计算机视觉这一年:这是最全的一份CV技术报告
来源:新智元
编译:胡祥杰、刘小芹
最近The M Tank发布了一份对计算机视觉领域最近一年进展的报告《A Year in Computer Vision》,详述了四大部分的内容,包括分类/定位,目标检测,目标追踪等。不管对于初学者还是紧追前沿的研究者,这些都是不可多得的有用资料。
综述:计算机视觉最重要的进展
计算机视觉通常是指赋予机器视觉的能力,或赋予机器能够直观地分析它们的环境和内在的刺激。这个过程通常包括对一个图像、很多图像或视频的评估。英国机器视觉协会(BMVA)将计算机视觉定义为“自动提取、分析和理解来自单个图像或一系列图像的有用信息的过程”。
这个定义中的“理解”这个词说明了计算机视觉的重要性和复杂性。对我们的环境的真正理解不是仅仅通过视觉表现来实现的。相反,视觉信号通过视觉神经传递给主视觉皮层,并由大脑来解释。从这些感官信息中得出的解释包含了我们的自然编程和主观体验的总体,即进化是如何让我们生存下来,以及我们在生活中对世界的理解。
从这个角度看,视觉仅仅与图像的传输有关;虽然计算机认为图像与思想或认知更相似,涉及多个大脑区域的协作。因此,许多人认为由于计算机视觉的跨领域性质,对视觉环境及其背景的真正理解能为未来的强人工智能的迭代开拓道路。
然而,我们仍然处于这个迷人的领域的萌芽阶段。这份报告的目的是为了让我们对近年计算机视觉领域一些最重要的进展。尽管我们尽可能写得简明,但由于领域的特殊性,可能有些部分读起来比较晦涩。我们为每个主题提供了基本的定义,但这些定义通常只是对关键概念的基本解释。为了将关注的重点放在2016年的新工作,限于篇幅,这份报告会遗漏一些内容。
其中明显省略的一个内容是卷积神经网络(以下简称CNN或ConvNet)的功能,因为它在计算机视觉领域无处不在。2012年出现的 AlexNet(一个在ImageNet竞赛获得冠军的CNN架构)的成功带来了计算机视觉研究的转折点,许多研究人员开始采用基于神经网络的方法,开启了计算机视觉的新时代。
4年过去了,CNN的各种变体仍然是视觉任务中新的神经网络架构的主要部分,研究人员像搭乐高积木一样创造它们,这是对开源信息和深度学习能力的有力证明。不过,解释CNN的事情最好留给在这方面有更深入的专业知识的人。
对于那些希望在继续进行之前快速了解基础知识的读者,我们推荐下面的参考资料的前两个。对于那些希望进一步了解的人,以下的资料都值得一看:
深度神经网络如何看待你的自拍?by Andrej Karpathy 这篇文章能很好地帮助你了解产品和应用背后的CNN技术。
Quora:什么是卷积神经网络。这个quora问题下的回答有很多很好的参考链接和解释,适合初学者。
CS231n:视觉识别的卷积神经网络。这是斯坦福大学的一门深度的课程。
《深度学习》(Goodfellow, Bengio & Courville, 2016)第九章对CNN特征和功能提供了详细的解释。
对于那些希望更多地了解关于神经网络和深度学习的读者,我们推荐:
神经网络和深度学习(Nielsen,2017),这是一本免费的电子版教科书,它为读者提供了对于神经网络和深度学习的复杂性的非常直观的理解。
我们希望读者能从这份报告的信息汇总中获益,无论以往的经验如何,都可以进一步增加知识。
本报告包括以下部分(限于篇幅,文章省略了参考文献标识,请至原文查看):
第一部分:分类/定位,目标检测,目标追踪
第二部分:分割,超分辨率,自动上色,风格迁移,动作识别
第三部分:3D世界理解
第四部分:卷积网络架构,数据集,新兴应用
第一部分:分类/定位,目标检测,目标追踪
分类/定位
涉及到图像时,“分类”任务通常是指给一个图像分配一个标签,例如“猫”。这种情况下,“定位”(locolisation)指的是找到某个对象(object)在图像中的位置,通常输出为对象周围的某种形式的边界框。当前在ImageNet竞赛的图像分类/定位技术准确性超过一个经训练的人类。
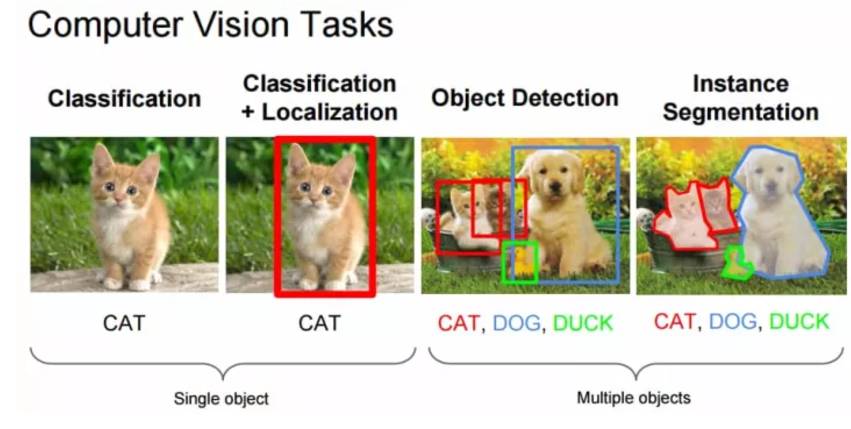
图:计算机视觉任务
Source: Fei-Fei Li, Andrej Karpathy & Justin Johnson (2016) cs231n, Lecture 8 - Slide 8, Spatial Localization and Detection (01/02/2016).Available: http://cs231n.stanford.edu/slides/2016/winter1516_lecture8.pdf
然而,由于更大的数据集(增加了11个类别)的引入,这很可能为近期的进展提供新的度量标准。在这一点上,Keras的作者François Chollet已经在有超过3.5亿的多标签图像,包含17000个类的谷歌内部数据集应用了新的技术,包括流行的Xception架构。
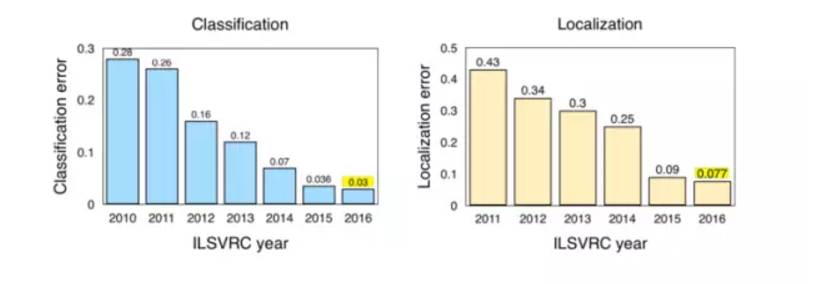
图:ILSVRC(2010-2016)图像分类/定位结果
Source: Jia Deng (2016). ILSVRC2016 object localisation: introduction, results. Slide 2. Available:http://image-net.org/challenges/talks/2016/ILSVRC2016_10_09_clsloc.pdf
2016年在ImageNet LSVRC 的一些主要进步:
场景分类(Scene Classification)是指用“温室”、“体育馆”、“大教堂”等特定场景来给图像贴上标签的任务。去年,ImageNet 进行了一个场景分类竞赛,使用Places2数据集的一个子集:包含800万张图片,用365类场景训练。Hikvision 以 9% top-5 error赢了比赛,利用一个深 Inception-style 网络,以及一个不特别深的残差网络。
Trimps-Soushen 以 2.99% 的top-5分类错误和7.71%的定位错误赢得了ImageNet分类任务。
Facebook的ResNeXt通过使用扩展原始ResNet架构的新架构,以3.03%在top-5 分类错误中排名第二。
对象检测(Object Dection)
对象检测的过程即检测图像中的某个对象。ILSVRC 2016 对对象检测的定义包括为单个对象输出边界框和标签。这不同于分类/定位任务,分类和定位的应用是多个对象,而不是一个对象。

图:对象检测(人脸是该情况需要检测的唯一一个类别)
Source: Hu and Ramanan (2016, p. 1)
2016年对象检测的主要趋势是转向更快、更高效的检测系统。这在YOLO、SSD和R-FCN等方法中表现出来,目的是为了在整个图像上共享计算。因此,这些与计算昂贵的Fast R-CNN和Faster R-CNN相区别。这通常被称为“端到端训练/学习”。
其基本原理是避免将单独的算法集中在各自的子问题上,因为这通常会增加训练时间,并降低网络的准确性。也就是说,这种网络的端到端适应通常是在初始的子网络解决方案之后进行的,因此,是一种回顾性优化( retrospective optimisation)。当然,Fast R-CNN和Faster R-CNN仍然是非常有效的,并且被广泛应用于物体检测。
SSD:Single Shot MultiBox Detector 这篇论文利用单个神经网络来封装所有必要的计算,它实现了“75.1%的mAP,超越了更先进的R-CNN模型”(Liu et al., 2016)。我们在2016年看到的最令人印象深刻的系统之一是“YOLO9000:Better, Faster, Stronger”,其中介绍了YOLOv2和YOLO9000检测系统。YOLOv2大大改善了初始的YOLO模型,并且能够以非常高的FPS获得更好的结果。除了完成速度之外,系统在特定对象检测数据集上的性能优于使用ResNet和SSD的Faster-RCNN。
FAIR的Feature Pyramid Networks for Object Detection
R-FCN: Object Detection via Region-based Fully Convolutional Networks
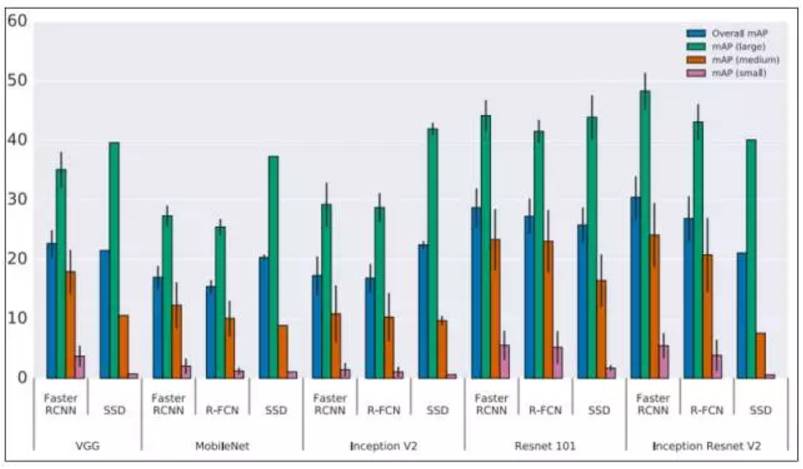
图:不同架构在对象检测任务的准确率
Source: Huang et al. (2016, p. 9)
ILSVRC 和 COCO Challenge的结果
COCO(Common Objects in Context)是另一个流行的图像数据集。不过,它比ImageNet小,也更具有策略性,在更广泛的场景理解的背景下着重于对象识别。组织者每年都要针对对象检测,分割和关键点组织竞赛。 ILSVRC 和COCO 对象检测挑战的检测是:
ImageNet LSVRC Object Detection from Images (DET): CUImage 66% meanAP. Won 109 out of 200 object categories.
ImageNet LSVRC Object Detection from video (VID): NUIST 80.8% mean AP
ImageNet LSVRC Object Detection from video with tracking: CUvideo 55.8% mean AP
COCO 2016 Detection Challenge (bounding boxes): G-RMI (Google) 41.5% AP (4.2% absolute percentage increase from 2015 winner MSRAVC)
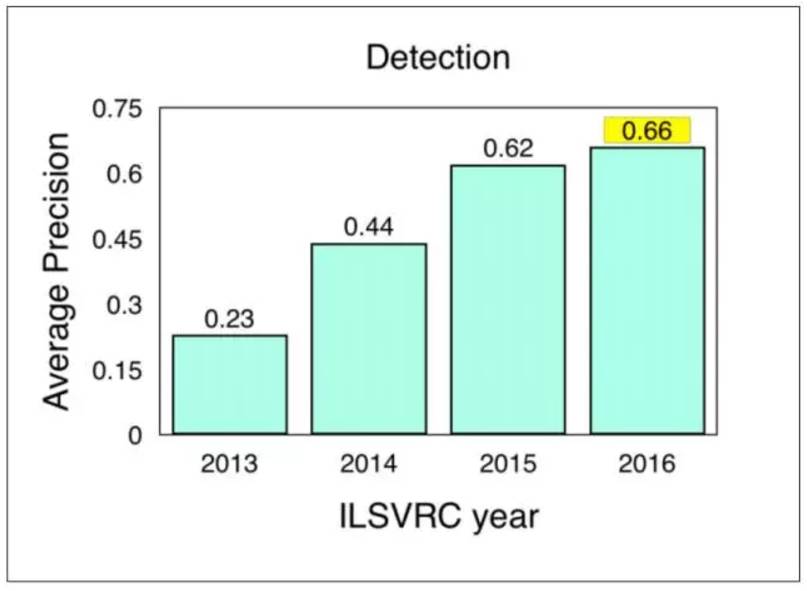
图:ILSVRC 对象检测结果(2013-2016)
Source: ImageNet. 2016. [Online] Workshop Presentation, Slide 2. Available: http://image-net.org/challenges/talks/2016/ECCV2016_ilsvrc_coco_detection_segmentation.pdf
对象跟踪
对象跟踪(Object Tracking)是指在给定场景中跟踪特定对象或多个对象的过程。传统上,它在视频和现实世界的交互中都有应用,例如,对象跟踪对自动驾驶系统至关重要。
用于对象跟踪的全卷积的Siamese网络(Fully-Convolutional Siamese Networks for Object Tracking)结合了一个基本的跟踪算法和一个Siamese网络,经过端到端的训练,它实现了SOTA,并且可以在帧速率超过实时的情况下进行操作。
利用深度回归网络学习以100 FPS跟踪(Learning to Track at 100 FPS with Deep Regression Networks)是另一篇试图通过在线训练方法改善现有问题的论文。作者提出了一种利用前馈网络的跟踪器来学习对象运动、外观和定位的一般关系,从而有效地跟踪没有在线训练的新对象。它提供了SOTA标准跟踪基准,同时实现了“以100 fps跟踪通用对象”(Held et al., 2016)。
Deep Motion Features for Visual Tracking 综合了人工特征,deep RGB/外观特征(来自CNN),以及深度运动特性(在光流图像上训练)来实现SOTA。虽然Deep Motion Feature在动作识别和视频分类中很常见,但作者称这是第一次使用视觉追踪技术。这篇论文获得了2016年ICPR的最佳论文,用于“计算机视觉和机器人视觉”跟踪。
Virtual Worlds as Proxy for Multi-Object Tracking Analysis,这篇文章在现有的视频跟踪基准和数据集中,提出了一种新的现实世界克隆方法,该方法可以从零开始生成丰富的、虚拟的、合成的、逼真的环境,并使用全标签来克服现有数据集的不足。这些生成的图像被自动地标记为准确的ground truth,允许包括对象检测/跟踪等一系列应用。
全卷积网络的全局最优对象跟踪(Globally Optimal Object Tracking with Fully Convolutional Networks),这篇文章解决了对象的变化和遮挡问题,并将它们作为对象跟踪中的两个根限制。作者称,“我们提出的方法利用一个全卷积的网络解决了对象的外形变化问题,并处理了动态规划的遮挡问题”(Lee et al., 2016)。
第二部分:分割、 超分辨率/色彩化/风格迁移、 行为识别
计算机视觉的中心就是分割的过程,它将整个图像分成像素组,然后可以对这些组进行标记和分类。此外,语义分割通过试图在语义上理解图像中每个像素的角色是猫,汽车还是其他类型的,又在这一方向上前进了一步。实例分割通过分割不同类的实例来进一步实现这一点,比如,用三种不同颜色标记三只不同的狗。这是目前在自动驾驶技术套件中使用的计算机视觉应用的一大集中点。
也许今年分割领域的一些最好的提升来自FAIR,他们从2015年开始继续深入研究DeepMask。DeepMask生成粗糙的“mask”作为分割的初始形式。 2016年,Fair推出了SharpMask ,它改进了DeepMask提供的“mask”,纠正了细节的缺失,改善了语义分割。除此之外,MultiPathNet 标识了每个mask描绘的对象。
“为了捕捉一般的物体形状,你必须对你正在看的东西有一个高水平的理解(DeepMask),但是要准确地描述边界,你需要再回过去看低水平的特征,一直到像素(SharpMask)。“ - Piotr Dollar,2016

图:Demonstration of FAIR techniques in action
视频传播网络(Vedio Propagation Network)试图创建一个简单的模型来传播准确的对象mask,在第一帧分配整个视频序列以及一些附加信息。
2016年,研究人员开始寻找替代网络配置来解决上述的规模和本地化问题。 DeepLab 就是这样一个例子,它为语义图像分割任务取得了令人激动的结果。 Khoreva等人(2016)基于Deeplab早期的工作(大约在2015年),提出了一种弱监督训练方法,可以获得与完全监督网络相当的结果。
计算机视觉通过使用端到端网络进一步完善了有用信息网络的共享方式,减少了分类中,多个全向子任务的计算需求。两个关键的论文使用这种方法是:
100 Layers Tiramisu是一个完全卷积的DenseNet,它以前馈的方式将每一层连接到每一层。它还通过较少的参数和训练/处理在多个基准数据集上实现SOTA。
Fully Convolutional Instance-aware Semantic Segmentation共同执行实例掩码预测和分类(两个子任务)。COCO分割挑战冠军MSRA。 37.3%AP。比起2015 COCO挑战赛中的MSRAVC,绝对跃升了9.1%。
虽然ENet是一种用于实时语义分割的DNN体系结构,但它并不属于这一类别,它证明了降低计算成本和提供更多移动设备访问的商业价值。
我们的工作希望将尽可能多的这些进步回溯到有形的公开应用。考虑到这一点,以下内容包含2016年一些最有意义的医疗保健应用细分市场:
A Benchmark for Endoluminal Scene Segmentation of Colonoscopy Images
3D fully convolutional networks for subcortical segmentation in MRI: A large-scale study
Semi-supervised Learning using Denoising Autoencoders for Brain Lesion Detection and Segmentation
3D Ultrasound image segmentation: A Survey
A Fully Convolutional Neural Network based Structured Prediction Approach Towards the Retinal Vessel Segmentation
3-D Convolutional Neural Networks for Glioblastoma Segmentation
我们最喜欢的准医学分割应用之一是FusionNet ——一个深度全卷积神经网络,用于连接组学的图像分割,基于SOTA电子显微镜(EM)分割方法。
超分辨率、风格迁移和着色
并非计算机视觉领域的所有研究都是为了扩展机器的伪认知能力,而且神经网络的神话般的可塑性以及其他ML技术常常适用于各种其他新颖的应用,这些应用可以渗透到公共空间中。超分辨率方案,风格转移和着色去年的进步占据了整个领域。
超分辨率指的是从低分辨率对应物估计高分辨率图像的过程,以及不同放大倍数下图像特征的预测,这是人脑几乎毫不费力地完成的。最初的超分辨率是通过简单的技术,如bicubic-interpolation和最近邻。在商业应用方面,克服低分辨率限制和实现“CSI Miami”风格图像增强的愿望推动了该领域的研究。以下是今年的一些进展及其潜在的影响:
Neural Enhance 是Alex J. Champandard的创意,结合四篇不同研究论文的方法来实现超分辨率方法。
实时视频超分辨率解决方案也在2016年进行了两次著名的尝试。
RAISR:来自Google的快速而准确的图像超分辨率方法。通过使用低分辨率和高分辨率图像对训练滤波器,避免了神经网络方法的昂贵内存和速度要求。作为基于学习的框架,RAISR比同类算法快两个数量级,并且与基于神经网络的方法相比,具有最小的存储器需求。因此超分辨率可以扩展到个人设备。
生成对抗网络(GAN)的使用代表了当前用于超分辨率的SOTA:
SRGAN 通过训练区分超分辨率和原始照片真实图像的辨别器网络,在公共基准测试中提供多采样图像的逼真纹理。
尽管SRResNet在峰值信噪比(PSNR)方面的表现最佳,但SRGAN获得更精细的纹理细节并达到最佳的平均评分(MOS),SRGAN表现最佳。
“据我们所知,这是第一个能够推出4倍放大因子的照片般真实的自然图像的框架。”以前所有的方法都无法在较大的放大因子下恢复更精细的纹理细节。
Amortised MAP Inference for Image Super-resolution 提出了一种使用卷积神经网络计算最大后验(MAP)推断的方法。但是,他们的研究提出了三种优化方法,GAN在其中实时图像数据上表现明显更好。
毫无疑问,Style Transfer集中体现了神经网络在公共领域的新用途,特别是去年的Facebook集成以及像Prisma 和Artomatix 这样的公司。风格转换是一种较旧的技术,但在2015年出版了一个神经算法的艺术风格转换为神经网络。从那时起,风格转移的概念被Nikulin和Novak扩展,并且也被用于视频,就像计算机视觉中其他的共同进步一样。

图:风格迁移的例子
风格转换作为一个主题,一旦可视化是相当直观的,比如,拍摄一幅图像,并用不同的图像的风格特征呈现。例如,以着名的绘画或艺术家的风格。今年Facebook发布了Caffe2Go,将其深度学习系统整合到移动设备中。谷歌也发布了一些有趣的作品,试图融合多种风格,生成完全独特的图像风格。
除了移动端集成之外,风格转换还可以用于创建游戏资产。我们团队的成员最近看到了Artomatix的创始人兼首席技术官Eric Risser的演讲,他讨论了该技术在游戏内容生成方面的新颖应用(纹理突变等),因此大大减少了传统纹理艺术家的工作。
着色
着色是将单色图像更改为新的全色版本的过程。最初,这是由那些精心挑选的颜色由负责每个图像中的特定像素的人手动完成的。2016年,这一过程自动化成为可能,同时保持了以人类为中心的色彩过程的现实主义的外观。虽然人类可能无法准确地表现给定场景的真实色彩,但是他们的真实世界知识允许以与图像一致的方式和观看所述图像的另一个人一致的方式应用颜色。
着色的过程是有趣的,因为网络基于对物体位置,纹理和环境的理解(例如,图像)为图像分配最可能的着色。它知道皮肤是粉红色,天空是蓝色的。
“而且,我们的架构可以处理任何分辨率的图像,而不像现在大多数基于CNN的方法。”
在一个测试中,他们的色彩是多么的自然,用户从他们的模型中得到一个随机的图像,并被问到,“这个图像看起来是自然的吗?
他们的方法达到了92.6%,基线达到了大约70%,而实际情况(实际彩色照片)被认为是自然的97.7%。
行为识别
行为识别的任务是指在给定的视频帧内动作的分类,以及最近才出现的,用算法预测在动作发生之前几帧的可能的相互作用的结果。在这方面,我们看到最近的研究尝试将上下文语境嵌入到算法决策中,类似于计算机视觉的其他领域。这个领域的一些关键论文是:
Long-term Temporal Convolutions for Action Recognition利用人类行为的时空结构,即特定的移动和持续时间,以使用CNN变体正确识别动作。为了克服CNN在长期行为的次优建模,作者提出了一种具有长时间卷积(LTC-CNN)的神经网络来提高动作识别的准确性。简而言之,LTC可以查看视频的较大部分来识别操作。他们的方法使用和扩展了3D CNN,以便在更充分的时间尺度上进行行动表示。
“我们报告了人类行为识别UCF101(92.7%)和HMDB51(67.2%)两个具有挑战性的基准的最新成果。
用于视频动作识别的时空残差网络将两个流CNN的变体应用于动作识别的任务,该任务结合了来自传统CNN方法和最近普及的残留网络(ResNet)的技术。这两种方法从视觉皮层功能的神经科学假设中获得灵感,即分开的路径识别物体的形状/颜色和运动。作者通过注入两个CNN流之间的剩余连接来结合ResNets的分类优势。
Anticipating Visual Representations from Unlabeled Video是一个有趣的论文,尽管不是严格的行为分类。该程序预测了在一个动作之前一个视频帧序列可能发生的动作。该方法使用视觉表示而不是逐像素分类,这意味着程序可以在没有标记数据的情况下运行,利用深度神经网络的特征学习特性。
Thumos Action Recognition Challenge 的组织者发表了一篇论文,描述了最近几年来Action Action Recognition的一般方法。本文还提供了2013-2015年挑战的概要,以及如何通过行动识别让计算机更全面地了解视频的挑战和想法的未来方向。
第三部分 走向理解3D世界
在计算机视觉中,正如我们所看到的,场景,对象和活动的分类以及边界框和图像分割的输出是许多新研究的重点。实质上,这些方法应用计算来获得图像的二维空间的“理解”。然而,批评者指出,3D理解对于解释系统成功和现实世界导航是必不可少的。
例如,一个网络可能会在图像中找到一只猫,为它的所有像素着色,并将其归类为一只猫。但是,在猫所处的环境中,网络是否完全理解图像中猫的位置?
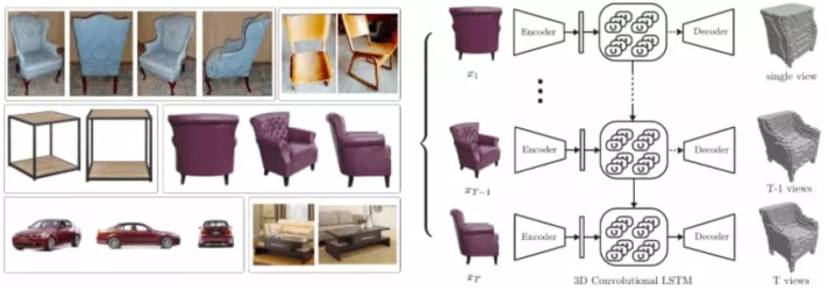
有人认为,从上述任务中,计算机对于3D世界的了解很少。与此相反,即使在看2D图片(即,透视图,遮挡,深度,场景中的对象如何相关)等情况下,人们也能够以3D来理解世界。将这些3D表示及其相关知识传递给人造系统代表了下一个伟大计算机视觉的前沿。一般认为这样做的一个主要原因是:
“场景的2D投影是构成场景的相机,灯光和物体的属性和位置的复杂功能的组合。如果赋予3D理解,智能体可以从这种复杂性中抽象出来,形成稳定的,不受限制的表示,例如,认识到在不同的光照条件下,或者在部分遮挡下,是从上面或从侧面看的椅子。“
但是,3D理解传统上面临着几个障碍。首先关注“自我和正常遮挡”问题以及适合给定2D表示的众多3D形状。由于无法将相同结构的不同图像映射到相同的3D空间以及处理这些表示的多模态,所以理解问题变得更加复杂。最后,实况3D数据集传统上相当昂贵且难以获得,当与表示3D结构的不同方法结合时,可能导致训练限制。
我们认为,在这个领域进行的工作很重要,需要注意。从早期的AGI系统和机器人技术的早期理论应用,到在不久的将来会影响我们社会,尽管还在萌芽期,由于利润丰厚的商业应用,我们谨慎地预测这一计算机视觉领域的指数级增长,这意味着计算机很快就可以开始推理世界,而不仅仅是像素。
OctNet: Learning Deep 3D Representations at High Resolutions
ObjectNet3D: A Large Scale Database for 3D Object Recognition
3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction
3D Shape Induction from 2D Views of Multiple Objects
Unsupervised Learning of 3D Structure from Images
人类姿势预估和关键点监测
人体姿势估计试图找出人体部位的方向和构型。 2D人体姿势估计或关键点检测一般是指定人体的身体部位,例如寻找膝盖,眼睛,脚等的二维位置。
然而,三维姿态估计通过在三维空间中找到身体部位的方向来进一步进行,然后可以执行形状估计/建模的可选步骤。这些分支已经有了很大的改进。
在过去的几年中,在竞争性评估方面,“COCO2016挑战包括同时检测人和本地化关键点”。 ECCV 供了有关这些主题的更多的文献,但是我们想强调以下几篇论文:
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image
重构
如前所述,前面的部分介绍了重构的一些例子,但总的来说重点是物体,特别是它们的形状和姿态。虽然其中一些在技术上是重构的,但是该领域本身包括许多不同类型的重构,例如,场景重构,多视点和单视点重建,运动结构(SfM),SLAM等。此外,一些重构方法利用附加(和多个)传感器和设备,例如事件或RGB-D摄像机,多种技术来推动进步。
结果?整个场景可以非刚性地重建并且在时空上改变,例如,对你自己的高保真重构,以及你的动作进行实时更新。
如前所述,围绕2D图像映射到3D空间的问题持续存在。以下文章介绍了大量创建高保真实时重建的方法:
Fusion4D: Real-time Performance Capture of Challenging Scenes
Real-Time 3D Reconstruction and 6-DoF Tracking with an Event Camera
Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue
其他未分类3D:
IM2CA
Learning Motion Patterns in Videos
Deep Image Homography Estimation
gvnn: Neural Network Library for Geometric Computer Vision
3D summation and SLAM
在整个这一节中,我们在3D理解领域进行了一个横切面似的介绍,主要侧重于姿态估计,重构,深度估计和同形目录。但是,还有更多的精彩的工作被我们忽略了,我们在数量上受到限制。所以,我们希望给读者提供一个宝贵的出发点。
大部分突出显示的作品可能被归类于几何视觉,它通常涉及从图像直接测量真实世界的数量,如距离,形状,面积和体积。我们的启发是基于识别的任务比通常涉及几何视觉中的应用程序更关注更高级别的语义信息。但是,我们经常发现,这些3D理解的不同领域大部分是密不可分的。
最大的几何问题之一是SLAM,研究人员正在考虑SLAM是否会成为深度学习所面临的下一个问题。所谓“深度学习的普遍性”的怀疑论者,其中有很多都指出了SLAM作为算法的重要性和功能性:
“视觉SLAM算法能够同时建立世界三维地图,同时跟踪摄像机的位置和方向。” SLAM方法的几何估计部分目前不适合深度学习方法,所以端到端学习不太可能。 SLAM代表了机器人中最重要的算法之一,并且是从计算机视觉领域的大量输入设计的。该技术已经在Google Maps,自动驾驶汽车,Google Tango 等AR设备,甚至Mars Luver等应用。
第四部分:卷积架构、数据集、新兴应用
ConvNet架构最近在计算机视觉之外发现了许多新颖的应用程序,其中一些应用程序将在我们即将发布的论文中出现。然而,他们继续在计算机视觉领域占有突出的地位,架构上的进步为本文提到的许多应用和任务提供了速度,准确性和训练方面的改进。
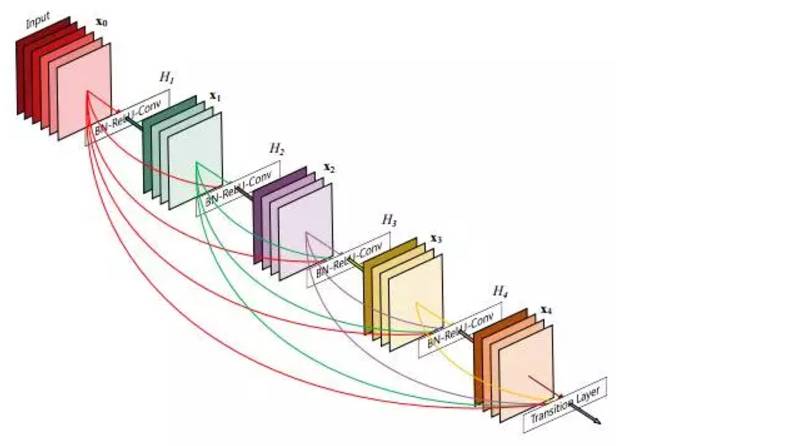
图:DenseNet架构
基于这个原因,ConvNet体系结构对整个计算机视觉至关重要。以下是2016年以来一些值得关注的ConvNet架构,其中许多从ResNets最近的成功中获得灵感。
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Densely Connected Convolutional Networks
FractalNet Ultra-Deep Neural Networks without Residuals
Lets keep it simple: using simple architectures to outperform deeper architectures
Swapout: Learning an ensemble of deep architectures
SqueezeNet
Concatenated Rectified Linear Units (CRelu)
Exponential Linear Units (ELUs)
Parametric Exponential Linear Unit (PELU)
Harmonic CNNs
Exploiting Cyclic Symmetry in Convolutional Neural Networks
Steerable CNNs
残差网络(Residual Networks)
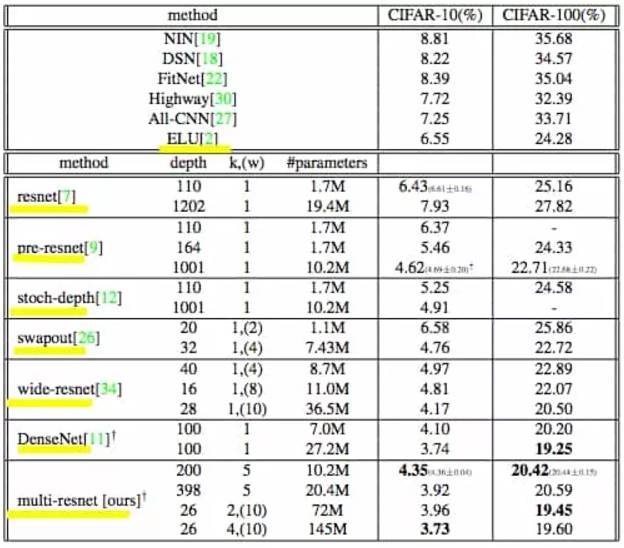
图:Test-Error Rates on CIFAR Datasets
随着微软ResNet的成功,Residual Networks及其变体在2016年变得非常受欢迎,现在提供了许多开源版本和预训练模型。在2015年,ResNet在ImageNet的检测,本地化和分类任务以及COCO的检测和分段挑战中获得了第一名。虽然深度问题仍然存在,但ResNet处理梯度消失的问题为“深度增加产生超级抽象”提供了更多的动力,这是目前深度学习的基础。
ResNet通常被概念化为一个较浅的网络集合,它通过运行平行于其卷积层的快捷连接来抵消深度神经网络(DNN)的层次性。这些快捷方式或跳过连接可减轻与DNN相关的消失/爆炸梯度问题,从而允许在网络层中更容易地反向传播梯度。
残差学习、理论与进展
Wide Residual Networks
Deep Networks with Stochastic Depth
Learning Identity Mappings with Residual Gates
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
Identity Mappings in Deep Residual Networks
Multi-Residual Networks: Improving the Speed and Accuracy of Residual Networks
Highway and Residual Networks learn Unrolled Iterative Estimation
Residual Networks of Residual Networks: Multilevel Residual Networks
Resnet in Resnet: Generalizing Residual Architectures
Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex
Convolutional Residual Memory Networks
Identity Matters in Deep Learning
Deep Residual Networks with Exponential Linear Unit
Weighted Residuals for Very Deep Networks
数据集
Places2
SceneNet RGB-D
CMPlaces
MS-Celeb-1M
Open Images
YouTube-8M
一些用例和趋势
来自Facebook的盲人应用程序和百度的硬件
情感检测结合了面部检测和语义分析,并且正在迅速增长。目前有20多个API可用。
从航空影像中提取道路,从航空地图和人口密度地图中分类土地。
尽管目前还存在一些功能性问题,但Amazon Go进一步提高了计算机视觉的形象,证明了无排队的购物体验。
对于我们基本上没有提到无人驾驶,我们做了大量的工作。然而,对于那些希望深入研究一般市场趋势的人来说,莫里茨·穆勒 - 弗雷塔格(Moritz Mueller-Freitag)就德国汽车工业和自动驾驶汽车的影响作了精彩的介绍。
其他有趣的领域:图像检索/搜索,手势识别,修复和面部重建。
数字成像与医学通讯(DICOM)和其他医学应用(特别是与成像相关的)。例如,有许多Kaggle检测竞赛(肺癌,宫颈癌),其中一些有较大的金钱诱因,其中的算法试图在分类/检测任务中胜过专家。
硬件和市场
机器人视觉/机器视觉(独立领域)和物联网的潜在目标市场不断壮大。我们个人最喜欢的是一个日本的农民的孩子使用深度学习,树莓派和TensorFlow对黄瓜形状,大小和颜色进行分类。这使他的母亲分拣黄瓜所花的人力时间大大减少。
计算需求的缩减和移动到移动的趋势是显而易见的,但是它也是通过硬件加速来实现的。很快我们会看到口袋大小的CNN和视觉处理单元(VPUs)到处都是。例如,Movidius Myriad2被谷歌的Project Tango和无人机所使用。
Movidius Fathom 也使用了Myriad2的技术,允许用户将SOTA计算机视觉性能添加到消费类设备中。具有USB棒的物理特性的Fathom棒将神经网络的能力带到几乎任何设备:一根棒上的大脑。
传感器和系统使用可见光以外的东西。例子包括雷达,热像仪,高光谱成像,声纳,磁共振成像等。
LIDAR的成本降低,它使用光线和雷达来测量距离,与普通的RGB相机相比具有许多优点。目前有不少于500美元的LIDAR设备。
Hololens和近乎无数的其他增强现实头盔进入市场。
Google的Project Tango 代表了SLAM的下一个大型商业化领域。 Tango是一个增强现实计算平台,包含新颖的软件和硬件。 Tango允许在不使用GPS或其他外部信息的情况下检测移动设备相对于世界的位置,同时以3D形式绘制设备周围的区域。
Google合作伙伴联想于2016年推出了价格适中的Tango手机,允许数百名开发人员开始为该平台创建应用程序。 Tango采用以下软件技术:运动跟踪,区域学习和深度感知。
与其他领域结合的前沿研究:
唇语
生成模型
结论
总之,我们想突出一些在我们的研究回顾过程中反复出现的趋势和反复出现的主题。首先,我们希望引起人们对机器学习研究社区极度追求优化的关注。这是最值得注意的,体现在这一年里精确率的不断提升。
错误率不是唯一的狂热优化参数,研究人员致力于提高速度、效率,甚至算法能够以全新的方式推广到其他任务和问题。我们意识到这是研究的前沿,包括one-shot learning、生成模型、迁移学习,以及最近的evolutionary learning,我们认为这些研究原则正逐渐产生更大的影响。
虽然这最后一点毫无疑问是值得称赞的,而不是对这一趋势的贬低,但人们还是禁不住要把他们的注意力放在(非常)的通用人工智能。我们只是希望向专家和非专业人士强调,这一担忧源自于此,来自计算机视觉和其他人工智能领域的惊人进展。通过对这些进步及其总体影响的教育,可以减少公众不必要的担忧。这可能会反过来冷却媒体的情绪和减少有关AI的错误信息。
出于两个原因,我们选择专注于一年的时间里的进展。第一个原因与这一领域的新工作数量之大有关。即使对那些密切关注这一领域的人来说,随着出版物数量呈指数级的增长,跟上研究的步伐也变得越来越困难。第二个原因,让我们回头看看这一年内的变化。
在了解这一年的进展的同时,读者可以了解目前的研究进展。在这么短的时间跨度里,我们看到了这么多的进步,这是如何得到的?研究人员形成了以以前的方法(架构、元架构、技术、想法、技巧、结果等)和基础设施(Keras、TensorFlow、PyTorch、TPU等)的全球社区,这不禁值得鼓励,也值得庆祝。很少有开源社区像这样不断吸引新的研究人员,并将它的技术应用于经济学、物理学和其他无数领域。
对于那些尚未注意到的人来说,理解这一点非常重要,即在许多不同声音中,宣称对这种技术的本质有理解,至少有共识,认同这项技术将以新的令人兴奋的方式改变世界。然而,在这些改变实现之前,仍存在许多分歧。
我们将继续尽最大的努力提供信息。有了这样的资源,我们希望满足那些希望跟踪计算机视觉和人工智能的进展的人的需求,我们的项目希望为开源革命增添一些价值,而这个革命正在技术领域悄然发生。
报告下载地址:http://www.themtank.org/a-year-in-computer-vision
*推荐文章*
*注*:如有想加入极市专业CV开发者微信群(项目需求+分享),请填写申请表(链接:http://cn.mikecrm.com/wcotd9)或者在本公众号后台回复”加群“申请入群




