现有的深度学习模型中,句子情感分类通常会形成一个联合的三类别分类问题,即预测句子为积极、中立或消极。
短语粒度(aspect level):也称为主题粒度,每一个短语代表了一个主题。与文档级和语句级的情感分类不同,aspect level 情感分类同时考虑了情感信息和主题信息(情感一般都会有一个主题)。给定一个句子和主题特征,aspect level 情感分类可以推断出句子在主题特征的情感极性/倾向。例如,句子「the screen is very clear but the battery life is too short.」中,如果主题特征是「screen」,则情感是积极的,如果主题特征是「battery life」,则情感是消极的。
深度学习模型
文档/句子粒度:Kim等人(2013) 提出的CNN文本分类工作,成为句子级情感分类任务的重要baseline之一;

文档/句子粒度:基本的lstm模型加上pooling策略构成分类模型,是通常用来做情感分析的方法;
短语粒度:Tang等人(2015) 使用两种不同的rnn网络,结合文本和主题进行情感分析;
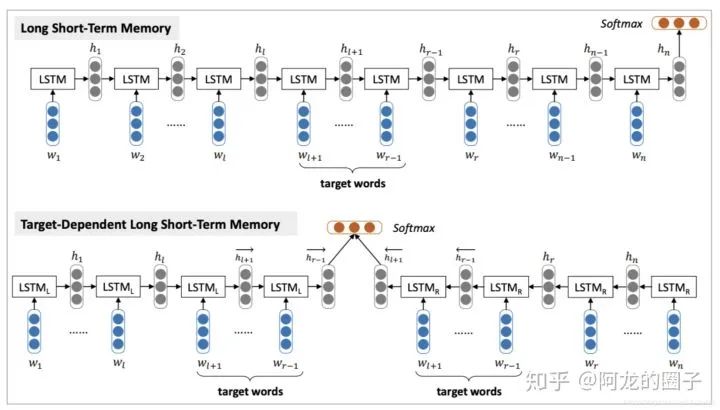
短语粒度:Tang等人(2016) 结合memory-network,解决target-dedependent问题,这里的target理解为前面提过的aspect;
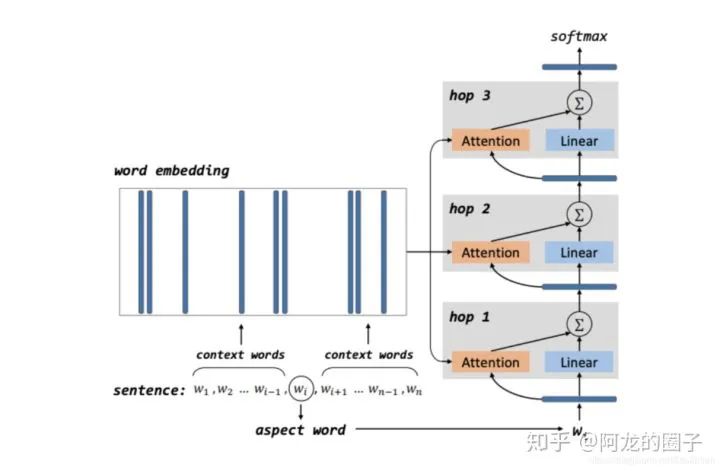
短语粒度:Chen等人(2017) 分别使用位置权重记忆和层叠attention的复合机制,建模target词和文本间的相互交互关系,以解决短语级情感分类问题;
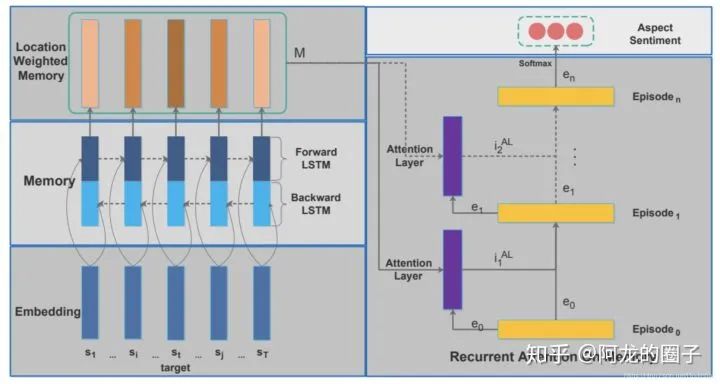
短语粒度:Schmitt1等人(2018) 将aspect和polarity结合在一起进行分类任务训练,得到情感分析的模型;
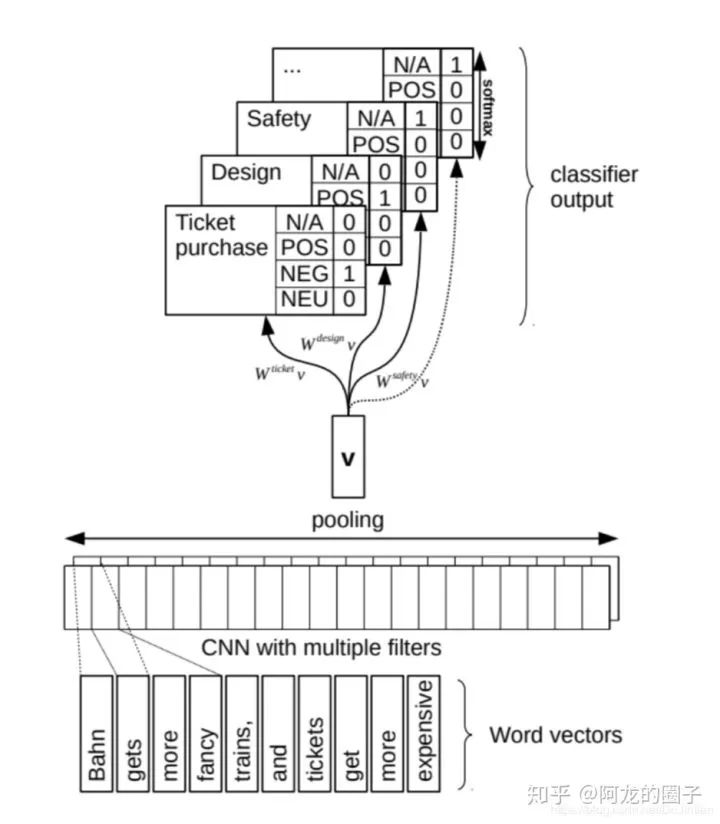
现在流行模型:大规模语料预训练(词向量/Elmo/GPT/Bert)+ 深度学习分类器(lstm/cnn/transformer),一个很好的示例见AI Challenger 2018:细粒度用户评论情感分类冠军思路总结。
相关数据
情感词典
词性字典1词性字典2
大连理工大学中文情感词汇本体库
清华大学李军中文褒贬义词典
知网情感词典
情感数据集
15 Free Sentiment Analysis Datasets for Machine Learning
大众点评细粒度用户评论情感数据集
汽车行业用户观点主题及情感识别
电商评论情感数据
酒店评论语料
SemEval-2014 Task 4数据集
Citysearch corpus 餐馆评论数据
NLPCC2014评估任务2_基于深度学习的情感分类
NLPCC2013评估任务_中文微博观点要素抽取
NLPCC2013评估任务_中文微博情绪识别
NLPCC2013评估任务_跨领域情感分类
NLPCC2012评估任务_面向中文微博的情感分析
康奈尔大学影评数据集
其他资源
Sentiment Analysis with LSTMs in Tensorflow
Sentiment analysis on tweets using Naive Bayes, SVM, CNN, LSTM, etc.
Chinese Shopping Reviews sentiment analysis
AI Challenger 2018:细粒度用户评论情感分类冠军思路总结
文献资料
文本情感分析综述(腾讯语义团队)
Deep learning for sentiment analysis: A survey
情感分析资源大全
Tang D, Qin B, Liu T. Aspect level sentiment classification with deep memory network[J]. arXiv preprint arXiv:1605.08900, 2016.
Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
链接:
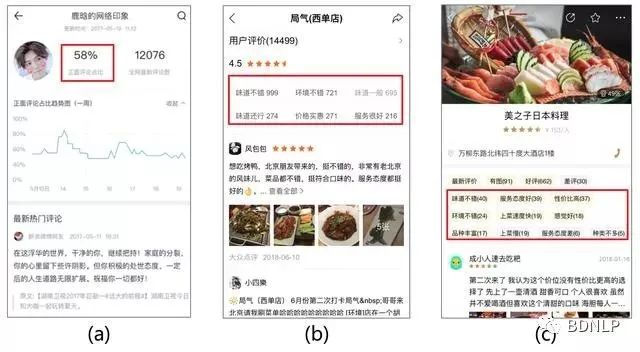
然后,通过情感分类技术确定其观点的情感倾向。
百度Senta是怎么解决这些问题并形成核心技术的?
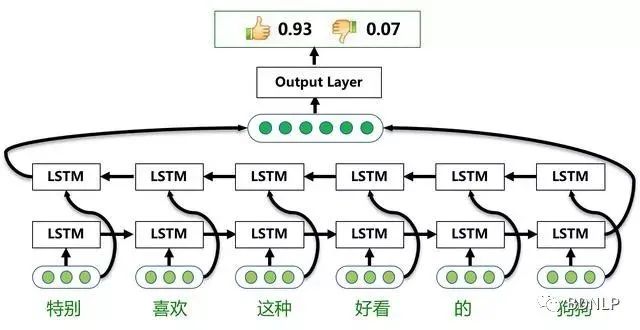
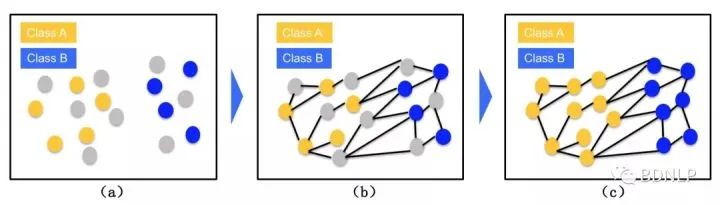
Senta系统( https://github.com/baidu/Senta )
链接:
比如 - ChineseLDC.Org
国内研究使用授权费 5000 RMB
国外研究使用授权费 35000 RMB
(不过这个是研究说话语气的emotion)
Product Catalog
收费是$89.95美元(税前)
国内COAE和日本举办的NTCIR的评测不错。楼主可以参考。
现在的sentiment analysis比较倾向于machine learning的方法。语料库越大才能搞出来好的性能。算法什么的都可以通用。
信息分类与情感发现
http://aclweb.org/anthology/P/P11/P11-1033.pdf
http://aclweb.org/anthology//P/P09/P09-1027.pdf
链接:
链接:
链接:






