基于Tablestore Tunnel的数据复制实战

前言
数据复制主要指通过互联的网络在多台机器上保存相同数据的副本,通过数据复制方案,人们通常希望达到以下目的:1)使数据在地理位置上更接近用户,进而降低访问延迟;2)当部分组件出现故障时,系统依旧可以继续工作,提高可用性;3)扩展至多台机器以同时提供数据访问服务,从而提升读吞吐量。
如果复制的数据一成不变,那么数据复制就非常容易,只需要将数据复制到每个节点,一次性即可搞定,面对持续更改的数据如何正确而有效的完成数据复制是一个不小的挑战。
使用DataX进行Tablestore数据复制
表格存储(Tablestore)是阿里云自研的NoSQL多模型数据库,提供海量结构化数据存储以及快速的查询和分析服务,表格存储的分布式存储和强大的索引引擎能够提供PB级存储、千万TPS以及毫秒级延迟的服务能力。DataX是阿里巴巴集团内被广泛使用的离线数据同步工具,DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件。
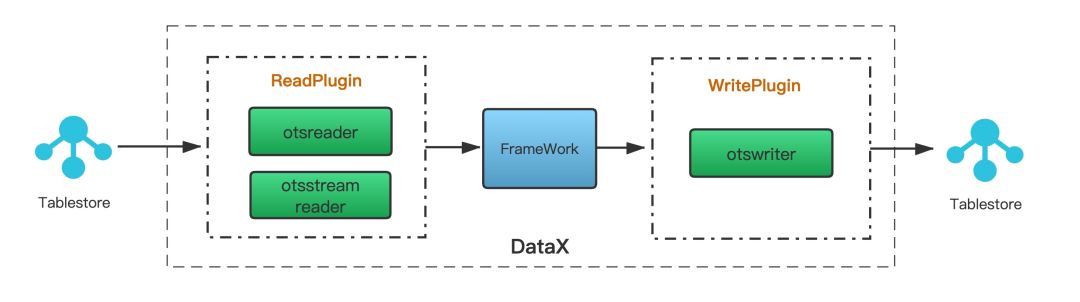
通过使用DataX可以完成Tablestore表的数据复制,如下图所示,otsreader插件实现了从Tablestore读取数据,并可以通过用户指定抽取数据范围可方便的实现数据增量抽取的需求,otsstreamreader插件实现了Tablestore的增量数据导出,而otswriter插件则实现了向Tablestore中写入数据。通过在DataX中配置Tablestore相关的Reader和Writer插件,即可以完成Tablestore的表数据复制。
使用通道服务进行Tablestore数据复制
通道服务(Tunnel Service)是基于表格存储数据接口之上的全增量一体化服务。通道服务为您提供了增量、全量、增量加全量三种类型的分布式数据实时消费通道。通过为数据表建立数据通道,可以简单地实现对表中历史存量和新增数据的消费处理。
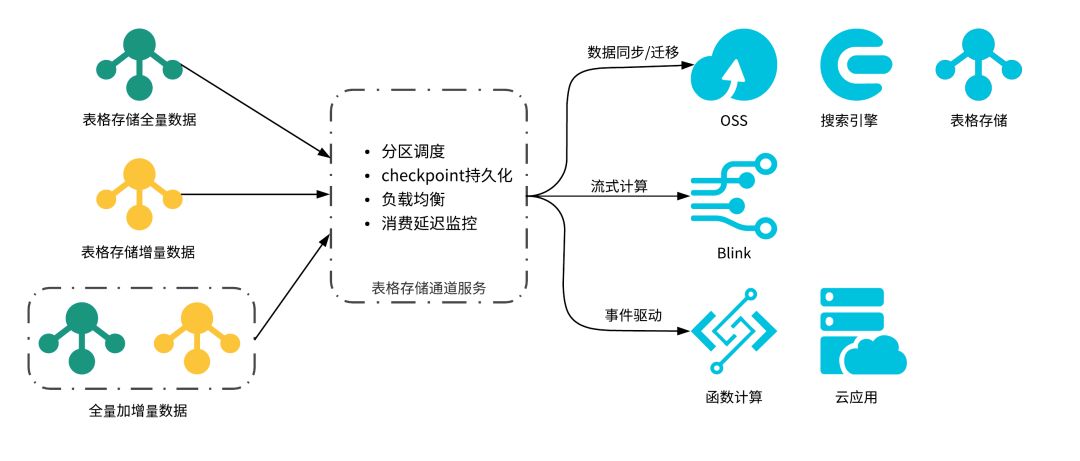
借助于全增量一体的通道服务,我们可以轻松构建高效、弹性的数据复制解决方案。本文将逐步介绍如何结合通道服务进行Tablestore的数据复制,完整代码开源在github上的 tablestore-examples中。本次的实战将基于通道服务的Java SDK来完成,推荐先阅读下通道服务的相关文档,包括快速开始等。
1. 配置抽取
配置抽取其实对应的是数据同步所具备的功能,在本次实战中,我们将完成指定时间点之前的表数据同步,指定的时间点可以是现在或者未来的某个时刻。具体的配置如下所示,ots-reader中记录的是源表的相关配置,ots-writer中记录的是目的表的相关配置。
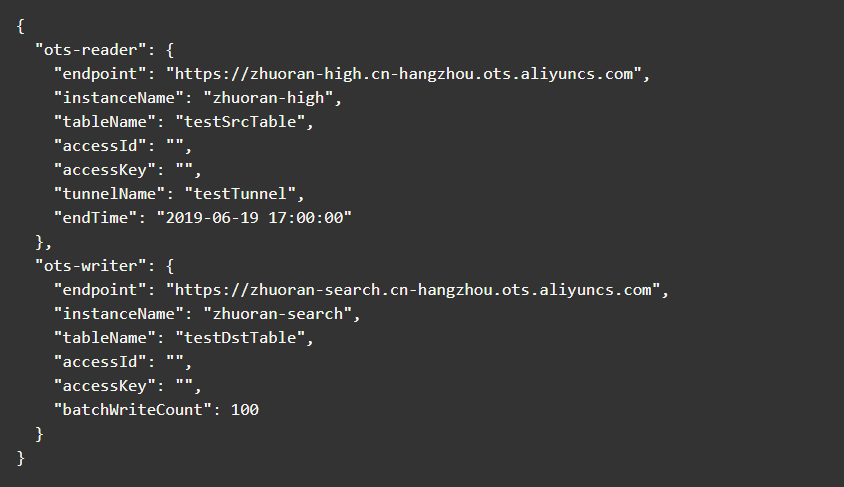
ots-reader中各参数的说明如下:
endpoint: Tablestore服务的Endpoint地址,例如
https://zhuoran-high.cn-hangzhou.ots.aliyuncs.com。
在进行数据复制前,请检查下连通性(可以使用curl命令)。
instanceName: Tablestore的实例名。
tableName: Tablestore的表名。
accessId: 访问Tablestore的云账号accessId。
accessKey: 访问Tablestore的云账号accessKey。
tunnelName: Tablestore的通道名,配置
endTime: 数据同步的截止时间点,对应到Java里SimpleFormat的格式为:yyyy-MM-dd HH:mm:ss 。
ots-writer中各参数的说明如下(略去相同的参数):
batchWriteCount: Tablestore单次批量写入的条数,最大值为200。
注:未来会开放更多的功能配置,比如指定时间范围的数据复制等。
2. 编写主逻辑
数据复制的主逻辑主要分为以下4步,在第一次运行时,会完整的进行所有步骤,而在程序重启或者断点续传场景时,只需要进行第3步和第4步。
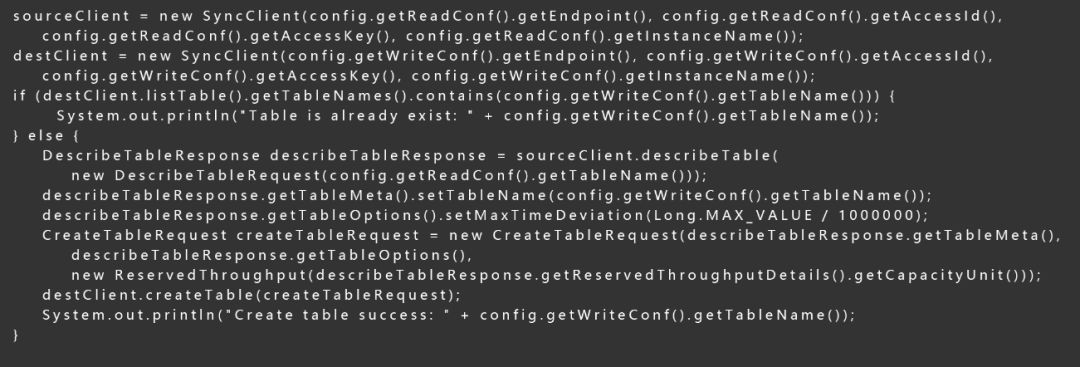
1、创建复制目的表
通过使用DesribeTable接口,我们可以获取到源表的Schema,借此可以创建出目的表,值得注意的是需要把目的表的有效版本偏差设成一个足够大的值(默认为86400秒),因为服务端在处理写请求时会对属性列的版本号进行检查,写入的版本号需要在一个范围内才能写入成功,对于源表中的历史存量数据而言,时间戳往往是比较小的,会被服务端过滤掉,最终导致同步数据的丢失。
2、在源表上创建通道
使用通道服务的CreateTunnel接口可以创建通道,此处我们创建全量加增量类型(TunnelType.BaseAndStream)类型的通道。

3、启动定时任务来监测备份进度
备份进度的监测可以通过DesribeTunnel接口来完成,DescribeTunnel接口可以获取到最新消费到的时间点,通过和配置里的备份结束时间对比,我们可以获取到当前同步的进度。在到达结束时间后,即可退出备份程序。
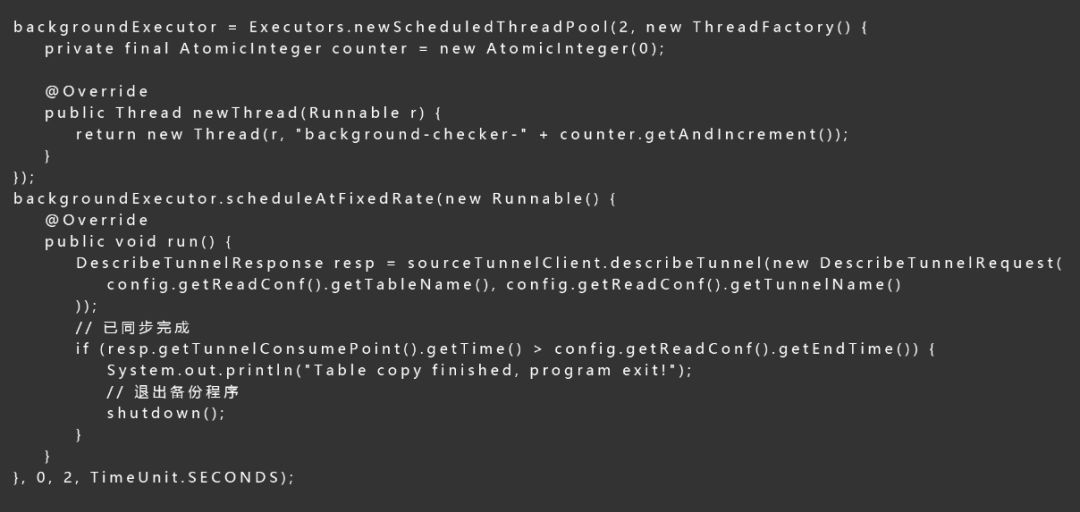
4、启动数据复制
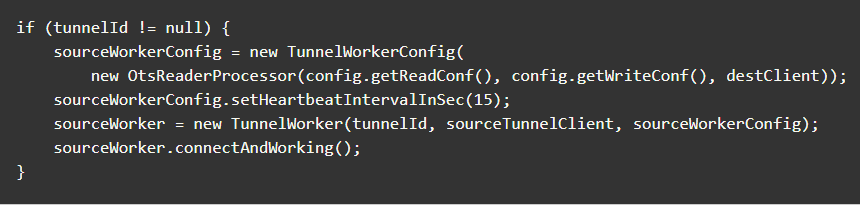
启动通道服务的自动化消费框架,开始自动化的数据同步,其中OtsReaderProcessor中完成的是源表数据的解析和目的表的写入,处理逻辑将会在后文中介绍。
3. 数据同步逻辑(OtsReaderProcessor)
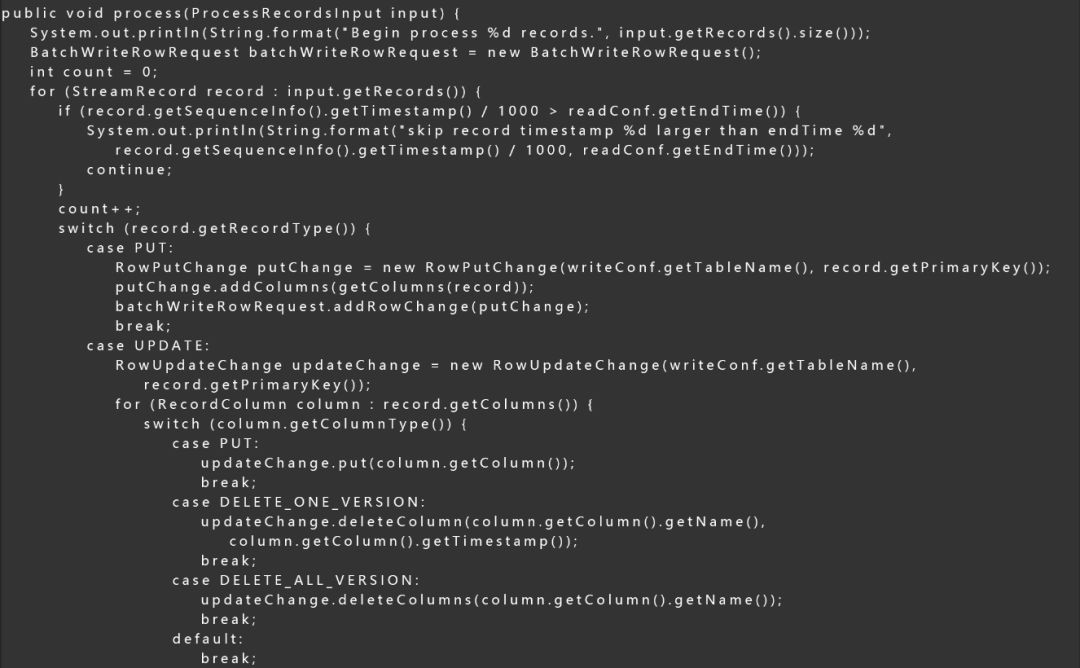
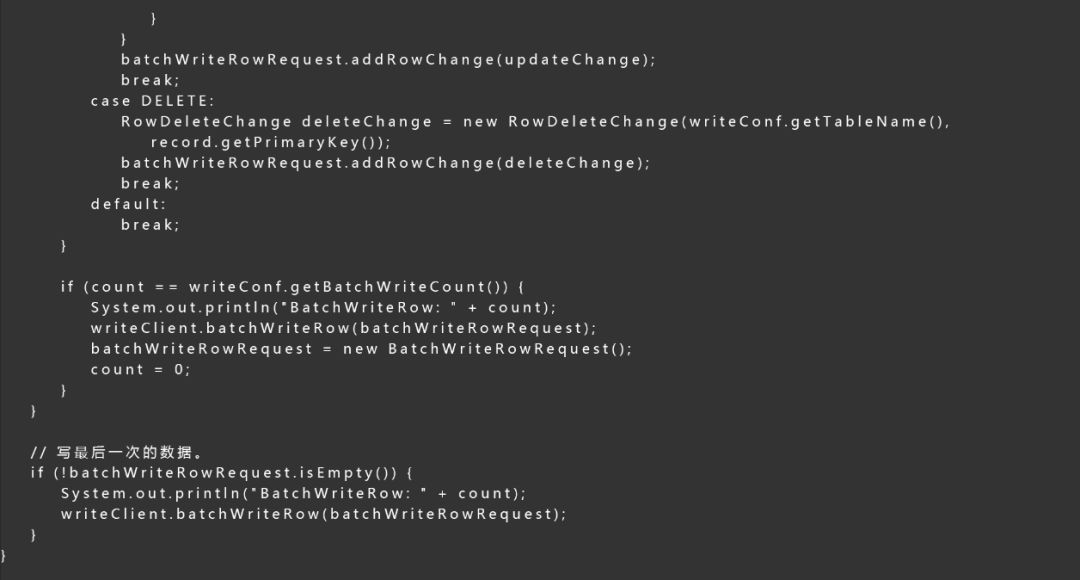
使用通道服务,我们需要编写数据的Process逻辑和Shutdown逻辑,数据同步中的核心在于解析数据并将其写入到目的表中,处理数据的完整代码如下所示,主要逻辑还是比较清晰的,首先会检查数据的时间戳是否在合理的时间范围内,然后将StreamRecord转化为BatchWrite里对应的行,最后将数据串行写入到目的表中。
4. 技术注解
如何保障备份性能?
备份过程分为全量(存量)和增量阶段,对于全量阶段,通道服务会自动将全表的数据在逻辑上划分成接近指定大小的若干分片,全量阶段的数据同步的整体并行度和分片数相关,能够有效的保障吞吐量。而对于增量阶段,为了保障数据的有序性,单分区内的数据我们需要串行处理数据,增量阶段的性能和分区数成正比关系(增量同步性能白皮书),如果需要提速(增加分区)可以联系表格存储技术支持。如何做到数据同步的水平扩展?
运行多个TunnelWorker(客户端)对同一个Tunnel进行消费时(TunnelId相同), 在TunnelWorker执行Heartbeat时,通道服务端会自动的对Channel(分区)资源进行重分配,让活跃的Channel尽可能的均摊到每一个TunnelWorker上,达到资源负载均衡的目的。同时,在水平扩展性方面,用户可以很容易的通过增加TunnelWorker的数量来完成,TunnelWorker可以在同一个机器或者不同机器上。更多的原理可以参见数据消费框架原理介绍。如何做到数据的最终一致性?
数据的一致性建立在通道服务的保序协议基础上,通过全量和增量数据同步的幂等性可以保障备份数据的最终一致。如何完成断点续传功能?
通道服务的客户端会定期将已同步(消费)完成的数据的时间位点定期发送到服务端进行持久化,在发生Failover或者重启程序后,下一次的数据消费会从记录的checkpoint开始数据处理,不会造成数据的丢失。
未来展望
在本次的实战中,我们结合通道服务完成一个简洁而有效的数据复制方案,实现了指定时间点的表数据复制。借助于本次的实战样例代码,用户仅需要配置源表和目的表的相关参数,即可以高效的完成的表数据的复制和数据的迁移。
在未来的演进中,通道服务还将支持创建指定时间段的通道,这样可以更加灵活的制定数据备份的计划,也可以完成持续备份和按时间点恢复等更加丰富的功能。
参考文献
Desiging Data-Intensive Applications.
更多精彩


Feed流系统设计-总纲

如果觉得本文还不错,点击在看一下!
点此进入抢购2019杭州云栖大会门票!



