CVPR 2020 | 京东AI研究院对视觉与语言的思考:从自洽、交互到共生
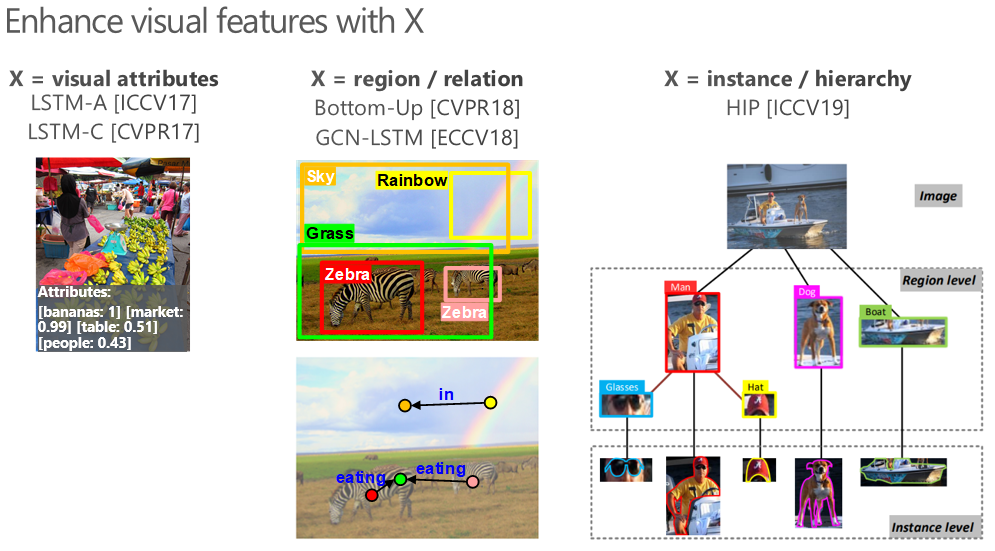
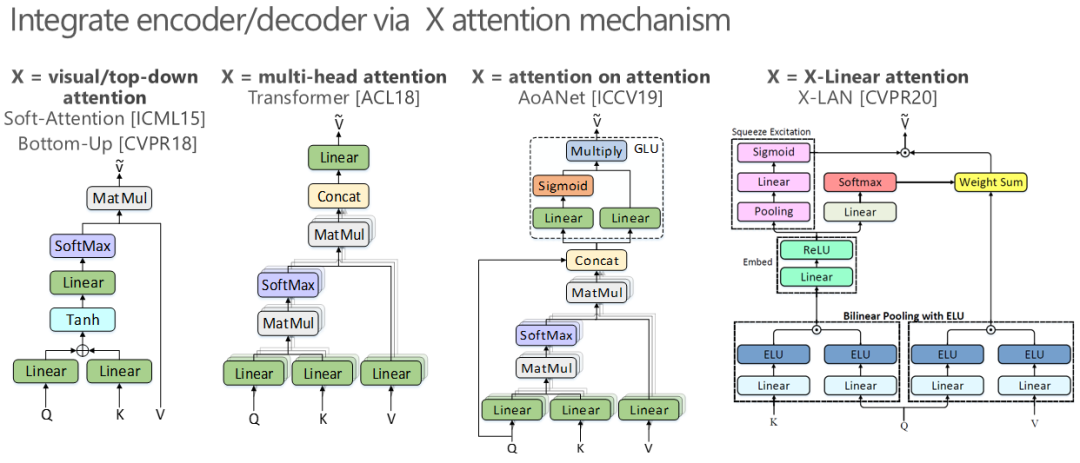
纵观视觉与语言在这六年间的飞速发展史,它就仿佛是两种不同文化(计算机视觉与自然语言处理)的碰撞与交融。这里每一种文化最初的进化都是自洽的,即独立地演化形成一套完备的视觉理解或语言建模体系;演化至今,我们当前所迎来的则是两种文化间的交互,自此视觉理解和语言建模不再是简单串联的两个模块,而是通过互相的信息传递成为共同促进的一个整体;对于视觉与语言的未来,则一定是聚焦于两者更为本质和紧密的共生,它所渴望的,将是挣脱开数据标注的桎梏,在海量的弱监督甚至于无监督数据上找寻两者间最为本质的联系,并以之为起源,如「道生一,一生二,二生三,三生万物」一般,赋予模型在各种视觉与语言任务上的生命力。




登录查看更多
相关内容
【CVPR 2019 | tutorial】视觉识别Visual Recognition and Beyond,Facebook|Ross Girshick,Justin Johnson(李飞飞高徒)
专知会员服务
29+阅读 · 2019年6月16日
Arxiv
16+阅读 · 2019年12月16日
Arxiv
3+阅读 · 2018年5月31日
Arxiv
7+阅读 · 2018年5月24日




相关VIP内容
【CVPR 2019 | tutorial】视觉识别Visual Recognition and Beyond,Facebook|Ross Girshick,Justin Johnson(李飞飞高徒)
专知会员服务
29+阅读 · 2019年6月16日
相关资讯
相关论文
Arxiv
16+阅读 · 2019年12月16日
Arxiv
3+阅读 · 2018年5月31日
Arxiv
7+阅读 · 2018年5月24日