NVIDIA何琨:AI视频处理加速引擎TensorRT及Deepstream介绍
主讲人 | 何琨 英伟达
陈铭林 编辑整理
量子位编辑 | 公众号 QbitAI
近日,爱奇艺技术沙龙“多模态视频人物识别的关键技术及应用”成功举办,英伟达开发者社区经理何琨出席并作出精彩分享,以下为分享实录:

今天,我给大家介绍两个工具,分别是DeepStream和TensorRT。我想给大家介绍这两个工具,并不是因为它们是针对于特定的产品或场景,而是因为这两个工具真正能在视觉领域帮助大家加速一些任务或者应用程序。
DeepStream
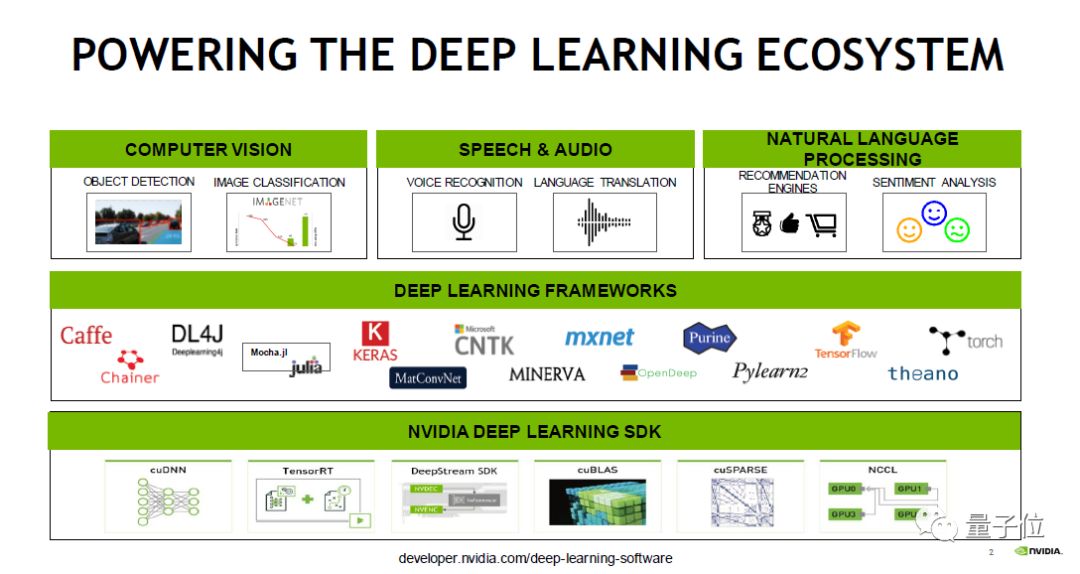
深度学习应用在很多领域,如视觉、语音、NLP等,有各种各样的学习框架,在深度学习框架底层,NVIDIA提供了大量的硬件以及相关的软件库的支持,包括cuDNN、DeepStream、TensorRT、cuBLAS等基础库,这些库都是让程序运行起来更快的基础生态工具。
DeepStream是基于NVIDIA运行的工具,它主要应用于视觉整个流程的解决方案,它跟其他视觉库(比如OpenCV)不一样的地方在于,它建立一个完整的端到端的支持方案,换句话说你的源无论是Camera、Video还是云服务器上的视频,从视频的编解码到后台的图像Inference再到展示出来的画面的完整pipeline上的各个细节它都能帮助大家,包括参数的设置。
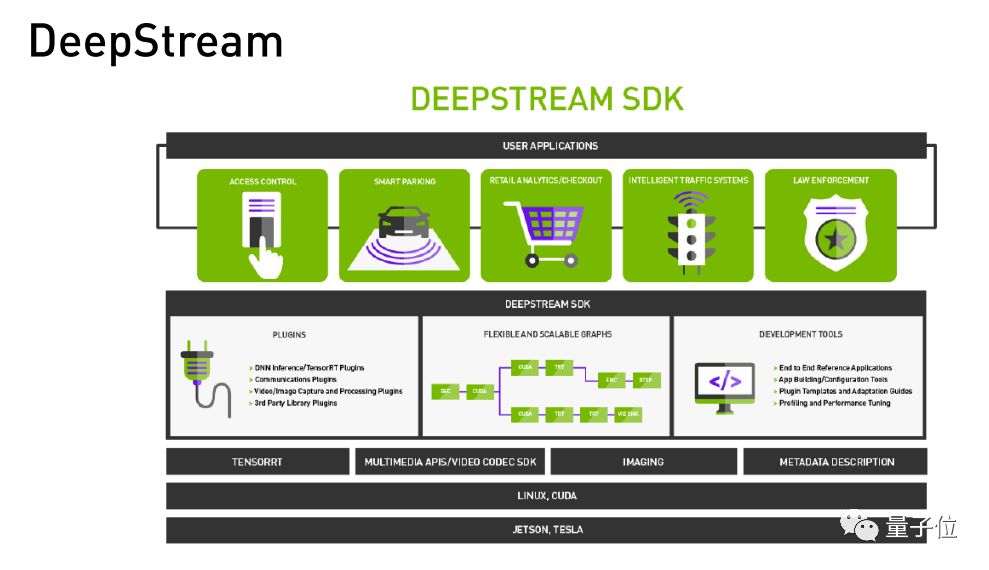
在这个过程中,大家只需要加上自己的内容。比如视频检索,我们需要train出一个model来识别或检测其中的人脸,将这几个不同model添加到里面就好了。而视频源的设置完整流程DeepStream都可以帮你做好,包括记录的视频、服务器上多路视频。
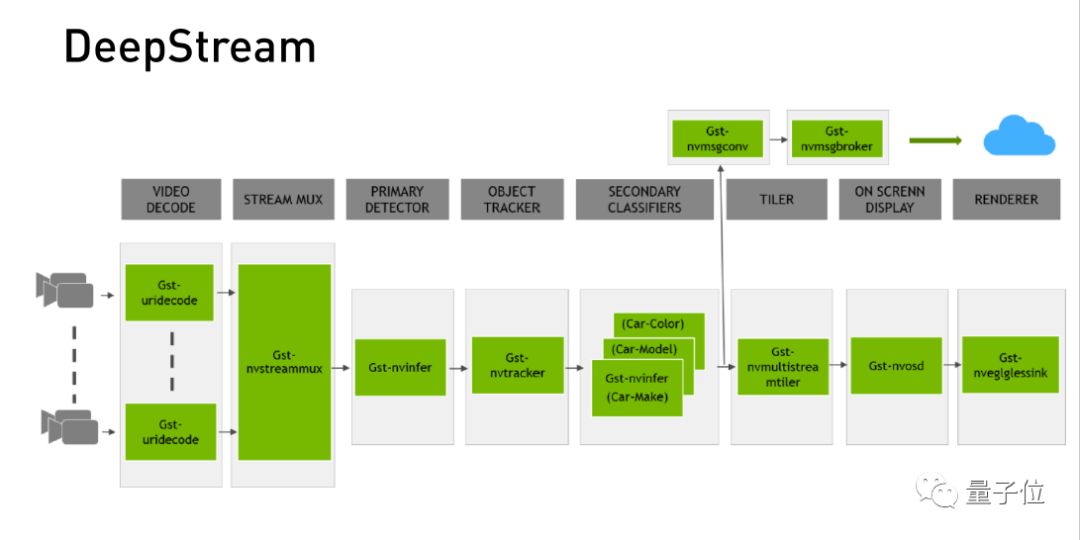
在这过程中,DeepStream是如何去做的?我们可以看到,从最开始的视频的编解码,到整个流程地完成,这个过程中有两个东西是最重要的,一个是Gstreamer编解码工具,一个是TensorRT工具。在AI中它是一个加速GPU的推理引擎。DeepStream中,视频的编解码就是依靠Gstreamer,而内容的Inference过程中就用TensorRT来实现的。

可以看到每一个模块是用什么样的硬件设备来跑的,因为有一些可能还用到了CPU,但更多用到GPU的加速。特别地,有些情况下我们需要在计算能力有限的设备上,如小尺寸的GPU设备、无人机或者自动驾驶汽车等,我们需要加速一个完整的流程时,DeepStream也可以帮助我们这样的事。
DeepStream现在支持NVIDIA的Xavier系列、Tegra系列和最新出的Nano系列等产品,在这个过程中用一些GPU调度的情况下,比传统视觉库的加速效果要好很多。
举两个例子,现在跑的是一个大家耳熟能详的模型,就是Yolo v3的,它跑在我们的Tegra的产品上,只有不到半个手掌大的计算芯片设备,我做了一个目标检测任务,前提是Batch Size我都设为了1,因为在那样Memory的情况下,如果Batch Size设为更多,比如2或者4的话,如果不用DeepStream的话它是跑不了的,Out of Memory了。

我们可以看一下左上角,这个是没有用DeepStream和TensorRT产品来优化的,结果是大概一帧一秒的过程。而右下角使用了TensorRT或DeepStream来做优化,大概是四点多的范围。
就是说在相同的一个算法上,我们在Batch Size都设置为1的情况下,速度提升比大概是四倍,这种情况下,我们不需要做任何的优化,不需要修改网络模型,不需要改数量级,只需要把模型给到DeepStream或者TensorRT就可以做速度加速比。
GitHub上有一个非常好的开源代码,利用DeepStream在GPU上进行加速的一个案例,推荐给大家:https://github.com/vat-nvidia/deepstream-plugins。
DeepStream还支持一些新的特性。比如一个服务器上要接很多路摄像头,这种情况要接很多路Pipeline。比如汽车上,在停车的时候需要启用后端的摄像头,这时需要Create新的Pipeline;在自动行驶的过程中,为了避撞,汽车两边的摄像头的精度需要更多的关注,这时DeepStream会自动管理或删减Pipeline。当然还根据自动驾驶提供的360度摄像头全景拼接,在需要使用的时候直接include库就可以了,非常简单方便。

TensorRT
说到DeepStream,除了视频的编解码以外,最核心的内容就是推理工具,推理是深度学习真正把模型部署到产品中非常重要的一部分。DeepStream的底层推理任务基于TensorRT,核心任务是GPU推理引擎。它是一种高性能深度学习推理优化器和运行时加速库,调用的时候直接include,可以优化神经网络模型以及其他功能。

后面画出这些图表是TensorRT当前的Performance一个优化的程度,这个是4.0版本,最新数值还要更高。我们什么都不需要做,只要用这个工具来Inference这个模型就OK了,可以达到这样一个高度。
而随着最新的TensorRT 5.0的推出,对于python的支持,对于NLP、RNN等基于时间序列的模型的支持也都非常好,特别是还有基于移动端类似于无人机、无人车等平台。
TensorRT有一个标准的Work Flow,给它一个训练好的网络模型(包括网络结构、权重参数),它会自动进行优化,而在这个优化完成后会生成一个可执行的推理引擎,只要把需要推理的数据实例,如图片、语音信息、文字等内容直接给它,它就可以加速你的模型推理。
而在模型推理过程中,我们需要它自动做这五件事:

第一个是权重参数类型的优化,比如目前半精度和八位整形的推理,如果当数据的大小或位宽减少之后,数据传输、计算、配合最新的Tensor Core等硬件结构做推理时,整体速度会提升很多。
接下来是动态的Tensor Memory。做视觉的同学应该都接触过GPU,GPU里边有很多level级的 Memory,Global Memory、Share Memory等,如何把数据从低速度带宽到一个高精度的Memory,这些TensorRT都可以做到。
接下来是多流的执行。GPU最大的特点是并行计算,并行计算一个新的Level,除了不同的多个线程、Block以外,还有不同的Stream,多流的执行可以帮你隐藏数据传输的时间。例如把一个大块数据放到GPU里进行inference时,数据传输时所有的计算核心都需要等待,等待的时间就浪费了,或者GPU的使用率降低。
这个时候我们要把一大块数据切分成不同的小块进行计算。第一块数据在传输的时候,后面所有任务都在等待,当第一块传输完了之后第二块开始传输。与此同时,第一块数据开始计算,就可以把传输时间隐藏在计算时间里了。
大家做一些基于视觉应用时,一个服务器可能要同时开N个实例。比如一个V100,16G Memory,ResNet-50需要1.3GB的GPU Memory。这时一个GPU可以同时开12个实例,每个示例对应一定的摄像头,这样管理这些GPU资源的时候能充分利用。
然后还有内核调用。不同产品的内核,它的核多、核少、不同的核的大小,或者寄存器的个数,它会自动优化到每个kernel里。
最后是网络层的融合。TensorRT不会改变或者裁剪网络层,但它可以帮我们做一些优化。
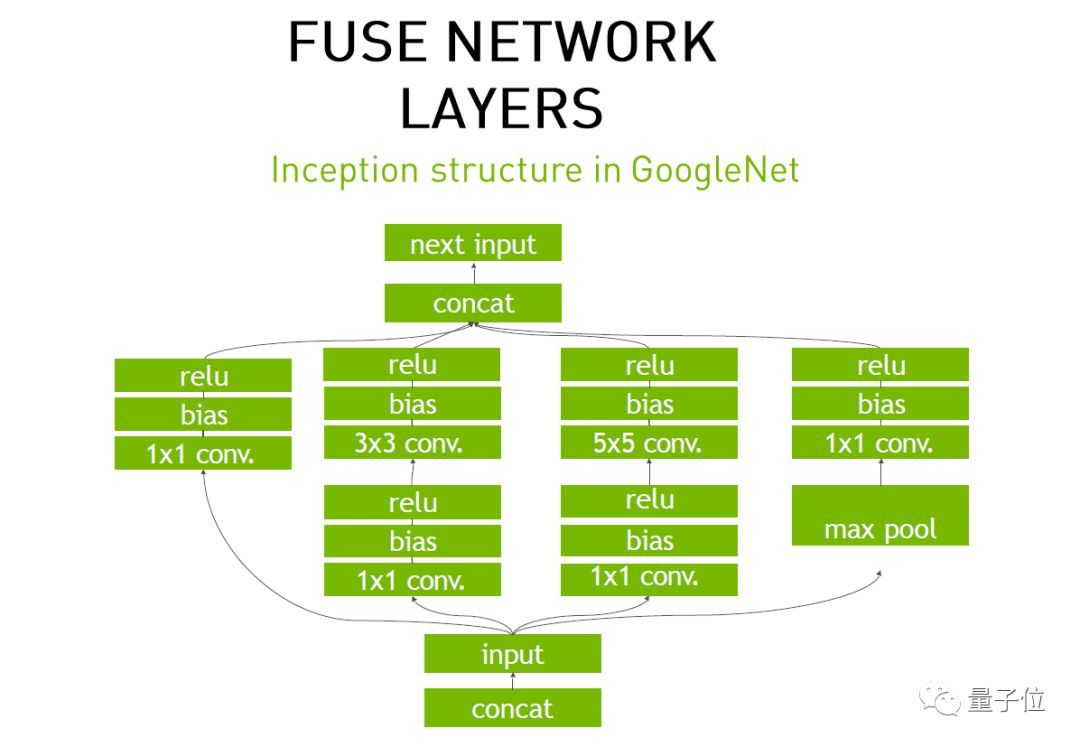
上图是大家比较熟悉的GoogleNet Inception结构,首先我们可以看到有很多个网络层,比如类似于Caffe或者TensorFlow等底层代码,它调用一个网络层时,会把上一层的Tensor数据拿来传到这个函数里,如果你做GPU优化,它会把这个数据放到GPU进行计算,GPU计算完成后再返回给CPU。每个网络层都是同样的过程。
或者说你把整个的网络层的数据全都Load到GPU里,GPU会把它放在Global Memory里,然后使用时会把它调到每个Kernel或SM多流处理器里。在这过程中,每一层都是“写-计算-读”。我们可以把三个网络层进行融合,CBR,是Convolution、Bias、ReLU的缩写。
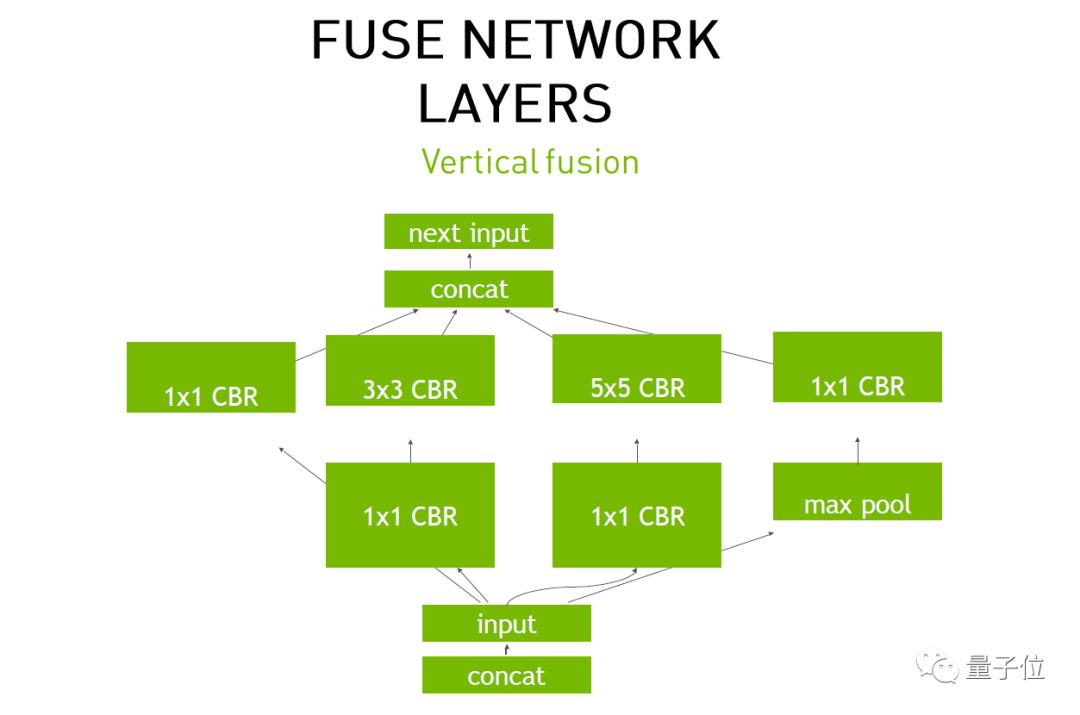
这样有什么好处?如果当前Memory足够Load数据之后,把这三个网络层融合到一起,就能够节省四次的访存次数。随着网络层越来越深,网络层的读写次数越少,加速时间就会越来越多。
除了上面的融合之外,我们把三个1x1 CBR还可以融合在一起,因为它们进行相同的操作。同时自动拼接也可以省掉,因为GPU里计算完就直接执行了,可以直接消减掉。
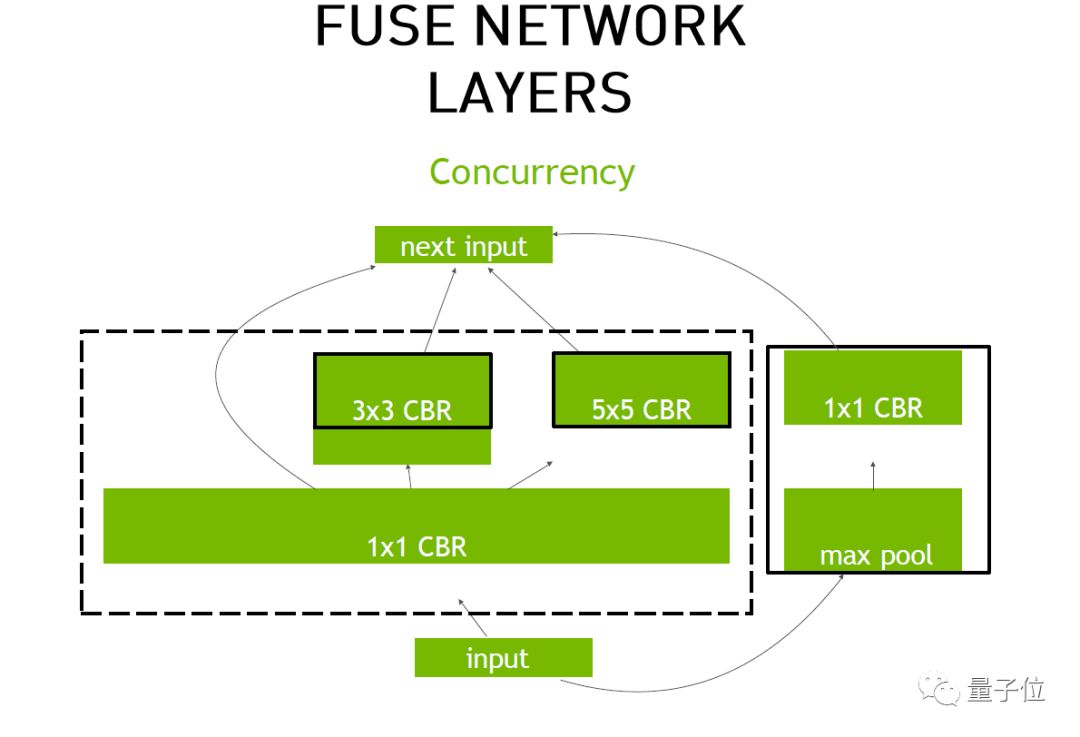
最后,可以看到这个过程中,这个两条线彼此之间是并不相关的,数据之间没有相互的交流。我们可以单独启动两个Stream,分别走这两条线。
就是把左侧两个数据来计算的同时,同时计算第三块数据,也就是把需要时间较少的那一部分隐藏到另一部分的时间里,当然这都是TensorRT帮我们完成的。

TensorRT在整个过程中支持了网络层,使用TensorRT的时候,需要把训练好的数据或网络模型给到TensorRT工具。通过ONNX的操作,TensorRT基本上支持了现在市面上常见的网络框架训练出的模型,Caffe、TensorFlow、ONNX、DarkNet的数据都是可以的。
最后介绍一下英伟达开发者社区:https://developer.nvidia-china.com,大家有什么问题可以在上面提问,谢谢大家。
— 完 —
小程序|get更多AI学习干货

加入社群
量子位AI社群开始招募啦,量子位社群分:AI讨论群、AI+行业群、AI技术群;
欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“微信群”,获取入群方式。(技术群与AI+行业群需经过审核,审核较严,敬请谅解)

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !



