ShuffleNetV2:高效网络的4条实用准则
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Nango 明楠
https://zhuanlan.zhihu.com/p/42288448
本文已由作者授权,未经允许,不得二次转载
2018年 清华大学&Face++ Ningning Ma
提出指导高效CNN网络设计的4种方案,并改进了shufflenetv1
论文: ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
arXiv:https://arxiv.org/abs/1807.11164
1. 背景介绍
在高效网络上(特别是移动端),网络必须在有限的计算能力中达到最优的精度。 目前很多论文研究着 轻量级架构设计和速度-精度的权衡。
比如Xception、MobileNet、MobileNetv2、ShuffleNet、CondenseNet等等。在这些有效的网络结构中,Group Convolution(组卷积) 和 Depth-wise convolution(深度卷积) 起到关键性作用。
1. 组卷积 Group Convolution:
将feature map拆分成几组,分别进行卷积,最后再将卷积结果的feature map 合并. 最早在AlexNet中出现。因为当时GPU内存有限,逼迫将feature map拆分到两个GPU上分别卷积再融合。
2. 深度卷积 Depth-wise convolution:
对每一个通道进行各自的卷积,输出相同的通道数,再用进行跨通道的标准卷积来融合信息。 Xception 就是典型的代表
3. 极大减少了参数,性能还有点提高(未知有无理论证明能完全替代普通卷积)。Alex认为组卷积实现类似正则的作用。
速度(Speed)是直接指标,但不同设备不好比较, 故以往常用 FLOPs(乘或加的次数)来度量复杂度。但FLOP是一种间接指标,它不能直接作为评判的标准(如Mobilev2和Nasnet相比,他们的Flops相似,但是前者快很多)。
个人体会:
在WRN和Resnet上,WRN的Flops和参数量远大于Resnet情况下,WRN比Resnet快很多。且ResNext比WRN慢很多。shufflenetv2论文中在两种硬件环境中测试四种不同速度和FLOPs的网络结构。观察知道FLOPs不能替代Speed这评判指标。
间接指标(Flops)和直接指标(速度)之间存在差异有两种:
1. 对速度影响较大的因素,但没有影响到FLOPs。
如内存访问成本(MAC, memory access cost),它在如组卷积中占大量运行时间,导致MAC是瓶颈。
又如并行度(degree of parallelism),FLOPs相同情况下,高并行的模型可能会快很多。
2. 运行平台不同。
相同的FLOPs的运算在不同的平台上运行也会导致速度差异。
如以前会采用张量分解来加速矩阵乘法,但张量分解在GPU上运行会慢很多。作者调查发现最近的CUDNN库中有专门为
卷积进行了优化,也就是说张量分解后的运行速度有可能慢与优化库中的张量乘法。

于是作者认为高效网络架构的设计应该考虑两个基本原则:
1 用直接指标(如速度)评估,而不是间接指标(如Flops)。
2 在同一环境平台上进行评估。
论文也是按照这两个原则,对多种网络(包括shufflenetv2)进行评估。
2. 高效网络设计的4条实用准则
作者发现 组卷积和深度卷积是目前较优网络的关键,且FLOPs数仅和卷积有关。虽然卷积操作耗费大量时间,但是其他内部过程如 I/O、data shuffle、element-wise操作(Add、ReLU等)都会耗费一定的时间。
作者提出设计高效网络的4条准则:
G1 相同通道宽度可以最小化内存访问成本MAC。
G2 过多的组卷积会增加内存访问成本MAC
G3 网络内部碎片操作会降低并行度
G4 Element-wise操作不容忽视
G1 相同通道宽度可以最小化内存访问成本MAC
考虑无bias的 



那么普通卷积的Flops数为

则 
tips:为这两层各自的输出值(activate),
为两层间卷积核的参数量。


则得出:

tips:![]()

上面不等式指出,同FLOPs情况下,如果相邻两层它们的通道数相等时,MAC将达到最小值。文中采用简单两层卷积网络,实验验证了这结果。
但是实际情况下G1的前提条件“cache足够大”不一定满足。设备缓存不够大时很多计算库会采用复杂的缓存机制,这会导致MAC值和理论值有偏差。
G2 过多的组卷积会增加内存访问成本MAC
组卷积能够大量减少FLOPs,也成功被应用于多种优秀网络。
延续G1中的符号定义及公式,此处的FLOPs为 
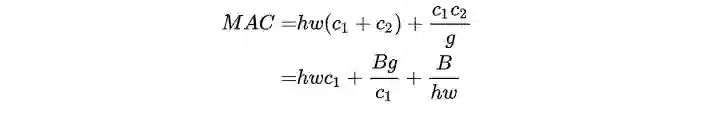
tips:,
![]()


从式子看出,若组卷积的组数 
文中采用控制变量法实验验证了这准则。
G3 网络内部碎片操作会降低并行度
碎片(Fragmentation)是指多分支上,每条分支上的小卷积或pooling等(如外面的一次大的卷积操作,被拆分到每个分支上分别进行小的卷积操作)。
如在NasNet-A就包含了大量的碎片操作,每条分支都有约13个操作,而ResnetV1上就只有2或3个操作。虽然这些Fragmented sturcture能够增加准确率,但是在高并行情况下降低了效率,增加了许多额外开销(内核启动、同步等等)。
文中采用控制变量实验验证了这准则。
G4 Element-wise操作不容忽视
Element-wise操作指的是 ReLU、AddTensor、AddBias等等。虽然这些操作只增加了一点点FLOPs,但是会带来很高的MAC,尤其是Depthwise Convolution深度卷积。
文中采用‘bottleneck’单元,进行了一系列对比实验,验证了这准则。
G1-G4的总结:
平衡相邻层的卷积核数
留意组卷积带来的开销
减少碎片化的程度
减少Element-wise操作
讨论其他的网络:
ShuffleNet-V1 严重依赖组卷积,违背了G2。
Bottleneck结构违背了G1
MobileNet-V2 采用了反转bottleneck(违背了G1),且用到了Depth-wise、以及在feature map上采用relu这些trick,违背了G4.
自动搜索生成的网络结构(如NasNet)有很高的碎片,违背了G3.
3. ShuffleNet V2 架构
基于上面种种分析,作者着手改进ShuffleNet V1。
首先ShuffleNetV1是在给定的计算预算(FLOP)下,为了增加准确率,选择采用了 逐点组卷积 和 类似瓶颈的结构,且还引入了 channel shuffle操作. 如下图的(a)、(b)所示。
很明显,逐点组卷积 和 类似瓶颈的结构 增加了MAC(违背G1和G2),采用了太多组卷积违背了G3, ‘Add’ 操作违背了G4,因此关键问题在于如何保持大量同宽通道的同时,让网络非密集卷积也没太多组卷积。
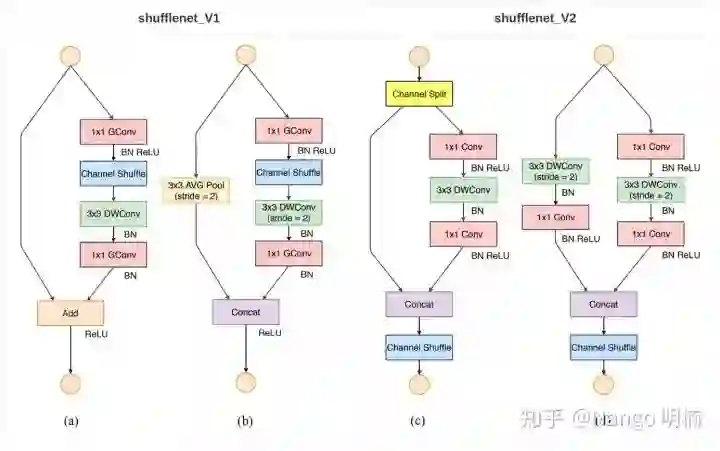
DWConv:深度卷积 (depthwise convolution), GConv:组卷积 (group convolution)
ShuffleNetV2 引入通道分割(channel split)操作, 将输入的feature maps分为两部分 

之后分支合并采用拼接(concat),让前后的channel数一样(满足G1). 然后再进行Channel Shuffle(完成和ShuffleNetV1一样的功能)。
shuffle后,以往的ShuffleNetV1是再接一个ReLu(Element-wise)操作,此处将其移到卷积分支中。 另外三个连续的Element-wise操作:通道分割、concat、shuffle合并成一个Element-wise操作,这满足了G4. 具体看图(c).
ShuffleNetV2 的空间下采样模块经过些修改,去掉了通道分割,输出的通道数翻倍。详情看图(d).
这是合理的做法,因为下采样后,feature map的尺寸降低了,通道数翻倍是自然的。
4. 讨论
ShuffleNet-V2 不仅高效,还高精度。论文中指出导致的原因有:
每个构建块都很高效,从而能利用更多的feature maps 和 更大的网络容量
特征重用(feature reuse)
因为通道分割,从而有一半(论文设置为
)的特征直接传到下一个模块中。
这和DenseNet 以及CondenseNet 思想相近。
DenseNet分析feature reuse模式发现,越相近的模块,它们的传来的shortcut特征的重要性越大。 CondenseNet也支持类似的观点。
ShuffleNet-V2也是符合这样的观点, 特征重用信息随着两个模块间的距离呈指数衰减。即
层的feature maps中,含有
层feature maps数为
,其中
为
层的feature maps数,
为通道分割的参数,论文设为
.







此篇论文实属业界良心,从源头分析每一步会造成的开销,从理论分析,到控制变量法做足实验,总结出 4 条准则,指导大家设计更高效的网络。
G1准则(相同通道宽度)从VGG、Resnet后大家几乎都默认遵循了, 而G2准则(组卷积问题)很多网络在违背着。主要是组卷积能够提高准确率,但很有意思的是,用了组卷积速度会慢很多,但直到shuffnetv2才开始分析原因(存疑,笔者没找到更早的关于组卷积会变慢的分析)。
而组卷积为什么会变好? “Alex认为group conv的方式能够增加filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。” 参考自对深度可分离卷积、分组卷积、扩张卷积、转置卷积(反卷积)的理解。https://blog.csdn.net/Chaolei3/article/details/79374563
至于G3准则(碎片操作),文中主要还是对 自主搜索网络结构 方面的工作(如NasNet 进行批判)。这或许可以在自主搜索网络结构方面加上相应的损失函数,从而让搜索出的网络结构除了高准确率外,还具备高效的能力。
违背G4准则(Element-wise操作)是必不可免的。毕竟基于优秀网络上的改进,很多是增加一些Element-wise操作,从而获得准确率的提升。 但ShuffleNetV2告诉了我们,Element-wise操作可以简化(如relu的移位)。
且如果让网络变得精简的话,这可能会让网络获得意想不到的提升,比如WRN就打败了很多花里胡哨。
论文还提到特征重用(Feature reuse), 用上了特征重用的方法后效果会提升(Densenet、DPN、残差金字塔之类等等)。之后需要多了解这方面的论文和方法。
重磅!CVer学术交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测交流群、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!


