开源神经网络框架Caffe2全介绍

本文作者吴逸鸣,整理自作者在GTC China 2017大会上的演讲,首发于作者的知乎文章。
我个人认为这是一份很值得分享的资料,因为
这应该是第一次使用全中文来讲解Caffe2和FB的AI应用的演讲
观看这次演讲不需要机器学习/神经网络,甚至计算机科学的基础。它适合每一个愿意了解人工智能、神经网络和Caffe2的人。
我准备了很久!(这才是主要原因哈哈哈,但第一次上台还蛮紧张)
在观看视频前你可能需要注意以下几点:
该视频所有权解释权各种权全都归英伟达所有(点击阅读原文查看演讲视频)
此次演讲只是谈论了我自己的一些看法,和FB无关
我的演讲稿和视频里说的可能有一些出入。有的地方为了更好地让大家理解,我做了自己的解释。演讲稿中有可能有的地方我懒得写但是我在演讲中说了。有的地方是因为我理解不够直接是错误的。还有各种错别字。这些都欢迎大家指正,互相学习。
以下是演讲原文:
大家好 我叫吴逸鸣。我来自Facebook的Caffe2组。
演讲开始前,想先给大家看一个demo。这是一个自动把图片和视频转换成大师美术风格的神经网络算法。在大约两年前刚被发表的时候,在服务器上处理单张照片需要秒级别的时间。到现在,我们已经成功做到实时的视频风格转换。不仅实时,在我们同事的努力下,我们还做到了在手机移动端本地实施演算。这相较于之前,已经有好几个量级的效率提升。
今天,我想给大家介绍一下让这一切变成现实,以及将各种AI算法部署到产品中的神经网络框架:Caffe2。
Caffe2是:
一个轻量化的深度学习算法框架
caffe2 主要为产品级别的深度学习算法设计
为移动端实时计算做了很多优化
同时支持大规模的分布式计算
Caffe2是一个跨平台的框架
支持移动端iOS, Android, 服务器端Linux, Mac, Windows, 甚至一些物联网设 备如RaspberryPi, NVIDIA Jetson TX2等平台部署
说到这里,我们需要暂停一下。深度学习框架是什么?若放在五年前,你甚至很难用这六个字造句。Caffe2是什么?你们会不会给咖啡拉花?这些问题别说外行,很多科技企业的内行包括一些我的学长、别的部门同事也会有这些疑惑。
简单来说,从我个人的理解,深度学习,作为机器学习的一个分支,是一个寻找理想中的函数fx的过程。这个函数代表了从数据输入x到期待输出y的某种映射。在深度学习里, 这个函数是多层有叠加的。在这里你的输入x可以是一些图片,可以是音频,可以是一些高纬度的向量用。函数的输出y可以是推荐系统的排位、另一种语言的翻译或者是无人车对下一秒操作的决策。
深度学习,和别的AI的算法,要为社会创造价值,还得落到产品中去。在工业界,我们训练和部署深度学习算法的时候,通常有以下几个环节
你有数据
你有模型
你想要找到那个神器的函数fx。这个不断尝试和逼进的过程,我们称为训练
你可能需要在移动端/服务器端/物联网设备/嵌入式系统上部署你的神经网络算法
那么Caffe2作为一个神经网络框架,为你提供了模型搭建、训练、和跨平台的部署。简而言之,全包办了。
在设计开发Caffe2中,我们认为一个好的经的起业界规模考验的神经网络框架需要具备:
支持最新的计算模型
分布式训练
高模块化
跨平台的支持
高效率
今天我想大家展示一些Caffe2的例子。谈一下在FB我们如何用Caffe2来搭建我们的AI产品。
在FB,我们使用Caffe2来搭建全套的AI产品和功能,其中包括
计算机视觉相关
机器翻译
语音识别
推荐系统
首先是移动端的Caffe2
从设计之初,Caffe2就十分重视在移动端部署神经网络。我们一直在优化Caffe2在移动端的性能,并保证我们能支持各类移动计算框架。现在Caffe2主要为15年以后的机型优化,但也支持13年以后的机型。
为了在手机上这里是一个使用OpenGL在iOS和安卓设备上加速的例子。通过我们在移动端的努力,原本在CPU上每秒只能处理4帧的算法,利用手机端的GPU,我们实现了24+fps每秒的效果,实现了实时计算修改。

我们和高通合作一起在搭载了高通芯片的移动端设备上加速神经网络。这是一个移动端图像识别的例子,可以看到在移动端,不仅是神经网络风格变换算法,图像分类算法也可以做到超过实时的演算。

在这些移动端的样例背后是我们在各种设备上的优化。在苹果设备上,我们是第一个完全把Metal,也就是iOS的GPU API完全融合到后端的框架。如果你是一个移动开发者,准备好自己的模型后,通过简单几行调用,你就可以让你的神经网络在苹果设备上用GPU运行起来。
使用Caffe2移动端的GPU实现可以给你的网络带来实质性的加速和能耗上的优化
这一切都是开源的。

在安卓设备上 我们用OpenGL来使用GPU加速神经网络的执行。这之中我们有一整套基于OpenGL的GPU底层运算实现。CPU只需调度,无需处理数据。

在部署产品的时候,有时用户终端设备只有CPU的硬件支持。我们对arm架构的CPU有Neon(一个并发指令集的拓展)的实现。我们也维护开发调用自己的开源CPU高性能运算库NNPack。我们也会做Caffe2编译文件的压缩来保证把AI添加到你的产品不会成为空间上的负担。
总而言之,Caffe2提供了从入门机到旗舰机的一整套移动部署解决方案。

另一个我想分享的Caffe2案例是我们的机器翻译系统。
在我们的产品中,我们有来自世界各地的超过20亿用户。为他们提供高质量的翻译,是一个一个很复杂的问题。左边的图上是一个从土耳其语翻译到英文的例子。上半部分翻译的不好,在英语里是不流畅的。下半部分翻译的好。可见翻译的质量、支持语言类型的数量至关重要。在FB,如果中文到英文和英文到中文算两种翻译的话,每天我们需要提供2000多种翻译。处理45亿条翻译请求。今天,我们可以很骄傲地说,这一切底下的算法和服务,都是由Caffe2支持的。
在这个项目中我们使用了seq2seq LSTM model with attention。这是现在业界主流的翻译模型。
我们使用Caffe2做大规模的训练,并在GPU/CPU上都对相应的计算做了优化。

在这些优化中,最值得一提的是我们对循环神经网络的内存优化。循环神经网络的单元,英文里称之为Cell,往往需要把自己的输出,当作自己的输入,循环执行。所以,我们称之为循环。在真实实现的过程中,这就好比把同样的单元展开很多遍。这种计算的模式,使得循环神经网络的计算量很大。要处理2000+种翻译方向,计算量更是有量级上的增长。
优化循环网络的计算显得极为重要。Caffe2为循环神经网络提供了:
反向运算时的展开单元内存重用
替换内存中部分参数的空间,当需要的时候再重新计算参数
专门正向推导模式提供进一步的内存空间优化
对于多层的循环神经网络单元,他们展开后会在计算图中形成一个运算单元的阵列。
我们尽可能地依照对角线的方式执行这些运算来尽可能达到最大的并行化。
在这些优化之后,我们把我们产品中的循环神经网络效率提高了2.5倍。达到了20亿用户级别的训练和部署要求。

更值得兴奋的是,我们从上个月开始开源了我们的循环神经网络支持。开源社区和在座的每一位也可以开始用Caffe2来优化你的循环神经网络。从框架本身,调用Caffe2的循环网络引擎对性能几乎没有影响。Caffe2支持主流的循环神经网络单元包括LSTM,Multiplicative Integration LSTM(这是一种在单元里面加上乘法的更复杂的LSTM单元)和带attention的模型等。之前我提到的内存和正向推导时的优化,都已经开源。

和翻译相关的一个例子是语音识别,在fb,和语音相关的应用有以下这些。
1.自动语音识别
顾名思义,这项任务中输入是一段音频,输出可以是对应的文字,可以是一连串的音标等。Caffe2提供了自动语音识别中非常常用的双向LSTM单元,Caffe2支持CE和 CTC这两种算法,并且对他们做了速度上的优化。这两种是现在ASR,自动语音识别中主流的输出和真实标注(真实句子)之间差异性的方法。
2.语音合成
刚才的自动语音识别是从音频到文字。语音合成,是从文字,合成一段听起来像人讲话的音频。一般语音合成现在有用多层神经网络实现的,有用LSTM实现的、有用卷积神经网络实现的。我们生成的模型回去模拟声音的音长,频率,峰值和声音的间歇性。
我们还有一些别的声音上的应用,在这里由于时间的原因,不做过多的展开了。

那么,到现在,我们已经通过在FB的例子讲述了Caffe2在手机端的部署,包括移动端CPU,移动端GPU的优化,这样来支持从低到高各种类型的机型。
我们介绍了我们在自然语言处理领域, 也就是我们机器翻译的成果。Caffe2对循环神经网络做了许多优化,使得我们训练的模型经受起了45亿级别的单日访问量的考验
我们也介绍了在语音领域,包括ASR、TTS实现的各种模型,说明Caffe2对于不同模型都有良好的支持。
但是接下来,我想给大家分享的,是任何一个工业级的机器学习框架都需要解决的应用场景——分布式训练。
这项工作的名称,叫做 ImageNet in 1 hr,中文叫做1小时完成ImageNet挑战。这项工作是由我们以下的同事一同完成的。

ImageNet是一个由斯坦佛大学主导的大型开源图像数据集。ImageNet挑战是一个经典的计算机视觉挑战。在这项任务中,我们的模型需要做图像分类,也就是说,给它一张图片,他需要告诉我这是猫还是狗还是飞机还是船还是汽车。
如果罗列一些简单的数据:
1. 使用当前主流的图像识别模型,单张图片大概要做80亿次浮点数计算
2. 在ImageNet数据集中大约有120万张图像
3. 为了训练出一个现在学界认可的模型,我们大约需要把这120万张图片给我们的模型看100遍
4. 如果做一下简单的计算,我们完成这项任务需要用到1个exa个浮点数计算。exa有多少呢?大约是10的18次方,是Giga往上走3级。这个任务的计算量,真的很大。
在这项任务里,我们把本来需要好几天的训练量,用1个小时的时间训练完了。而且我们用的是全开源的软件框架,深度学习用Caffe2,网络调度同步用我们开源的gloo,硬件就是你也能买得到的英伟达的GPU。
好,那我们来自习地介绍一下这项任务。我们要在ImgeNet-1k数据集上做图像分类。这其中ImageNet-1k 的图像有一千种类别。每一张图片只有一个类别训练数据集,像我之前说的,有120万张图片。验证集中有5万张图片。我们在机器学习中,我们会单独拿出一些数据作为验证集,来调整一些模型的参数,或者监控一下模型训练的好不好。我们在训练的过程中也需要跑这5万张图片的正向推导。

输入的格式是NCHW -》输出是1 hot label的形式。现在学术届在这个数据集上最领先的是我们FB的同事 kaiming大神的工作:rextnet,大概达到了22%的训练错误率。也就是说,给模型看100张来自ImgeNet训练集的图片,他期望上能说对其中78张图片的类别。相较于2012年AlexNet横空出世时的36-40的top1 error rate,我们深度学习的研究者已经有了很大的进步。
在这项任务中,我们把单次处理的数据量上升到8192张图片。这在机器学习的层面会带来一些挑战,在接下来的ppt中我会提到。另外,我们在单次训练中我们同时使用了256块GPU,搭建这样一套系统也充满了挑战。
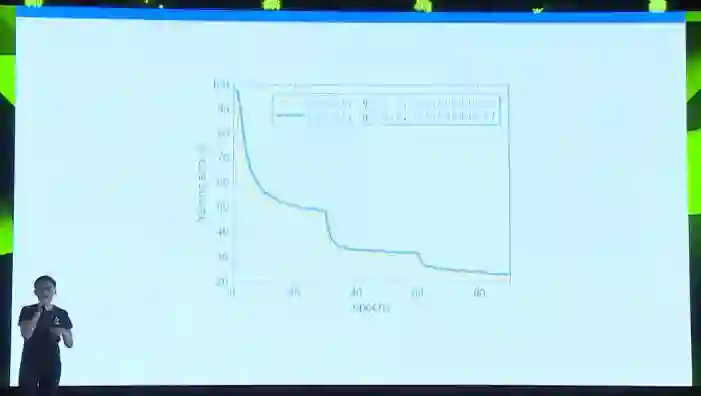
在训练神经网络的过程中我们关注训练上的错误率。这里是一张训练错误率随着训练的数据增加而下降的图。我们可以看到y轴是训练的错误率,这个数值越低说明我们的模型能够在训练集数据上分类得更准确。X轴是数据的期的数量。一期(Epoch)数据指的是我们的模型把训练数据完全过一遍,在imagenet-1k的任务中大概100万张图片。我们可以看到,橘黄色的线是一个标准的训练resnet50曲线。大概经过了90期数据后,训练精度达到了20出头。这条橘黄的线可以算一个基准,我们的目标就是去逼近这条黄线。

因为我们期待能够在分布式的机群上做数据并行的训练,意味着我们单次处理的数据量要远大于标准的256张图片。那么假设我们直接把单次处理的数据量增加到8192张,会发生什么呢?我们就得到了蓝色的训练曲线。在大约90期数据后,模型的训练错误率大约停在41%左右。这两者之间的差距很大。蓝色的训练曲线完全不达标。(但值得一提的是,在一个1000类的分类任务中,如果我们只有一个随机分类器,我们的训练错误率大概在99.9%左右。这个模型虽然和我们心中标准差了很多,但他显然是具备一点关于这些图像上分类的知识的)
之前有一些工作,包括李沐学长的文章里,都提出过通过同比例放大学习效率(learning rate)来应对大批量的数据的想法。我们也尝试了相应的做法,得到了新的蓝线。新的训练参数中,因为我们把同批数据量从256放大了32倍到8192,所以我们把学习效率从原来的0.1放大到3.2 。可以看到训练错误率有了很不错的提升。从之前的41左右的错误率下降到24.84左右。这个结果虽好,但和我们期待的目标还有大约1%的差距。不熟悉图像分类的人可能会问,这1%的差距也追求,会不会太苛刻了?其实在1000类的图像分类里,如果把分类结果打印出来,这1%的差距有时在有些类别上会显得特别明显。
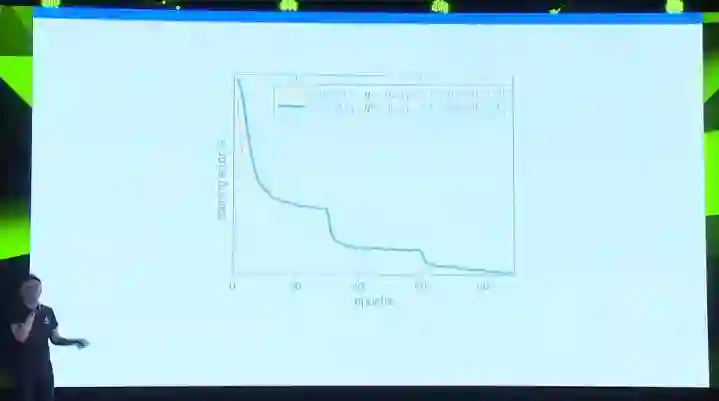
那么经过我们同事的一番探索,在一番努力后,我们找到了一种循序增大学习效率的办法,使得分布式的训练曲线和我们目标的标准训练曲线收敛在一样的训练错误率上。我们总结了一系列在大规模分布式上训练神经网络的经验,更多的内容可以到我们的论文中查看。
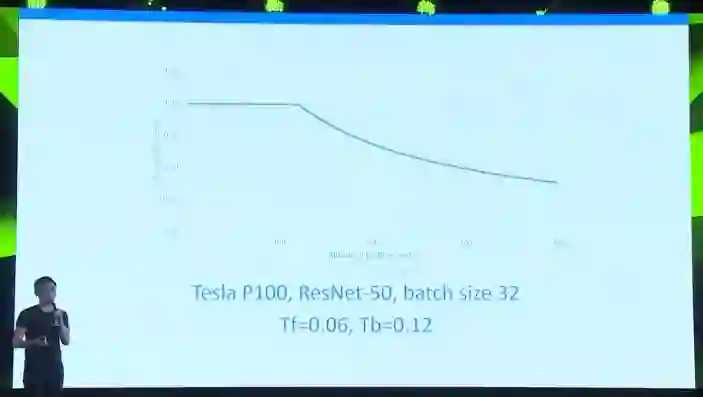
说完了机器学习理论上的困难和解决方案后,我们来说一说这项工作中在系统方面的挑战。之前提到过,在一块英伟达Tesla P100上ResNet-50的训练数据吞吐量大约是230张每秒。
为了训练出一个比较理想的模型,之前的收敛图表也显示了,我们大概需要把整个数据集处理100遍。

那么120万张图片过100次是1亿2千万张图片,按照230张图片每秒的速度,训练一个resnet-50模型需要6天。
这时我们就不得不开始使用分布式训练。也就是用大规模机群来完成训练算法。
这里给大家展示了一张分布式训练的简易说明图。每一个虚线的方框代表一张GPU或者一台机器。方框之间用PCIe或者网线连接通讯。在这项工作里我们使用数据并行的训练方法。数据并行指的是每个机器/GPU同时处理不同的数据,并且在完成后做运算结果的总和同步。在这张图里,每个batch代表了小批的数据。我们把batch 1到k都放在k个机器上分别处理。在真实的例子里,一小批数据有32张图片,k=256,这样就做到一次处理8192张图片,也就是我们之前理论得到的单次大批数据量。说完了图片中的输入Input,我们把输入放到方程中,也就是我们用Caffe2搭建的ResNet-50模型。注意在这k台机器上每一台都有函数参数的一套拷贝。我们同时在这些GPU/机器上调用模型方程,得到分类器的输出,以及关于真实数据标注的逻辑回归损失。在这张图里就是结果Result。
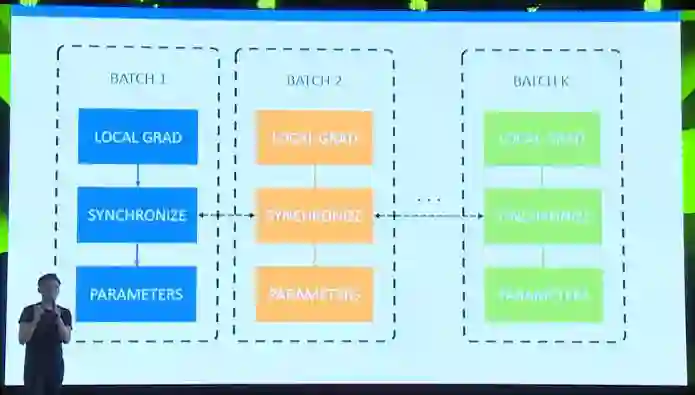
上一部我在每台机器上得到了模型在所有数据上的逻辑回归损失。那么利用Caffe2提供的自动求导功能,我们可以针对本地的数据算出我们的模型在这些数据上的本地导数, local grad。那么下一步呢?下一步如果我们像普通的机器学习训练算法直接把导数加到本地的参数上,那么我们就变成了同时训练k个模型了。这和我们的目标不符合,我们的目标是训练一个好的模型,这个模型需要把所有数据看100遍。所以我们需要先同步(synchronize)所有机器上算出来的导数,得到一个统一的导数,再作用到每分本地参数拷贝上。
在数据并行的分布式训练中,同步一直是最重要的一环。在我们的这次训练中,我们使用的是一种叫做全相加的同步方式。也就是把每个机器算出来的导数,全都加在一起。这里用P来代表,也可以用G,指代更加清楚。

一个信息:ResNet-50一共有2千5百万个参数需要算导数并同步。那么在计算机里,大约是100MB的大小。这在今天这个时代,听起来不是什么海量数据。
这里需要提出一个概念:同步效率。这个指标代表了同步给系统带来时间延迟有多少。

他的分子上是两项时间的相加。Tf代表在神经网络正向运算的时候消耗的时间,Tb代表反向运算的时间。这两项时间相加代表了在假象的完美的0同步时间系统中训练需要的时间。分母上第一项依然是正向时间Tf,第二项是反向时间和同步时间的最大值。同步时间由我们需要传输的数据量M除以系统带宽B得到。之所以在返乡时间和同步时间取最大值是因为神经网络参数反向运算是有序的。在算完了反向第一层的参数导数后我们就能开始同步。
理论上在这个效率是100%的时候,同步不会对训练系统带来任何延迟。效率越高,同步给系统带来的延迟最少。
如果我们把实际的数据带入到上一页的公式中。在Tesla P100上resnet单次处理32张图片,正向时间大概是0.06秒,60ms,反向时间120ms。那么如果我们这个系统想要达到50%的同步效率,也就是理论上起码一半的时间在做主要的训练工作,我们必须得在200ms中完成256台机器的本地导数全相加同步。这时候,100MB看起来就很多了。
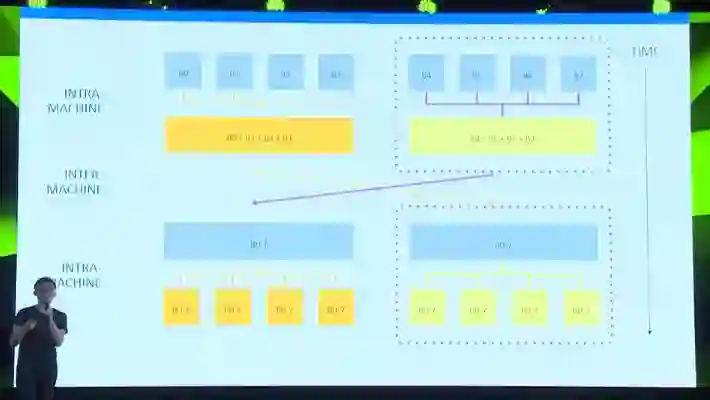
针对同步我们做了很多优化。比如我们做了多层次的同步。我们会在第一步先在机器本地把GPU们的数据做一次全相加。在图里比如左上方,就是把四张GPU卡的数据合并。第二步我们通过互相拷贝做机器间的全相加同步。第三步我们把计算出的统一数据再在机器内部分发到所有GPU上。
还有一个值得一提的优化。我们研究了resnet中出现的参数的大小。 这张图是一张resnet中参数大小及其数量的图表。横轴是参数大小,纵轴是参数的数量。我们可以看到左半边是小参数,右半边是大参数。
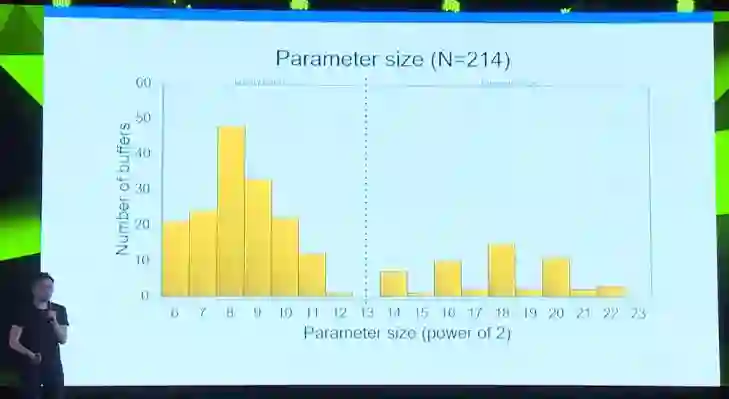
我们发现大的参数和小的参数在同步的时候表现出不同的性质。小参数我们称为latency bound, 延迟限制的参数。这类参数的同步过程中,同步的时间很短,主要的时间在等待别的机器的运算结果。针对这类参数,我们实现了树形的参数同步算法,能够最快地同步这些参数。大的参数通常是bandwidth bound,带宽限制的参数。这类参数的同步时间很大。我们针对这类参数实现了环状的同步算法。尽可能地减少同步次数并尽早开始同步过程,更充分利用带宽。
在这项工作中我们还做了很多别的如数据读入,GPU通讯的优化。我们也开源了我们的分布式训练通讯框架Gloo。由于时间的原因,在这里我们不能更多展开了。有兴趣的朋友可以来参考我们的论文。
今天的演讲讲了很多,总结一下。
Caffe2是一个工业级的高拓展性高性能的神经网络框架。在CPU端,我们调用我们开发的高性能CPU库NNPACK。在移动端,我们有包括iOS Metal,OpenGL等一套底层实现。在分布式训练端,我们可以加载分布式通讯库Gloo并完成大规模分布式训练。另外,Caffe2完全开源,大家可以添加自己想要的更快的订制底层实现。

在开发Caffe2的过程中,我们经常被问到这个问题:你们和原来的Caffe有什么区别?总结下来有以下这些区别。

1.Caffe2有更好的规模拓展性。今天的演讲里也给大家加少了很多大规模训练的例子,比如翻译,比如imagenet-1k in an hour。这些大规模训练的例子都已经在Facebook级别的数据量和系统上经过了实战检验。
2.Caffe2对手机端移动部署神经网络有一整套支持。比如今天我们提到的手机端实时风格变换。这是原来的Caffe做不到的
3.是模块化。Caffe2是一个高模块化的神经网络框架。我今天也展示了我们和Gloo,和NNPACK,和Metal等一系列其他代码/业务逻辑的整合样例。Caffe2可以更好的融入到业务逻辑中去。
总而言之,Caffe2是一个跨平台的新型工业级神经网络框架。我们在移动端,服务器端,物联网设备,嵌入式系统都能部署Caffe2训练的模型。希望在不久的将来,Caffe2可以帮助大家在各种各样的设备上部署新的人工智能算法。






