2018年最全的推荐系统干货(ECCV、CVPR、AAAI、ICML)
最近总有几位关注者希望我们可以分享一些“推荐系统”类的干货,最近正好一不小心看到一篇比较好的博主写的推送,在此我通过自己理解和该博主的内容,为大家带来一次推荐系统的分享!
前言
随着电子商务的发展,网络购物成为一种趋势,当你打开某个购物网站比如淘宝、京东的时候,会看到很多给你推荐的产品,你是否觉得这些推荐的产品都是你似曾相识或者正好需要的呢。这个就是现在电子商务里面的推荐系统,向客户提供商品建议和信息,模拟销售人员完成导购的过程。
推荐系统是一个相当火热的研究方向,在工业界和学术界都得到了大家的广泛关注。希望通过下面的介绍,总结一些关于推荐系统领域相关的会议、知名学者,以及做科研常用的数据集、代码库等,希望能够帮助想入门推荐系统的童鞋们提供一个参考,希望能够尽快上手推荐系统,进而更好更快的深入科研也好、工程也罢。
那下面开始正式介绍,过程会给大家推荐一些比较好的会议、文章、作者等,记得收藏记录下来。
介绍
什么是推荐系统呢?刚刚前面也简单的介绍了下,在维基百科这样解释:推荐系统属于资讯过滤的一种应用。推荐系统能够将可能受喜好的资讯或实物(例如:电影、电视节目、音乐、书籍、新闻、图片、网页)推荐给使用者。
推荐系统首先收集用户的历史行为数据,然后通过预处理的方法得到用户-评价矩阵,再利用机器学习领域中相关推荐技术形成对用户的个性化推荐。有的推荐系统还搜集用户对推荐结果的反馈,并根据实际的反馈信息实时调整推荐策略,产生更符合用户需求的推荐结果。
推荐系统的作用:
将网站的浏览者转为购买者或者潜在购买者(购物车);
提高购物网站的交叉销售能力和成交转化率;
提高客户对网站的忠诚度和帮助用户迅速找到产品。
推荐系统的表现形式:
Browsing:客户提出对特定商品的查询要求,推荐系统根据查询要求返回高质量的推荐;
Similar Item:推荐系统根据客户购物篮中的商品和客户可能感兴趣的商品推荐类似的商品;
Email:推荐系统通过电子邮件的方式通知客户可能感兴趣的商品信息;
Text Comments:推荐系统向客户提供其他客户对相应产品的评论信息;
Average Rating:推荐系统向客户提供其他客户对相应产品的等级评价;
Top-N:推荐系统根据客户的喜好向客户推荐最可能吸引客户的N件产品;
Ordered Search Results:推荐系统列出所有的搜索结果,并将搜索结果按照客户的兴趣降序排列。
推荐技术分类:
基于用户统计信息的推荐;
基于其他客户对该产品的平均评价,这种推荐系统独立于客户,所有的客户得到的推荐都是相同的(Non-PersonalizedRecommendation);
基于产品的属性特征(Attributed-Based Recommendation);
根据客户感兴趣的产品推荐相关的产品(Item-to-ItemCorrelation);
协同过滤,推荐系统根据客户与其他已经购买了商品的客户之间的相关性进行推荐(People-to-PeopleCorrelation)。
相关会议
对于推荐系统领域,直接相关的会议不多,但由于推荐系统会涉及到数据挖掘、机器学习等方面的知识,并且推荐系统作为数据挖掘和机器学习的重要应用之一,同时推荐系统往更大的领域靠拢的话也属于人工智能的范畴,因此很多做推荐的学者把目光也瞄向了数据挖掘、机器学习和人工智能方面的会议。所以,如果想关注推荐系统的前沿,我们需要不仅关注推荐系统年会,还需要关注其他与推荐挂钩的会议。
与推荐系统直接相关的会议
RecSys -The ACM Conference Series on Recommender Systems.
数据挖掘相关的会议
SIGKDD - The ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
WSDM - The International Conference on Web Search and Data Mining.
ICDM - The IEEE International Conference on Data Mining.
SDM -TheSIAM International Conference on Data Mining.
机器学习相关的会议
ICML - The International Conference on Machine Learning.
信息检索相关的会议
SIGIR - The ACM International Conference on Research and Development in Information Retrieval
数据库相关的会议
CIKM - The ACM International Conference on Information and Knowledge Management.
Web相关的会议
WWW - The International World Wide Web Conference.
人工智能相关的会议
AAAI - The National Conference of the American Association for Artificial Intelligence.
IJCAI - The International Joint Conference on Artificial Intelligence.
推荐系统的数据分类:
Explicit(显式):能准确的反应用户对物品的真实喜好,但需要用户付出额外的代价。如:用户收藏、用户评价。
Implicit(隐式):通过一些分析和处理,才能反映用户的喜好。如:用户浏览、用户页面停留时间、访问次数。
推荐系统算法介绍:
谈到推荐系统,当然离不开它的核心 —— 推荐算法。推荐算法最早在1992年就提出来了,但是发展起来是最近这些年的事情,因为互联网的爆发,有了更大的数据量可以供我们使用,推荐算法才有了很大的用武之地。
下面我们分别来介绍几种常用的推荐算法:
基于用户统计信息的推荐:
这是最为简单的一种推荐算法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。
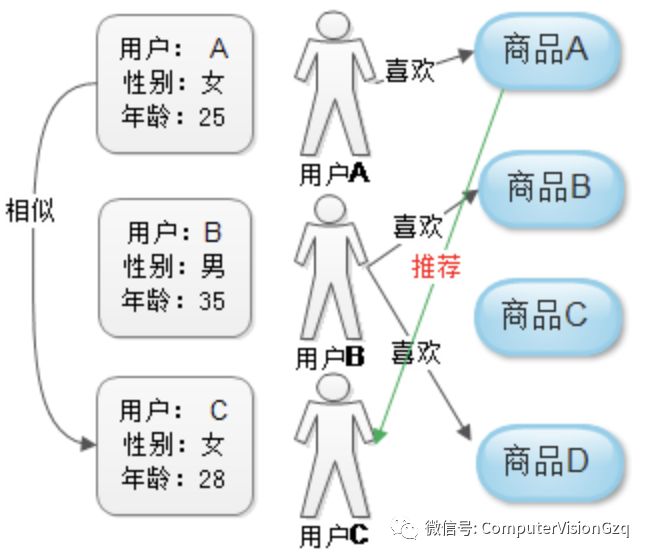
系统首先根据用户的类型,比如按照年龄、性别、兴趣爱好等信息进行分类。根据用户的这些特点计算形似度和匹配度。如图,发现用户A和B的性别一样,年龄段相似,于是推荐A喜欢的商品给C。
优点:
不需要历史数据,没有冷启动问题;
不依赖于物品的属性,因此其他领域的问题都可无缝接入。
缺点:
算法比较粗糙,效果很难令人满意,只适合简单的推荐。
相关学者
1、Yehuda Koren
个人主页:Koren's HomePage
主要贡献:Netflix Prize的冠军队成员,是推荐系统领域的大神级人物,现就职于雅虎
代表文献:Matrix Factorization Techniques For Recommender Systems
2、Hao Ma
个人主页:HaoMa's HomePage
主要贡献:社会化推荐领域的大牛,提出了许多基于社会化推荐的有效算法,现就职于微软
代表文献:SoRec: Social Recommendation Using Probabilistic Matrix Factorization
3、郭贵冰
个人主页:Guibing Guo's HomePage
主要贡献:国内推荐系统大牛,创办了推荐系统开源项目LibRec
代表文献:TrustSVD: Collaborative Filtering with Both the Explicit and Implicit Influence of User Trust and of Item Ratings
4、Hao Wang
个人主页:HaoWang's HomePage
主要贡献:擅长运用深度学习技术提高推荐系统性能
代表文献:Collaborative deep learning for recommender systems
5、何向南
个人主页:Xiangnan He's Homepage
主要贡献:运用深度学习技术提高推荐系统性能
代表文献:Neural Collaborative Filtering
6、Robin Burke
个人主页:rburke's HomePage
主要贡献:混合推荐方向的大牛
代表文献:Hybrid recommender systems: Survey and experiments
7、项亮
主要贡献:国内推荐系统领域中理论与实践并重的专家,Netflix Prize第二名
代表文献:《推荐系统实践》。
8、石川
个人主页:shichuan's HomePage
主要贡献:研究方向为异质信息网络上的推荐,提出了加权的异质信息相似度计算等
代表文献:Semantic Path based Personalized Recommendation on Weighted Heterogeneous Information Networks
基于内容的推荐(Content-basedRecommendation)
基于内容的推荐是建立在产品的信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。
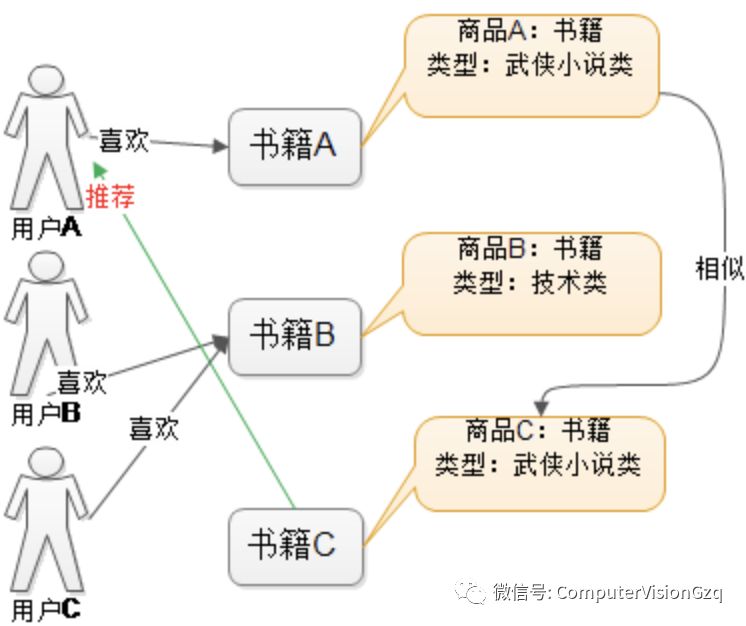
系统首先对商品书籍的属性进行建模,图中用类型作为属性。在实际应用中,只根据类型显然过于粗糙,还需要考虑其他信息。通过相似度计算,发现书籍A和C相似度较高,因为他们都属于武侠小说类。系统还会发现用户A喜欢书籍A,由此得出结论,用户A可能对书籍C也感兴趣。于是将书籍C推荐给A。接下来,举一个明了的例子:
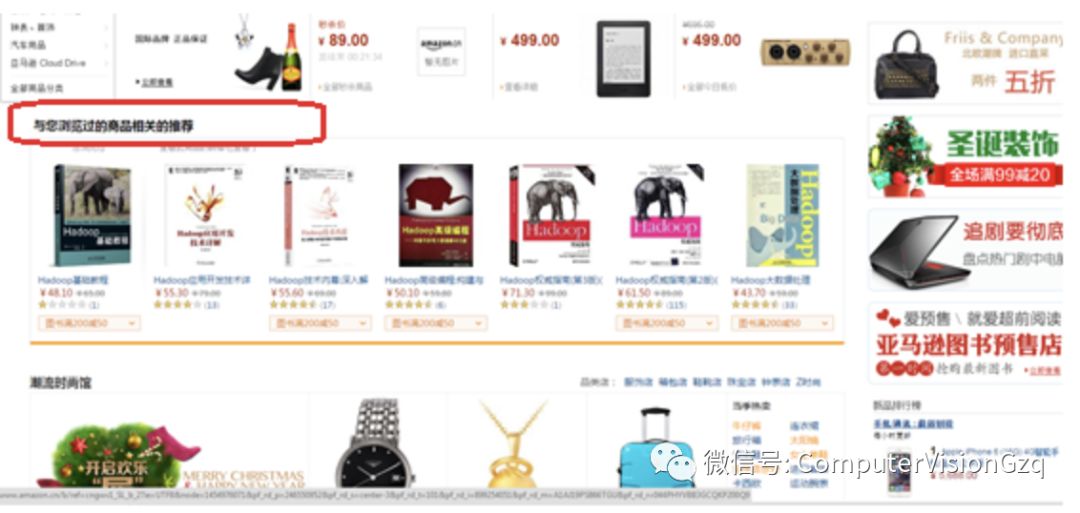
下面是亚马逊中国的一个例子,未登录用户浏览了关于Hadoop的书籍,于是在首页会出现如下相关产品的推荐:
优点:
对用户兴趣可以很好的建模,并通过对商品和用户添加标签,可以获得更好的精确度;
能为具有特殊兴趣爱好的用户进行推荐。
缺点:
物品的属性有限,难以区分商品信息的品质;
物品相似度的衡量标准只考虑到了物品本身,有一定的片面性;
不能为用户发现新的感兴趣的产品。
相关文章
Burke et al. HybridRecommender Systems: Survey and Experiments. USER MODEL USER-ADAP,2002.
Adomavicius et al. Toward thenext generation of recommender systems: A survey of the state-of-the-art andpossible extensions. IEEE TKDE, 2005.
Su et al. A survey ofcollaborative filtering techniques. Advances in artificialintelligence, 2009.
Cacheda et al. Comparison ofcollaborative filtering algorithms: Limitations of current techniques andproposals for scalable, high-performance recommender systems. ACMTWEB, 2011.
Zhang et al. Tag-awarerecommender systems: a state-of-the-art survey. J COMPUT SCITECHNOL, 2011.
Tang et al. Socialrecommendation: a review. SNAM, 2013.
Yang et al. A survey ofcollaborative filtering based social recommender systems. COMPUTCOMMUN, 2014.
Shi et al. Collaborativefiltering beyond the user-item matrix: A survey of the state of the art andfuture challenges. ACM COMPUT SURV, 2014.
Chen et al. Recommendersystems based on user reviews: the state of the art. USER MODELUSER-ADAP, 2015.
Xu et al. Social networkingmeets recommender systems: survey. Int.J.Social Network Mining,2015.
Yu et al. A survey ofpoint-of-interest recommendation in location-based social networks. InWorkshops at AAAI, 2015.
Zhang et al. Deep learningbased recommender system: A survey and new perspectives. arXiv,2017.
Singhal et al. Use of DeepLearning in Modern Recommendation System: A Summary of Recent Works. arXiv,2017.
Zhang et al. ExplainableRecommendation: A Survey and New Perspectives. arXiv, 2018.
协同过滤推荐(CollaborativeFiltering Recommendation)
背景:协同过滤的场景是这样的:要为某用户推荐他真正感兴趣的内容/商品,首先要找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给该用户。协同过滤就是利用这个思想,基于其他用户对某一个内容的评价来向目标客户进行推荐。
基于协同过滤的推荐系统可以说是从用户的角度来进行相应的自动的推荐,即用户获得的推荐是系统从购买模式或浏览行为等隐式获得的。
比较:这里你是否觉得协同过滤推荐和基于用户统计信息的推荐以及基于内容的推荐有很多相似之处呢?下面我们先来比较一下协同过滤推荐和上述两种推荐的区别。
协同过滤推荐 VS 基于用户统计信息推荐
基于用户的协同过滤推荐机制和基于用户统计信息推荐机制都是计算用户的相似度,并基于“邻居”用户群计算推荐,但它们所不同的是如何计算用户的相似度,基于用户统计信息只考虑用户本身的特征,而基于用户的协同过滤机制是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的兴趣爱好。
系统过滤推荐 VS 基于内容的推荐
基于项目的协同过滤推荐和基于内容的推荐其实都是基于物品相似度预测推荐,只是相似度计算的方法不一样,前者是从用户历史的偏好推断,而后者是基于物品本身的属性特征信息。
描述:协同过滤算法,顾名思义就是指用户可以齐心协力,通过不断的和网站互动,是自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
协同过滤算法主要有两种,一种是基于用户的协同过滤算法(UserCF),另一种是基于物品的协同过滤算法(ItemCF)。
基于用户的协同过滤算法:
通过计算用户对商品评分之间的相似性,搜索目标用户的最近邻居,然后根据最近邻居的评分向目标用户产生推荐。
1. 相似度计算
常用的相似度计算方法有欧式距离、余弦距离算法、杰卡德相似性算法,这里主要介绍余弦距离算法。
余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)。
几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。
在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
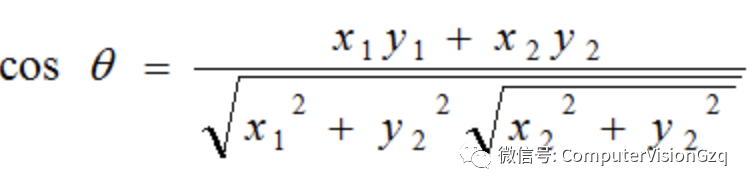
对于两个n维a(x11,x12,…,x1n)和b(x21,x22,…,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度
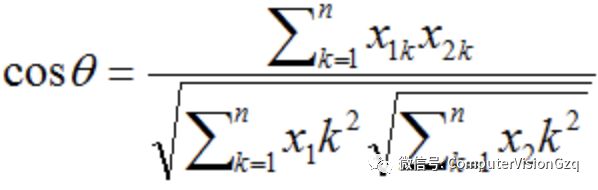
定义:
推荐系统中的数据源D=(U,I,R),其中U ={User1,User2,User3,…,Useri}是用户的基本集合,I = {Item1,Item2,…,Itemj}是项目集合;i*j阶矩阵R是基本用户对各项目的评分矩阵,第m行第n列的元素Rmn代表用户m对项目n的评分。
余弦相似性:
应用到推荐系统的场景是这样的:两个项目i和j被当作两个n维的向量a和b。每个用户的评分都可以看作为n维空间上的向量,如果用户对产品没有进行评分,则将用户对该项目的评分设为0。用户间的相似性通过向量间的余弦夹角度量:
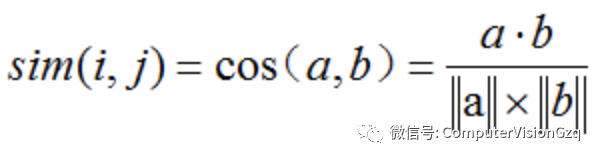
其中,分子为两个用户评分向量的内积,分母为两个用户向量模的乘积。
修正余弦相似性
余弦相似性未考虑到用户评分尺度问题,如在评分区间[1,5]的情况下,对用户甲来说评分3以上就是自己喜欢的,而对于用户乙,评分4以上才是自己喜欢的。通过减去用户对项目的平均评分,修正的余弦相似性度量方法改善了以上问题。
用户a和b共同评分过的项目集合用来表示, = (和分别表示用户a和用户b评分过的项目的集合,结果是它们的交集)。因此,用户a和b的相似性:
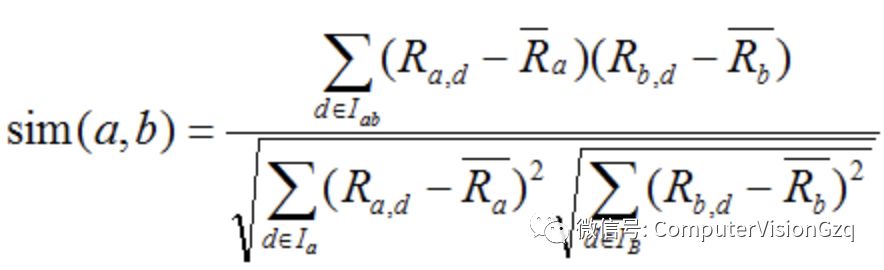
表示用户a对项目d的评分,和分别表示用户a和用户b对所有商品的平均评分。
查找最近邻居
通过上面对目标用户相似度的计算,我们可以找到与目标用户最相似的N个邻居的集合。
选择相似度大于设定阈值的用户;
选择相似度最大的前 N个用户;
选择相似度大于预定阈值的 N个用户。
产生推荐商品
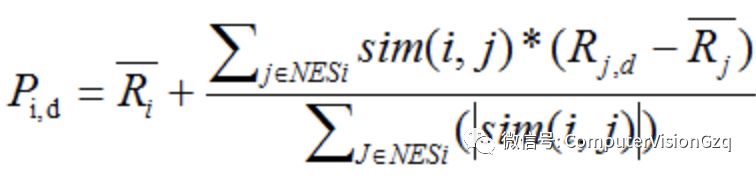
其中sim(i,j)表示用户i与用户j之间的相似性,表示最近邻居用户j对项目d的评分,和分别表示用户i和用户j的平均评分,实质是在用户的最近邻居集NESi中查找用户,并将目标用户与查找到的用户的相似度的值作为权值,然后将邻居用户对该项目的评分与此邻居用户的所有评分的差值进行加权平均。
通过上述方法预测出目标用户对未评价项目的评分,然后选择预测评分最高的TOP-N项推荐给目标用户。
代码与工具
1、LibRec
java版本开源推荐系统,包含了70多种经典的推荐算法。
2、Surprise
python版本开源推荐系统,包含了多种经典的推荐算法。
3、LibMF
c++版本开源推荐系统,主要实现了基于矩阵分解的推荐算法。
4、Recommender-System
python版本开源推荐系统,包含了多种经典的推荐算法。
5、Neural Collaborative Filtering
python实现神经协同过滤推荐算法。
根据前面用户计算的相似度和寻找最近邻居来计算推荐度,这里举例图示说明。
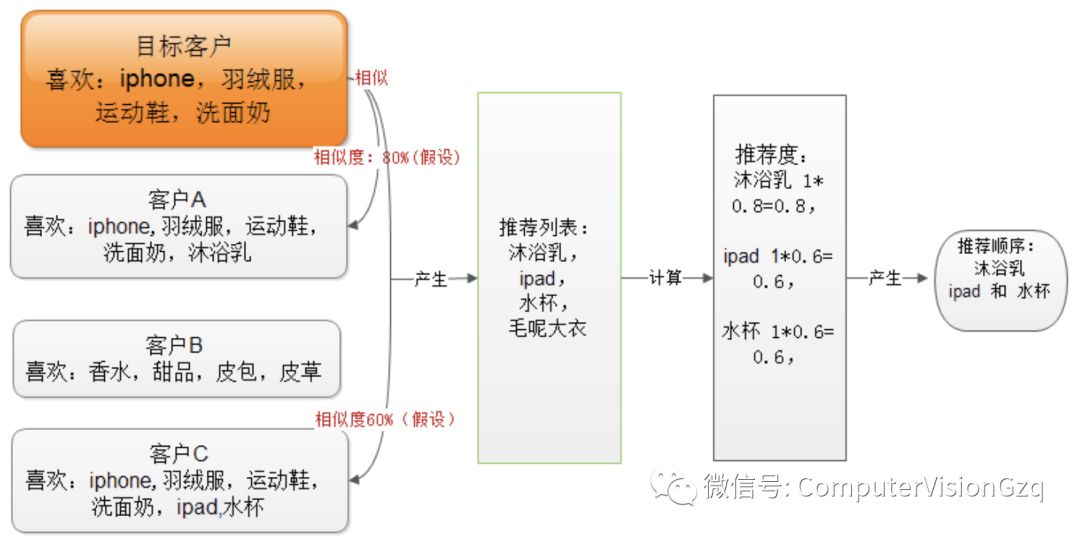
示例1:
下面是新浪网新闻热点推荐,用户在新浪网浏览了一系列的财经类新闻,根据用户相似性,即两个用户有相同的爱好做出的推荐。

基于项目的协同过滤算法:
基于项目协同过滤在于透过计算项目之间的相似性来代替使用者之间的相似性。所建立的一个基本的假设:”能够引起使用者兴趣的项目,必定与其之前评分高的项目相似”。
基于项目的协同过滤算法的关键步骤仍然是计算项目之间的相似性并选出最相似的项目,这一点与基于用户的协同过滤类似。
计算两个项目i和j之间相似性的基本思想是首先将对两个项目共同评分的用户提取出来,并将每个项目获得的评分看作是n维用户空间的向量,再通过相似性度量公式计算两者之间的相似性。
分离出相似的项目之后,下一步就要为目标项目预测评分,通过计算用户u对与项目i相似的项目集合的总评价分值来计算用户u对项目i的预期。
这里我们主要来关注一下基于用户的协同过滤和基于项目的协同过滤算法的区别:
基于用户的协同过滤是推荐用户所在兴趣小组中的热点,更注重社会化;比如:如上面示例1所示,新浪网给目标客户推荐其他有相同或相似兴趣爱好的人关注的新闻,这样就保证了新闻门户网站需要的时效性,给用户最新最及时最感兴趣的新闻信息。
基于项目的协同过滤算法则是根据用户历史行为推荐相似物品,更注重个性化。比如购物网站,用户的兴趣爱好一般比较固定,网站一般是给目标用户推荐他所感兴趣领域的产品。可参考示例2.
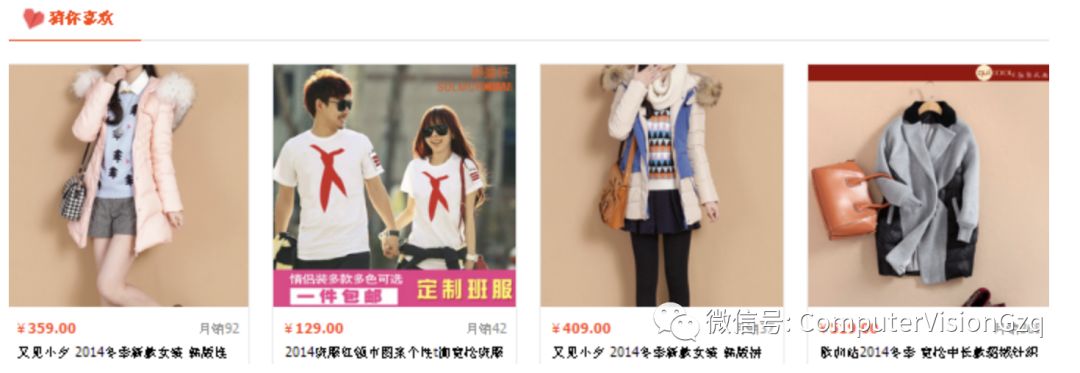
示例2:
下面是淘宝网站的例子,“猜你喜欢”就是将相同类型的东西推荐给用户。
再来看京东网站的例子。用户浏览书籍《Hadoop实战》

然后下面就会产生“热门推荐”,即邻居项目的产生。

优点:
能够过滤难以进行机器自动内容分析的信息,如艺术品,音乐等;
共享其他人的经验,避免了内容分析的不完全和不精确,并且能够基于一些复杂的,难以表述的概念(如信息质量、个人品味)进行过滤;
有推荐新信息的能力。可以发现内容上完全不相似的信息,用户对推荐信息的内容事先是预料不到的。这也是协同过滤和基于内容的过滤一个较大的差别,基于内容的过滤推荐很多都是用户本来就熟悉的内容,而协同过滤可以发现用户潜在的但自己尚未发现的兴趣偏好;
能够有效的使用其他相似用户的反馈信息,较少用户的反馈量,加快个性化学习的速度。
不足:
稀疏性问题。大多数用户只评价了部分项目,这样导致用户-评分矩阵十分稀疏,这样不利于推荐系统为用户推荐信息;
冷启动问题。新产品没有任何用户的评分,在协同过滤中是无法推荐的。新用户没有历史信息,也是无法推荐的;
同一性问题。对于那些内容相同但是名称不同的项目,协同过滤是无法发现它们内在的联系。
基于关联规则的推荐(AssociationRule-based Recommendation)
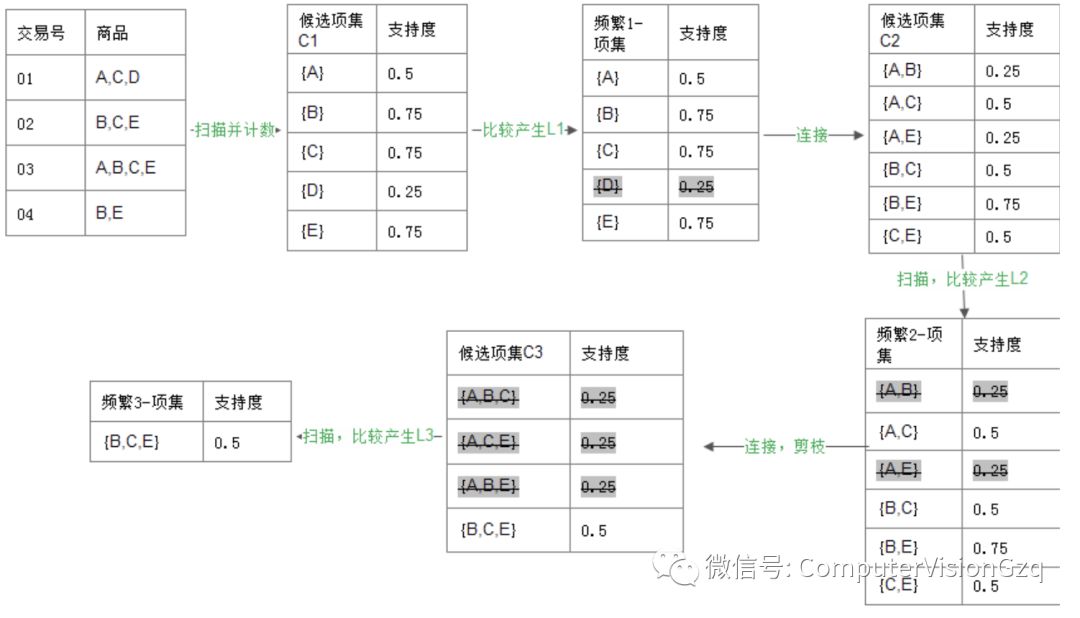
描述:关联规则算法首先由Agrawal和Swami提出,最早的成型为经典的Apriori算法。它的基本思想是:使用一种称作逐层搜索的迭代方法,k项集用于探索(k+1)项集。首先,通过扫描事务(交易)记录,找出所有的频繁1项集,该集合记做L1,然后利用L1找频繁2项集的集合L2,L2找L3,如此下去,直到不能再找到任何频繁k项集。最后再在所有的频繁集中找出强规则,即产生用户感兴趣的关联规则。
关于这个算法有一个非常有名的故事:"尿布和啤酒":美国的妇女们经常会嘱咐她们的丈夫下班后为孩子买尿布,而丈夫在买完尿布后又要顺手买回自己爱喝的啤酒,因此啤酒和尿布在一起被购买的机会很多。这个举措使尿布和啤酒的销量双双增加,并一直为众商家所津津乐道。
概念介绍:
支持度:S(Support) 事物包含A B = P(x),表示事件x出现的概率;
置信度:C(Confidence) 在A发生的事件中同时发生B的概率 P(AB)/P(A) = P(B|A);
频繁项集:(Frequent Itemset)支持度大于等于特定的最小支持度(MinimumSupport/minsup)的项集。表示为L k。
连接步:L(k-1) 与其自身进行连接,产生候选项集 C(k) 。 L(k-1) 中某个元素与其中另一个元素可以执行连接操作的前提是它们中有(k-2) 个项是相同的。也就是只有一个项是不同的。如:项集 {I1,I2} 与 {I1,I5} 连接之后产生的项集是 {I1,I2,I5} ,而项集 {I1,I2} 与 {I3,I4}不能进行连接操作。
剪枝步:C k是L k的超集,也就是说,C k的成员可能是也可能不是频繁的。通过扫描所有的事务(交易),确定C k中每个候选的计数,判断是否小于最小支持度计数,如果不是,则认为该候选是频繁的。为了压缩Ck,可以利用Apriori性质:任一频繁项集的所有非空子集也必须是频繁的,反之,如果某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其从C k中删除。
下面我们通过一个例子来解释:
Apriori算法的缺点:
由频繁k-1项集进行自连接生成的候选频繁k项集数量巨大;
在验证候选频繁k项集的时候需要对整个数据库进行扫描,非常耗时。
Apriori算法的优化 ——Fp-tree 算法
这里简单介绍下优化思想:
以树形的形式来展示、表达数据的形态;可以理解为水在不同河流分支的流动过程;步骤如下:
扫描原始项目集;
排列数据;
创建ROOT节点;
按照排列的数据进行元素的流动;
节点+1;
优点:
能发现新兴趣点;
不要领域知识。
不足:
算法的第一步关联规则的发现最为关键且最耗时,是算法的瓶颈,但可以离线进行;
其次,商品名称的同义性问题也是关联规则的一个难点。
其他推荐算法介绍:
除了上面比较详细介绍的集中推荐算法,这里再简单介绍一下其他几种算法。
基于效用推荐
基于效用的推荐(Utility-basedRecommendation)是建立在对用户使用项目的效用情况上计算的,其核心问题是怎么样为每一个用户去创建一个效用函数,因此,用户资料模型很大程度上是由系统所采用的效用函数决定的。基于效用推荐的好处是它能把非产品的属性,如提供商的可靠性(VendorReliability)和产品的可得性(ProductAvailability)等考虑到效用计算中。
基于知识推荐
基于知识的推荐(Knowledge-basedRecommendation)在某种程度是可以看成是一种推理(Inference)技术,它不是建立在用户需要和偏好基础上推荐的。基于知识的方法因它们所用的功能知识不同而有明显区别。效用知识(FunctionalKnowledge)是一种关于一个项目如何满足某一特定用户的知识,因此能解释需要和推荐的关系,所以用户资料可以是任何能支持推理的知识结构,它可以是用户已经规范化的查询,也可以是一个更详细的用户需要的表示。
组合推荐
由于各种推荐方法都有优缺点,所以在实际中,组合推荐(HybridRecommendation)经常被采用。研究和应用最多的是内容推荐和协同过滤推荐的组合。最简单的做法就是分别用基于内容的方法和协同过滤推荐方法去产生一个推荐预测结果,然后用某方法组合其结果。尽管从理论上有很多种推荐组合方法,但在某一具体问题中并不见得都有效,组合推荐一个最重要原则就是通过组合后要能避免或弥补各自推荐技术的弱点。
在组合方式上,有研究人员提出了七种组合思路:
1)加权(Weight):加权多种推荐技术结果。
2)变换(Switch):根据问题背景和实际情况或要求决定变换采用不同的推荐技术。
3)混合(Mixed):同时采用多种推荐技术给出多种推荐结果为用户提供参考。
4)特征组合(Featurecombination):组合来自不同推荐数据源的特征被另一种推荐算法所采用。
5)层叠(Cascade):先用一种推荐技术产生一种粗糙的推荐结果,第二种推荐技术在此推荐结果的基础上进一步作出更精确的推荐。
6)特征扩充(Featureaugmentation):一种技术产生附加的特征信息嵌入到另一种推荐技术的特征输入中。
7)元级别(Meta-level):用一种推荐方法产生的模型作为另一种推荐方法的输入。
推荐系统的未来与发展方向:
增加推荐的多维性:
当前的大部分研究都是基于对象-用户的二维度量空间的,未考虑相关信息。然而,用户对对象的评价和选择常常由很多环境因素来决定,比如某个对象在特定时段很流行,用户在某个地方浏览对象的时候偏向于选择某类对象等。推荐系统除了融合了计算机科学的很多领域,它还融合了心理学、社会学。
个性化搜索结果会把搜索引擎变成上下文感知的推荐系统:
推荐系统是一个临界线,可以说这是个性化搜索。它可以发现用户“现在”所关心的事,比如系统发现你之前买过鞋,现在在搜索衬衫,那你现在其实是想干什么?推荐系统可以根据你是想和朋友一起去看电影,还是想和家人呆在一起,做出不同推荐。
增加向用户解释的推荐结果
根据用户的知识库,可以向用户做出更好的解释,向它们说明是什么样的因素在帮助系统做出这样的推荐。利用这样的系统,使用者确实体验更好了,他们对于系统的信任程度也提高了。
当然,推荐系统的发展方向和研究热点还有很多。随着对推荐系统功能需求特别是实时性及准确性上的需求水平的不断提高,其实现技术也都面临着严峻的挑战,需要不断的完善。
最后感谢“AnnieJ”博客的详细介绍和“张小磊啊”的资料。
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群,我们一起学习进步,探索领域中更深奥更有趣的知识!






