
一 前言
1 平台现状
阶段分析
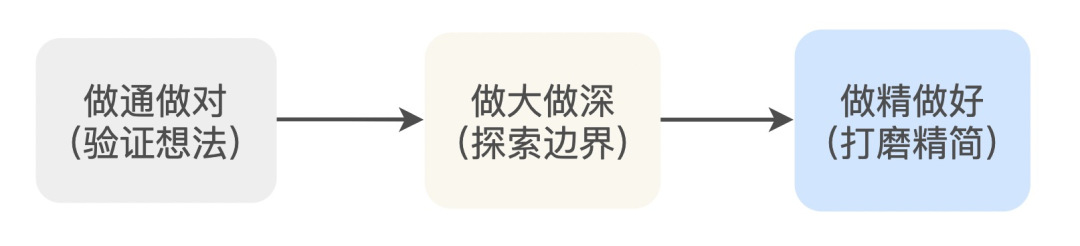
阶段成果
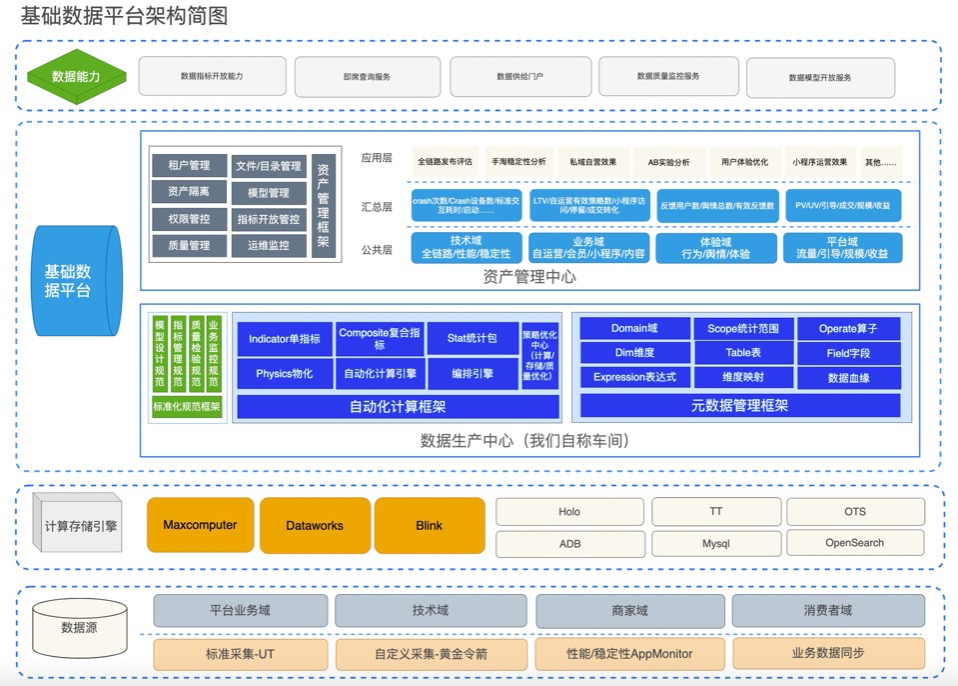
2 整体架构
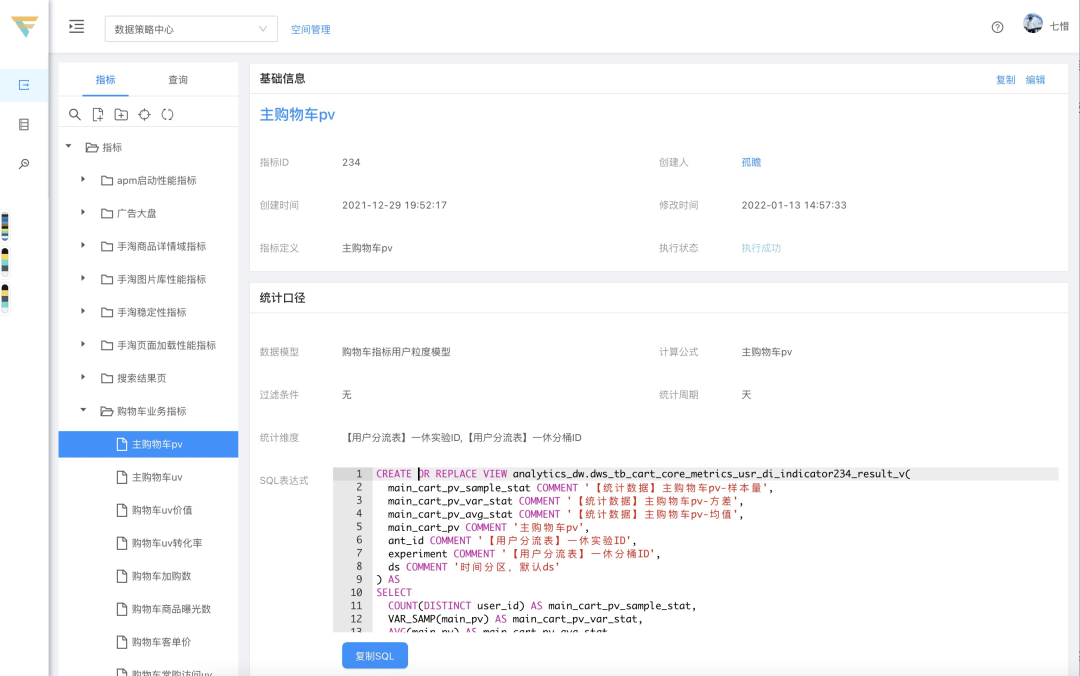
3 页面概览

二 数据平台到底要做个啥?
所以建设高度自动化&体系化的知识管理系统,重构知识的供给模式,到底是啥意思?
解释清楚这个目标,只需要解释清楚如下两个问题:
“数据”是如何影响“业务决策”的?
数据”影响“决策”的过程中,有哪些问题和机会?
问题一:“数据”如何影响“业务决策” ?
数据生产消费生命周期
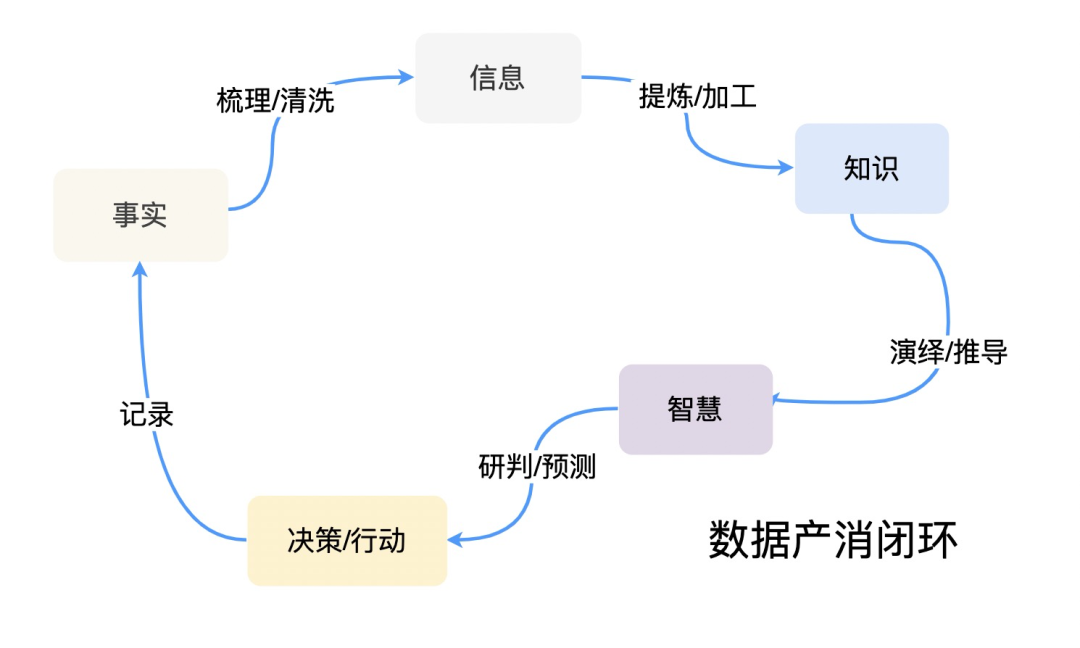
现实世界中,我们可以把数据的生命周期抽象成5个部分:“事实->信息->知识->智慧->决策&行动->回到 事实”。下面给出我个人理解的每个部分的含义:
事实:代表数据被如实的记录(ODS),事实是庞杂冗余无意义的。只有通过分类和清洗才能得到对人有意义的信息。
信息:代表事实中是有意义的部分(DWD + DIM),信息是对一类事实情况的描述。而当信息通过业务的定义与提炼加工,就能生产出有用的知识。
知识:代表信息加工出的有用的部分我称之为知识(ADS)。比如巴菲特是股神这是信息。而买qqq对与普通人来说整体收益不从不错,可以考虑月供qqq,这是知识。
智慧:不同的知识相互碰撞,演绎,推导能产生新的知识,我们称这种为智慧,智慧是能预测未来的。借用我的好友@骨玉(zherui.lzr)的总结:知识是有用的,而智慧是能预测未来的!
决策/行动:通过智慧,了解未知,研判未来,做出决策,行动落地,从而产生新的事实结果,进入下一轮循环。
举个例子
吾有一友,名叫老王,不住隔壁。
老王有座山,山上有野花,野草,鸡,苹果等各种动植物(事实)。 其中鸡和苹果比较有价值,于是老王就把他们圈起来养殖(从事实中梳理出有价值的信息)。并定时喂食施肥除虫,后来鸡和苹果都顺利长大成熟,成为了能吃,能卖的农产品(信息加工成了有用的知识)。 后来老王又发现鸡比苹果利润高很多,如果只养鸡能多赚50%(知识推演出可预测未来的智慧)。于是第二年他决定只养鸡(决策/行动)。后来禽流感来袭,山头只剩野花了,老王血本无归,一盘算还是出租稳当,于是老王把山一租,又回来写代码了。(第二轮数据的生产消费闭环)
这个故事中:
老王山头上的各种动植物就是事实:事实的核心要求是全面真实,而核心行为是采集记录。
动植物中的鸡和苹果就是信息:信息的核心要求是有意义,而核心行为上是梳理和清洗。
把鸡和苹果养殖大就是知识:知识的核心要求是有价值有用,而核心行为上是加工和提炼。可以自己吃转化成身体的养分,也可以卖钱投资再生产。这是对老王有用的。 在数据中就是指标了。
老王发现养鸡更赚钱就是智慧:智慧的核心要求是可预测未知,而核心行为是使用知识进行演绎推导。
最终只养鸡就是决策/行动:决策和行动将产生新的事实,进入下一轮循环。
那我们来试着回答一下第一个问题:“数据”如何影响“业务决策” ?
答:首先我们通过埋点采集得到原始的事实(实时数据),从事实中梳理清洗得到信息(明细),随后通过定义和加工融合各类维度(维度),能得到对应的知识(业务指标)。而用户通过各类途径获得到指标后,通过演绎推导等方法,预测业务的发展,然后并做出下一步的决策。
问题二:“数据”影响“决策”的过程中,有哪些问题和机会?
我们简化一下:
我们把事实梳理成信息,信息加工成知识的整个过程,称为知识生产。
通过智慧预测未来,影响业务决策的过程,称为业务决策。
而知识管理,沉淀,运输,供给等中间环节,称之为知识供给和知识获取。
这里面的每个部分,其实都存在问题,也包含了很多的机会。
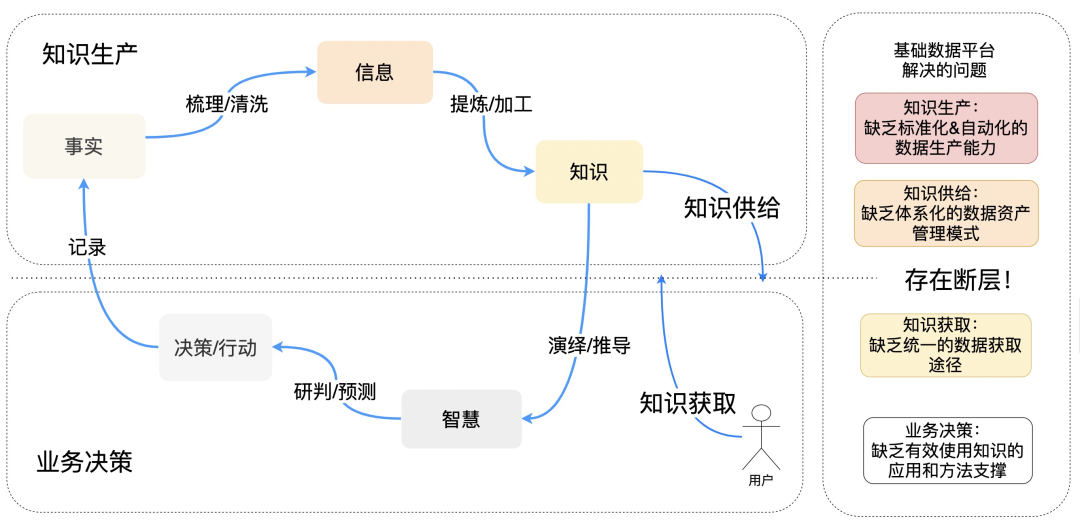
知识生产:缺乏标准化&自动化的工程体系来生产指标
问题:
缺乏标准化协议
需求流程标准
数仓分层标准
计算模型标准
缺乏自动化能力
需求吞吐瓶颈:纯研发人肉开发,存在研发资源瓶颈,需求吞吐量跟不上业务发展速度,业务诉求无法得到及时满足。我们希望80%的以上指标自动化生产。
计算存储资源浪费:每个Project都存在非常多相同指标重复开发的情况。 这就导致了指标的重复计算,重复存储,浪费资源,浪费钱。
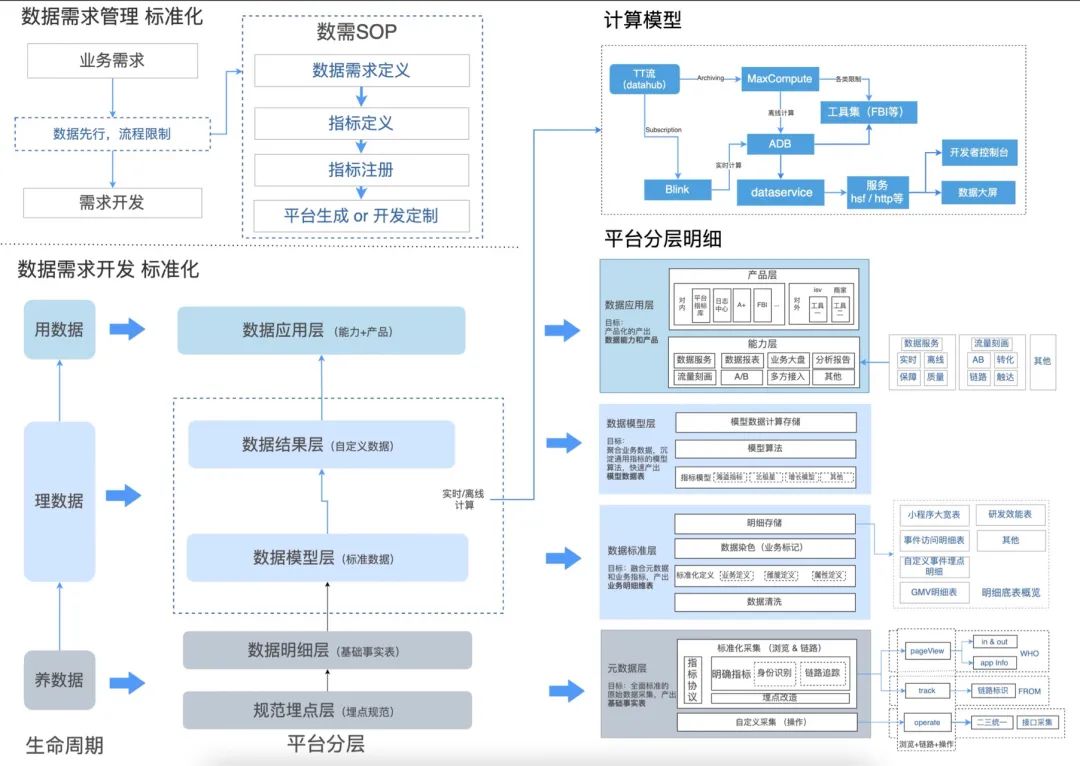
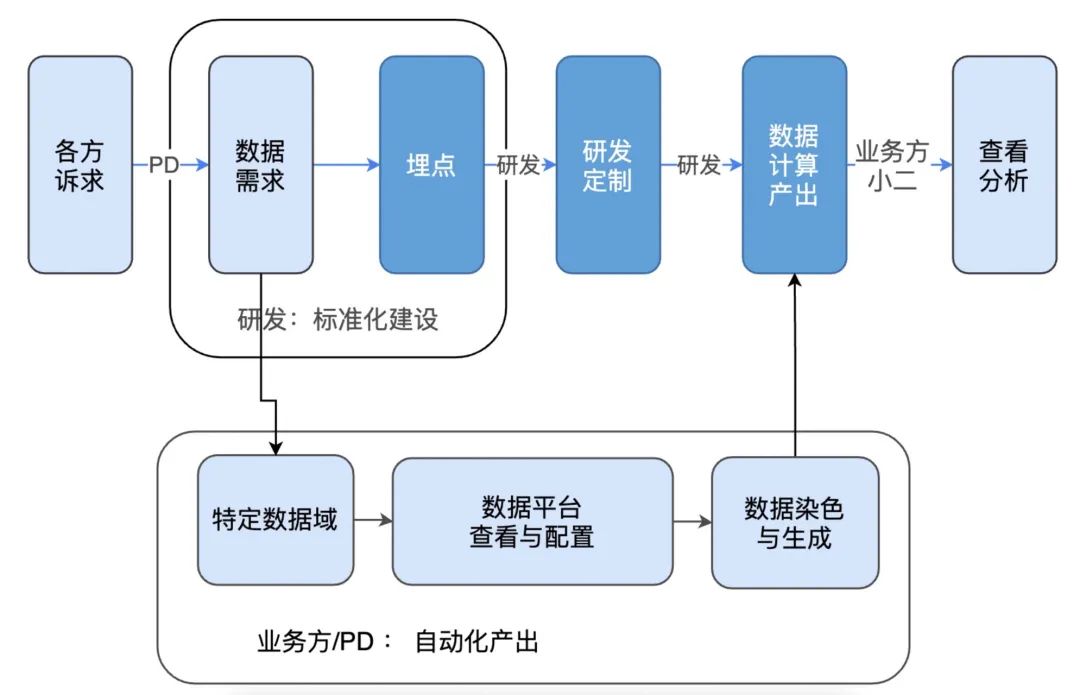
解法:建立一套标准化自动化的工程体系去自动化的生产指标。并以此为基础拓展进行知识的供给。
知识供给:缺少体系化的数据资产管理能力。
问题:
数据指标失真:业务常常会发现指标不对,或者之前对,最近突然不对了。更有甚者根本不知道指标对不对。导致大家对指标失去信赖,徒增非常多的沟通成本。
数据资产管理混乱:一个指标好多人在生产,指标的信息存放在各种地方,信哪个?SQL是脚本语言,代码可谓千人千面,没有标准注释,同事离职交接时的体验尤为酸爽。
数据资产不透明:DAU,研发效能如何定义? 知道定义后,那对应的表和字段是什么?哪里可以查嘛? 同时算子,维度,范围等配置明明都是一样的,但生产时却无法复用。
解法:需要体系化的管理指标并保证指标的准确性。当然这个重度依赖标准化&自动化的知识生产能力。
知识获取:知识获取效率低下
问题:
指标获取效率低下:运营有数据诉求,不知道去哪里获取。知道哪里获取后常常也要等待研发处理,获取的效率低下。
口径获取效率低下:研发同学常常有了解口径的诉求,一样不知道去哪里查看。
解法:提供统一的获取指标与口径的门户,进一步可以初步实现自动化的需求分析。
业务决策:缺乏有效的工具和方法论支撑。
问题:
不知该用哪些指标:不知如何使用指标,不知哪个指标能反应真实的业务效果,不知如何分析业务的北极星指标是啥?
不知如何影响指标:不知道有哪些措施和行为能影响指标。
解法:需要提供丰富的数据应用,与有效数据方法论。
可以看到大部分沟通无非两件事
告诉我口径!:PHA轻应用是什么?应用数,DAU,可交互时长和研发效率数据都是怎么定义的?来源UV怎么计算??
把指标给我!:指标在哪里?具体Sql逻辑是啥?
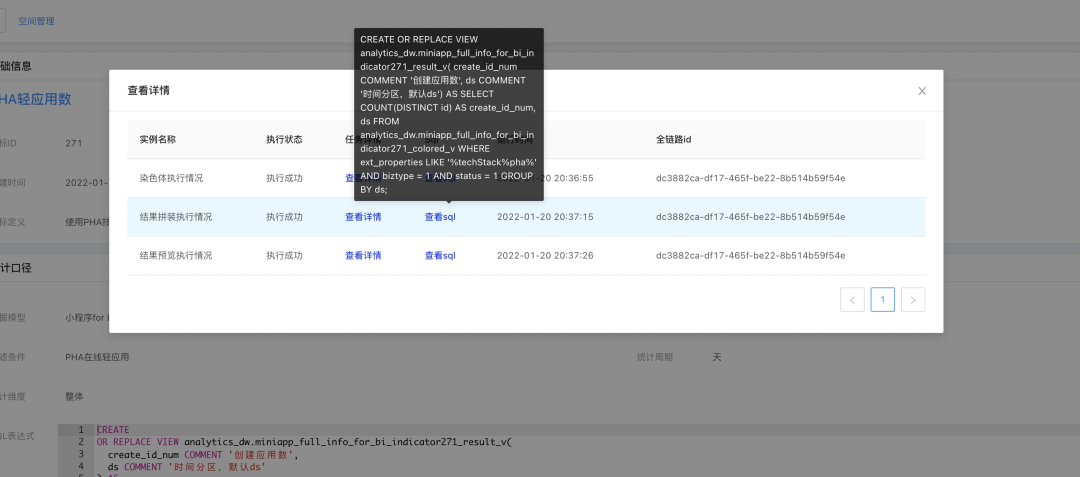
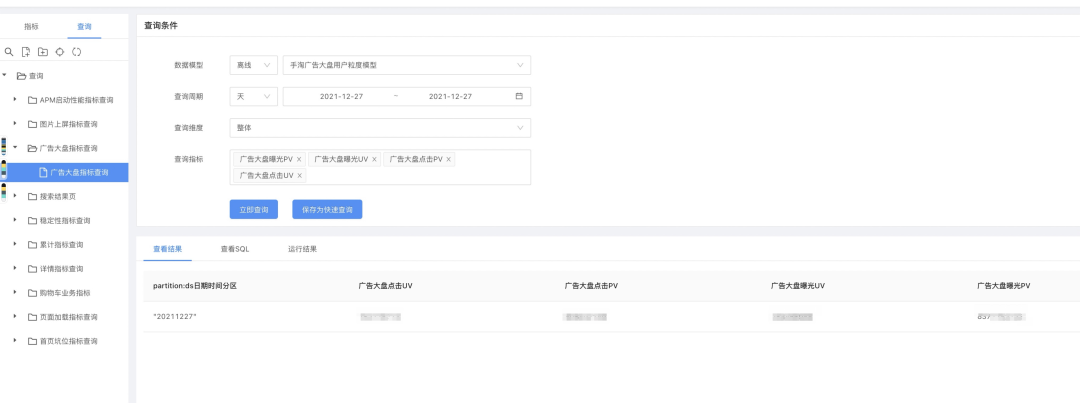
通过平台自动化生成后,可以通过如下方式自行获取:
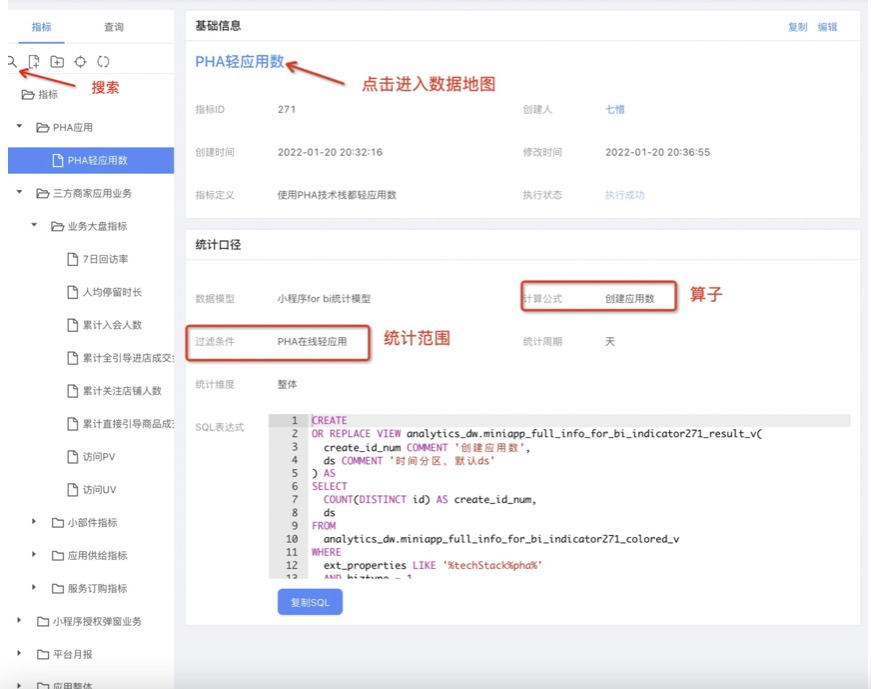
除了Sql表达式直观明了外,还能在元数据管理中查看每个配置的含义(当然目前交互联动还做的不够好,人不够呀)。因为指标是通过各配置直接生成的,所以也可以保证口径与数据是强一致的。
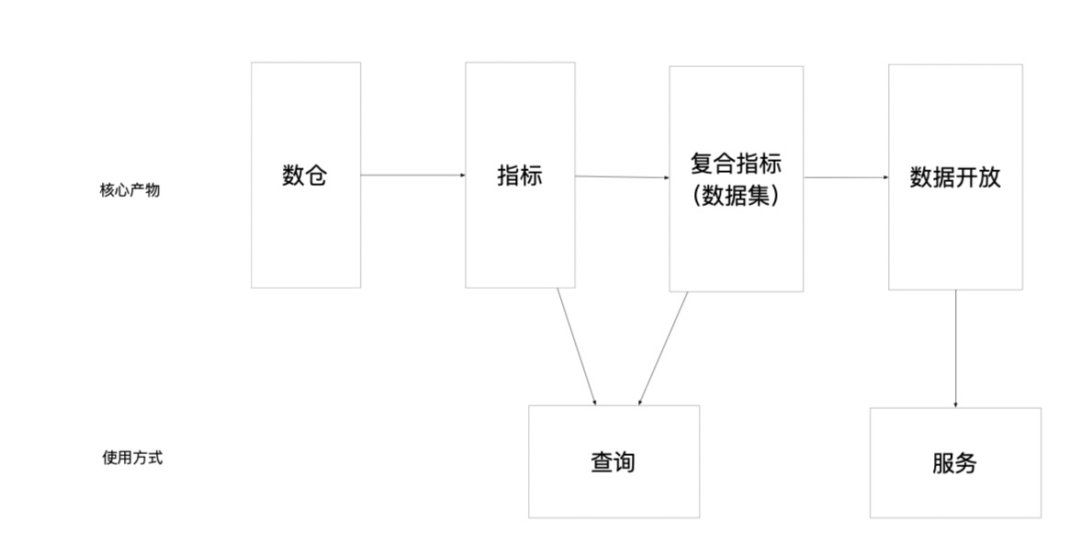
至此可以回答一下数据平台到底要做个啥?: 核心是通过标准化的数仓分层建设,利用平台自动化的生产,管理和交付数据(知识)。并沉淀算子,统计范围,维度等数据资产。
业务视角上:将统一通过基础数据平台生产和获取指标,查询口径,并与其他系统进行联动。只要有一点Sql基础的运营/PD等都能自助配置出新的指标,打破纯研发纯人肉生产指标的瓶颈。这就是所谓的“高度自动化&体系化的知识管理系统,重构知识的供给模式”。
不知道各位理解了没有。对于要做什么,我就介绍这么多了......下面来大致介绍一下核心能力的具体落地方案。
三 数据平台核心技术简介
回到技术上,我们的能力建设也是围绕这4点去搞。

1 知识生产—数据自动化生产能力建设
核心流程概览:
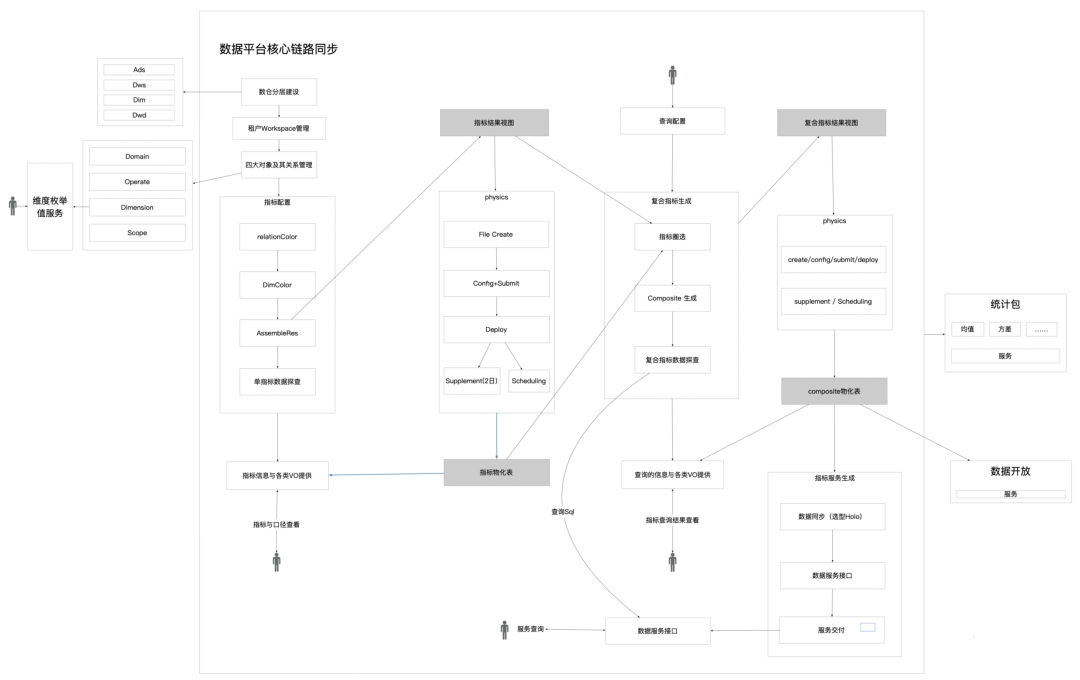
指标的生成(5步)
1)数仓分层建设(kimball维度建模-星型模型):
事实:以明细为粒度进行数据域拆分,如2001浏览域,2101点击域,2201曝光域,交易域,来源去向域,业务统计域,其他业务域等等。
维度:录入相关的Dim维表
2)关系染色RelationColoring
明细事实表和维表的主键关系。
3)维度染色DimensionColoring
动态填充需要的维度字段(非全量冗余,可以灵活适应维表的变更)
通过RelationColoring & DimensionColoring可以完全屏蔽了复杂的关联操作Join。
4)结果组装AssembleIndicator
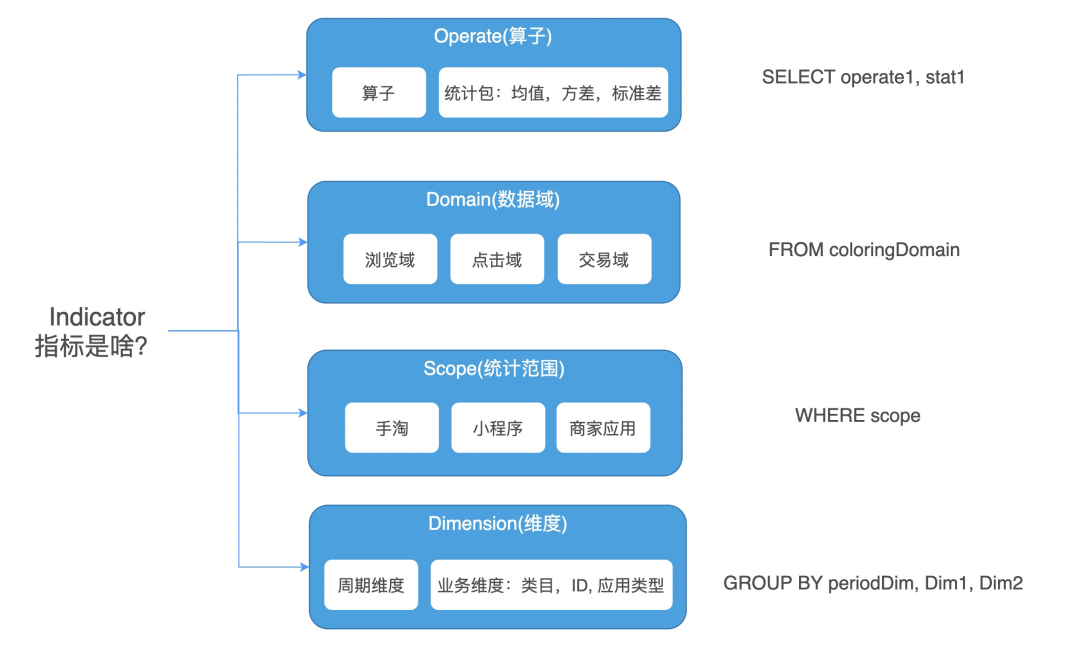
标准Sql生产:CREATE VIEW AS SELECT “Operate算子,stat统计包” FROM “ColoringView染色视图” WHERE "Scope统计范围" GROUP BY "PeriodDim周期维度 & Dim业务维度"。
5)数据探查IndicatorResult
起Odps任务 SELECT * FROM Indicator WHERE dim LIMIT xxx; 得到结果后存入缓存,便于用户进行数据探查。
复合指标生成(3步,将多个单指标融合成单一报表)
1)指标圈选
2)复合指标生成
可以理解成将多张表合并为1张。这一直是难题,因为普通报表在生成之时就丢失了所有的过程逻辑,即使存下来的也只是工程端无法规模化解析的非结构化信息。 而平台自动化生成的指标就刚好解决了这个问题。这也让指标合并成为了可能。
维度能力:
多指标交&并集处理
维度圈选能力(黑白名单)
多维cube:
精确维度组合:
维度缺省值处理(处理cube后数据异常膨胀和整体维度统计值因null失准的问题)
事实字段为Null处理
各类型字段的默认缺省值设置。
维表字段为Null处理
Left Join 维度缺值导致的Null处理。
指标拼接:
行 -> 列 -> 行 (行存转列存,分离出算子详细Name与Value. 再列存转行存生成可用的大宽表)
3)数据探查
指标物化&服务(依赖OpenDataworks的开放能力,注意申请流程和QPS)
文件创建
视图转表Sql生成
配置+提交+部署
调度运维
外表同步

核心挑战:性能
性能是自动化指标产出的难点,也会是之后的亮点。我们希望通过平台生成指标的效率能最大程度的接近开发人员手动优化的性能。当然这往深了做,是一个可以无限探索下去的领域。 拿平台来讲,目前最大的瓶颈在多维分析的支持,我们支持了维度的全量Cube,而想要更好的性能则需要去配置精准的Grouping Sets,而这又会大大增加前台页面的配置成本,如何权衡呢?是用针对高级用户提供独立的高级配置还是什么方法? 我们也还在进一步探索。
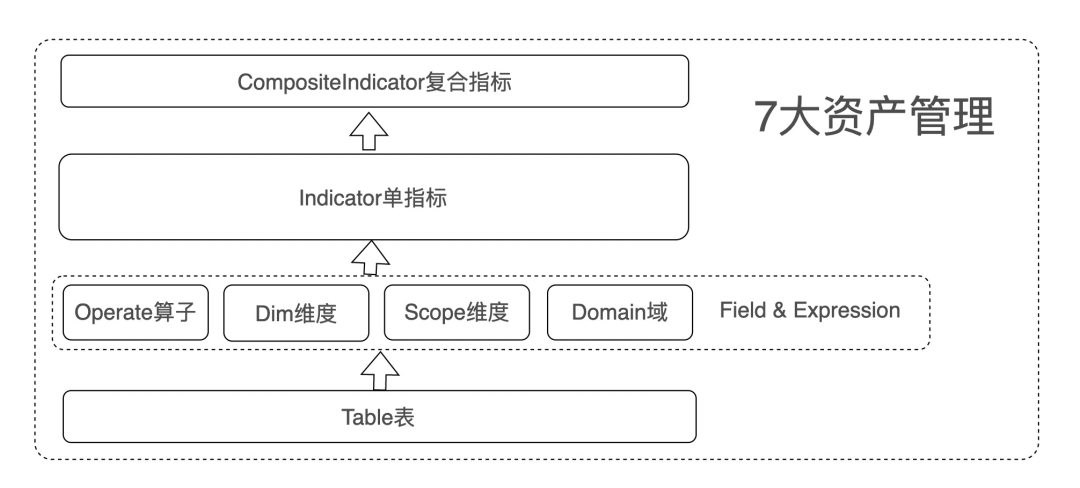
2 知识供给—资产管理能力建设
7大资产管理:
1)指标2个:
CompositeIndicator 复合指标 :
Indicator 原子指标
2)元数据5个:
Operate 算子
基础算子
stat统计包(均值,标准差,方差)
Dim维度
Dim(业务维度)
PeriodDim(周期维度)
Scope 统计范围
Domain 数据域/数据模型
Table 基础表
多租户管理:
空间管理
工程配置
Odps配置
Dataworks配置
Holo配置等
人员管理
资产隔离 (开发中)
权限管控
元数据权限
文件权限
视图权限
表权限等
数据能力管理:
即席查询
数据开放
开放接口
指标与其口径详情查询
指标变更消息
3 知识获取:统一的知识获取门户(设计中)
这块我认为非常非常重要,是可以用小成本撬动平使用体验的大幅提升,也有可能成为平台核心入口。应该在能力建设的同时,重点开发的方向。但是吧!这块目前还没有具体的产品形态,我有一些初步的设想和方案,后续和产品一起设计后最终方案再具体补充:
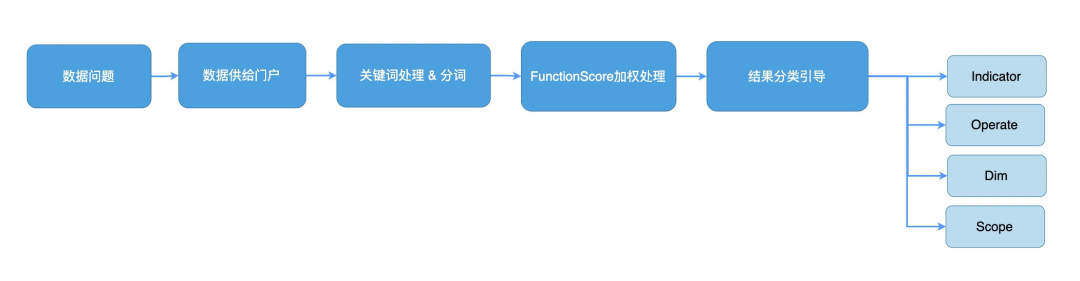
我希望设计一个统一的门户页面,当任何用户有口径问题和数据需求时,可以先到该页面进行对应的关键词的搜索。平台通过智能识别,返回给用户具体指标,算子,统计范围和维度的推荐信息。有指标能直接用最好,没有也可以根据口径信息自行配置所需的指标。
技术侧:平台数据资产同步到至搜索引擎,当然还有三个核心处理技术点处理一下1:关键字提取与分词规则 2:搜索结果FunctionScore加权 3:结果分类引导。
4 业务决策:有效的工具和知识使用方法的方法论支撑
说实话,优先级上,还没到这块的轮次。 因为业务千变万化,也许这就是个伪命题。 不过从技术侧来看,业务决策功能是属于应用层的范畴,搭建好了底层基础,上层的千变万化都是能灵活快速的进行支持的,我们将一边夯实基础,一边与业务方一起探索具体等场景。
5 其他:
关于优化:我认为几个比较核心的优化方向 1、知识门户 2、指标管理与元数据的联动 3、核心链路运维与逆向流程 4、性能。
关于能力供给:平台本身目前只针对内部白名单进行使用,等我们打磨到自己满意了会进一步开放。 当然设计之初核心能力与应用层就是解耦的,所以也有可能之后会将核心能力以SDK的形式进行开放,各业务方按需进行形态的建设。敬请期待~
四 小结
技术细节还有很多很多,篇幅限制,这里就大致介绍一下核心要做的事情。能完成一个Idea的探索,并有机会和大家分享进一步思考探索优化落地,还是挺有成就感的,也收获颇丰,起码从一个纯JAVA工程同学成为了数据Project的独立Owner。当然平台目前仍处于做大做深的阶段,距离能力健全,体验优秀还有很长很长的路要走(需要很多的人力去堆)。
都说数据越开放,产生的价值越高。所以平台虽然还稚嫩,但我对平台的价值坚信不疑,大家一起继续打磨,继续加油。
参考资料
《泛化建模& 维度建模》:https://www.aisoutu.com/a/919936
《数据,信息,知识,智慧分析与对比》:https://blog.sciencenet.cn/blog-39263-703361.html
《阿里云各类开放文档》:https://help.aliyun.com/document_detail/175553.html?spm=a2c4g.11174283.6.1296.386f2b65FoogOr#title-1sy-s0n-5f9




