来自 Facebook AI 的严志程团队发表一种新的神经架构的快速搜索算法。该算法采用自适应架构概率分布熵的架构采样,能够减少采样样本达 60%,加速搜索快 1.8 倍。此外,该算法还包括一种新的基于分解概率分布的由粗到细的搜索策略,进一步加速搜索快达 1.2 倍。该算法搜索性能优于 BigNAS、EfficientNet 和 FBNetV2 等算法。
就职于 Facebook AI 的严志程博士和他的同事最近在 CVPR 2021 发表了关于加速概率性神经架构搜索的最新工作。该工作提出了一种新的自适应架构分布熵的架构采样方法来显著加速搜索。同时,为了进一步加速在多变量空间中的搜索,他们通过在搜索初期使用分解的概率分布来极大减少架构搜索参数。结合上述两种技巧,严志程团队提出的搜索方法 FP-NAS 比 PARSEC [1] 快 2.1 倍,比 FBNetV2 [2] 快 1.9-3.5 倍,比 EfficientNet [3] 快 132 倍以上。FP-NAS 可以被用于直接搜索更大的模型。搜索得到 FP-NAS-L2 模型复杂度达到 1.0G FLOPS,在只采用简单知识蒸馏的情况下,FP-NAS-L2 能够比采用更复杂的就地蒸馏的 BigNAS-XL [4]模型,提高 0.7% 分类精度。
![]()
论文链接:https://arxiv.org/abs/2011.10949
近年来,神经架构的设计逐渐从手动的人工设计变换到自动的算法搜索 (NAS)。早期 NAS 的方法基于进化和强化学习,搜索速度极慢。最近,可微分神经架构搜索方法(DNAS) 通过共享架构模型参数和计算架构参数梯度来加速搜索。但是由于需要在内存里为每一个模型层同时存放所有可能的架构选项,DNAS 的内存开销随着搜索空间的大小线性增长,使得它不适用在大搜索空间内搜索复杂度高的模型。另一方面,概率性神经架构搜索方法 PARSEC 每次只需要采样一个架构,能极大减小内存开销,但是因为每次参数更新需要采样许多架构,搜索的速度较慢。
为了解决上述问题,严志程团队提出两个新的技巧。首先,PARSEC 方法中的固定架构采样的方法被一种新的自适应架构概率分布熵的采样方法取代。在搜索前期,算法会采样更多的架构来充分探索搜索空间。在搜索后期,随着架构概率分布熵的减小,算法减少采样的数量来加速搜索。其次,搜索通常在多变量空间进行,比如卷积核的大小、模型层的宽度等。为了减少架构参数来加速搜索,在搜索前期,我们可以用分解的概率分布来表示搜索空间进行粗粒度搜索。在搜索后期,我们转换到联合的概率分布进行精细搜索。
这项 FP-NAS 工作的主要创新点和实验结果如下:
提出一种新的自适应架构概率分布熵的采样方法,能够减少采样的样本达 60%,加速搜索快 1.8 倍。
提出一种新的基于分解概率分布的由粗到细的搜索策略,进一步加速搜索快达 1.2 倍。
对小模型搜索,FP-NAS 方法比 FBNetV2 方法快 3.5 倍,并且搜索得到的模型精度更高。
在搜索更大的复杂度达到 0.4G FLOPS 的模型时,FP-NAS 比 EfficientNet 快 132 倍,同时搜到的模型 FP-NAS-L0 在 ImageNet 上比 EfficientNet-B0 精度高 0.7%。直接搜索复杂度达到 1.0G FLOPS 的大模型时,FP-NAS 搜到的模型 FP-NAS-L2 精度比 EfficientNet-B2 高 0.4%。
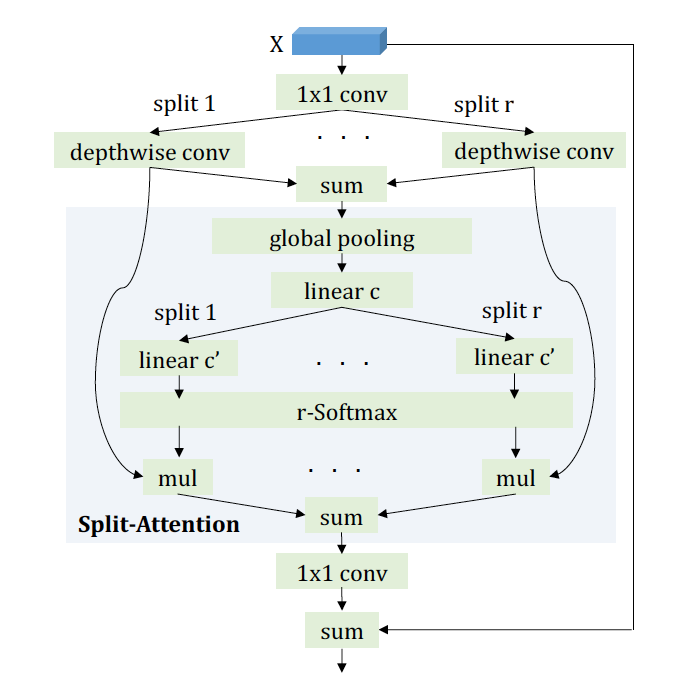
FP-NAS 通过把 Squeeze-Excite 模块替换成 Split-Attention 来扩大搜索空间,同时证明单独搜索各个模型层的 Attention splits 的必要性。
![]()
![]()
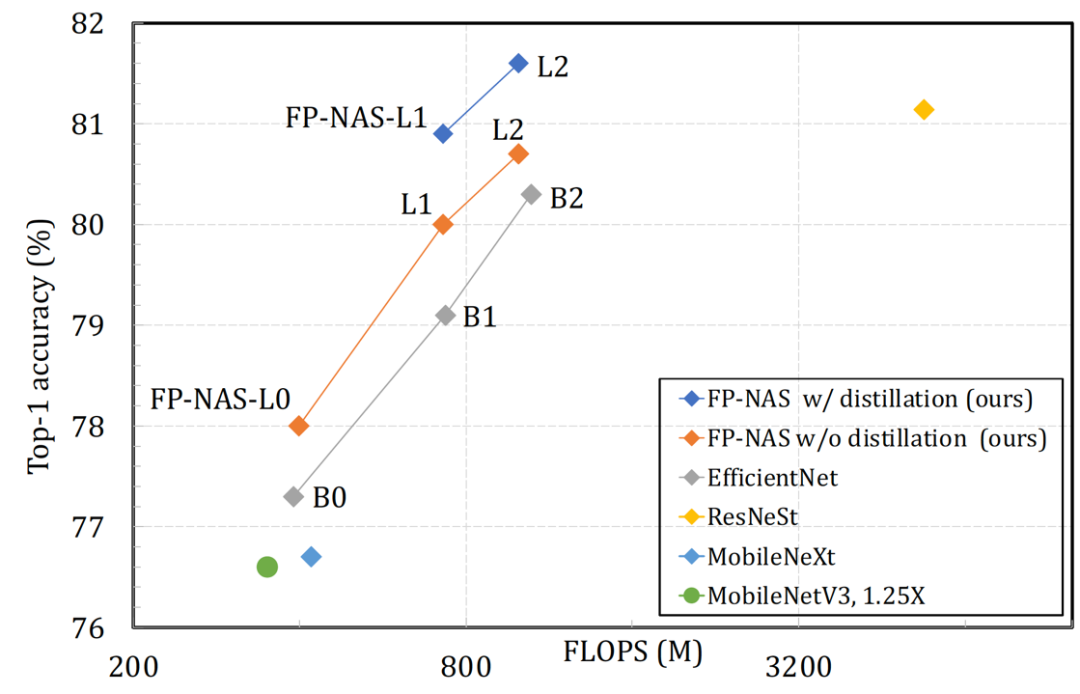
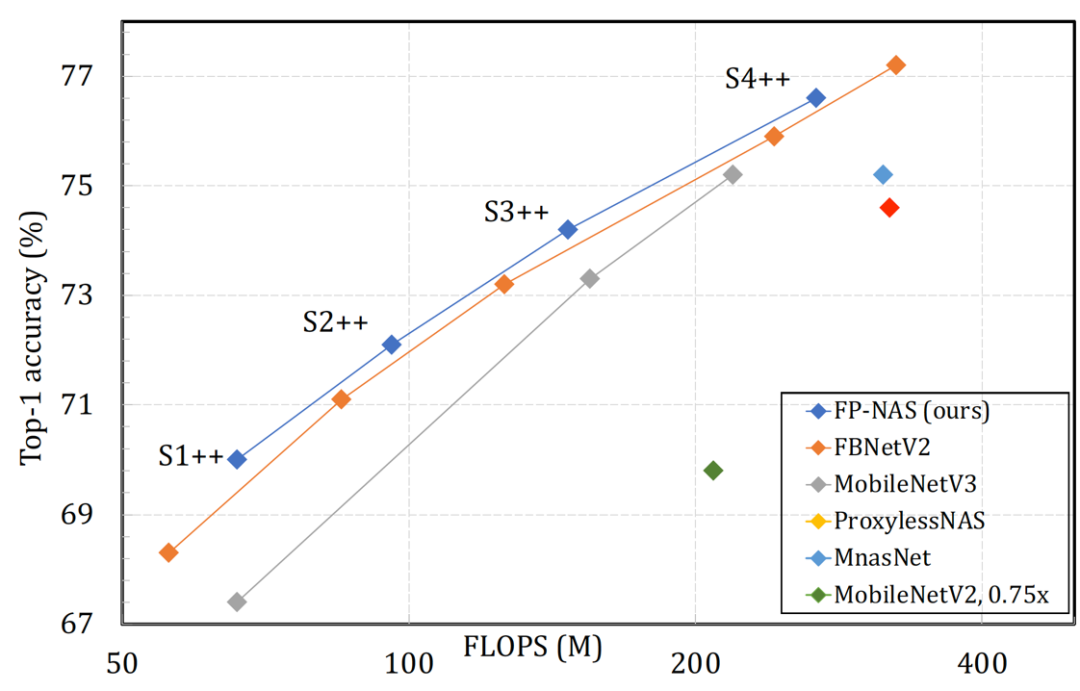
图 1: 在 ImageNet 数据集上通过比较 FP-NAS 和其他 NAS 方法搜索得到的模型结果。
在可微分神经架构搜索方法 DNAS 中,离散的模型层架构选择被表示成连续的所有可能选择的加权总和。
![]()
在概率性神经架构搜索方法 PARSEC 中,一个架构 A 可以被表示成所有 L 个模型层上的架构
![]() 。架构的分布可以用一个概率
。架构的分布可以用一个概率
![]() 来刻画。假定,每个模型层的架构是独立的,每个架构 A 的概率可以表示如下。
来刻画。假定,每个模型层的架构是独立的,每个架构 A 的概率可以表示如下。
![]()
这里,
α表示架构分布参数。对常见的图像分类问题,我们有图像 X 和类标记 y,PARSEC 的优化函数如下。
![]()
PARSEC 搜索方法在每个优化迭代中采样 K 个固定数量的架构样本。样本的数量 K 是一个超参,通常需要手动调节来权衡搜索速度和最终架构的性能矛盾。在新提出的自适应采样中,样本的数量根据架构概率分布的熵进行自适应改变。
![]()
这里, Η表示分布熵, λ是一个预定义的系数。自适应采样在搜索前期因为熵较高而采样更多的架构。但是因为在搜索后期分布熵大大降低,我们只需要采样少量架构就能获得很好的搜索结果。
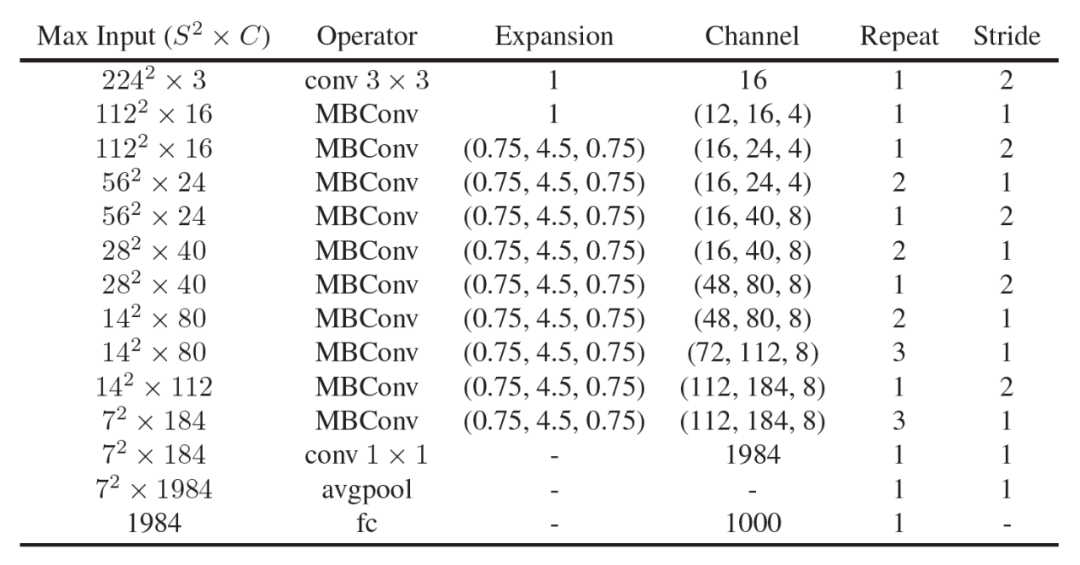
在神经架构搜索中,我们经常对多个变量进行搜索。下面两个表格分别呈现搜索空间的宏架构和微架构。
![]()
![]()
表 2: FBNetV2 和 FP-NAS 搜索空间的微架构。
我们使用的搜索空间有 M=5 个变量 ,包括特征通道数、通道扩张比例、卷积核大小、非线性激活函数和注意力模块里的 splits 数。假定每个变量的基数分别是 3、2、2、6 和 10,那么使用联合概率分布表示搜素空间时需要 prod([3, 2, 2, 6, 10])=720 个架构参数。但是使用分解概率分布时,架构参数可以被减少到 sum([3, 2, 2, 6, 10])=23,相差 31 倍。
![]()
FBNetV2-F space。这是先前 FBNetV2 工作中提出的一个空间,一共包含6×10^25个不同的架构。
FBNetV2-F-Fine space。在这个空间中,每个 MBConv 块允许使用不同的架构。
FBNetV2-F++ space。在这个空间中,原来的 SqueezeExcite 注意力模块被新的 SplitAttention 模块取代。split 的数目选择从原来的 {0, 1} 被扩展到{0, 1, 2, 4}。
FP-NAS space。为了支持搜索更大的神经架构,我们把 FBNetV2-F++ 的搜索宏架构变得更宽更深,同时提高输入图像的分辨率,得到三个更大的 FP-NAS 搜索空间 L0-L2。
![]()
图 2: 含 Split-Attention 注意力模块的 MBConv 模块。
![]()
表 3: 三个包含不同复杂度模型的 FP-NAS 神经架构搜索空间。
我们随机选择 100 个 ImageNet 类的数据(ImageNet-100)用于神经架构搜索。不断迭代地交替更新架构参数α和模型参数ω进行优化。
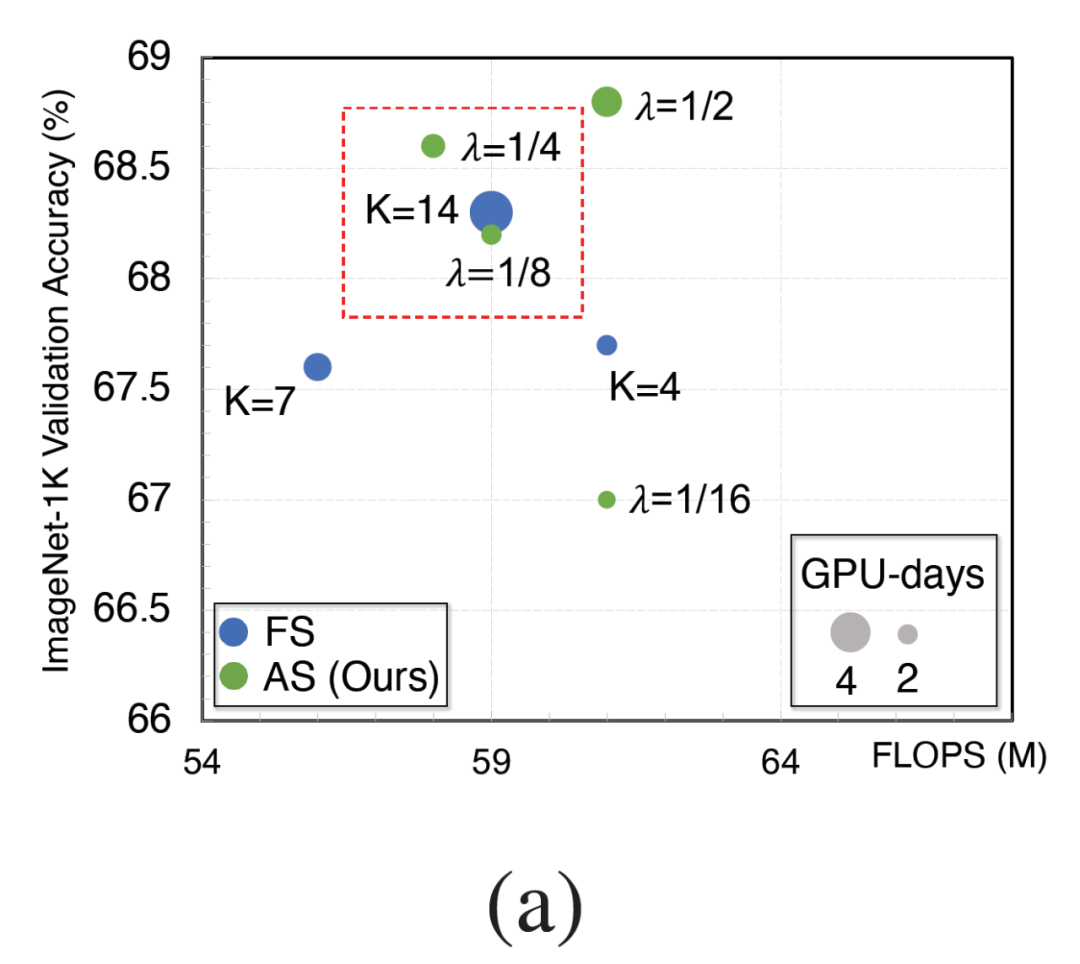
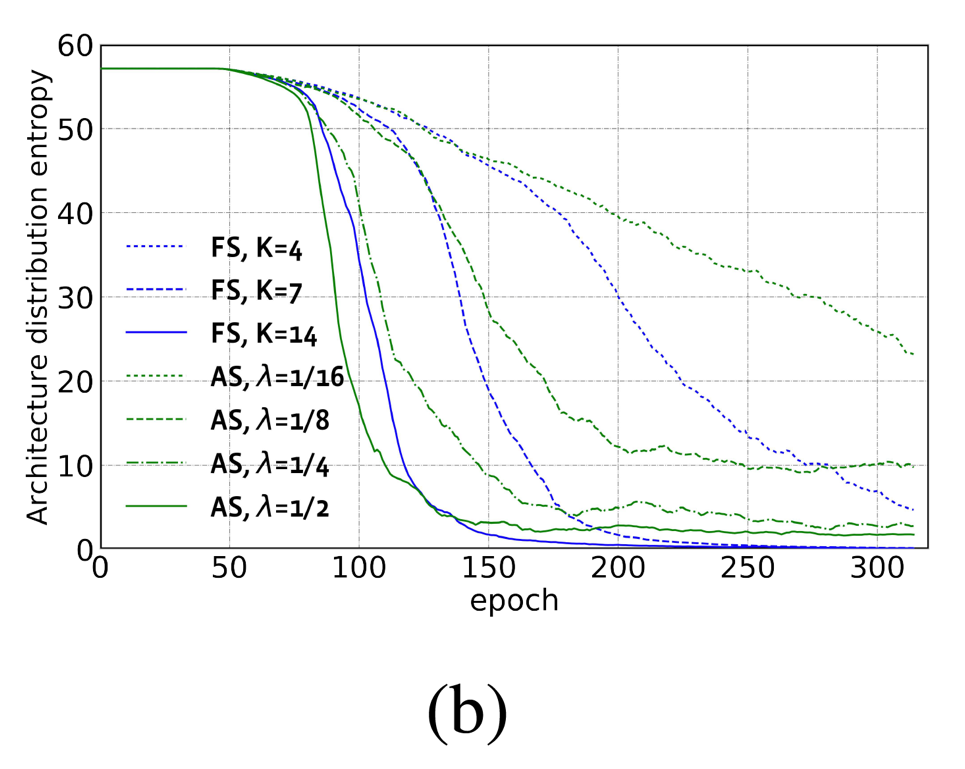
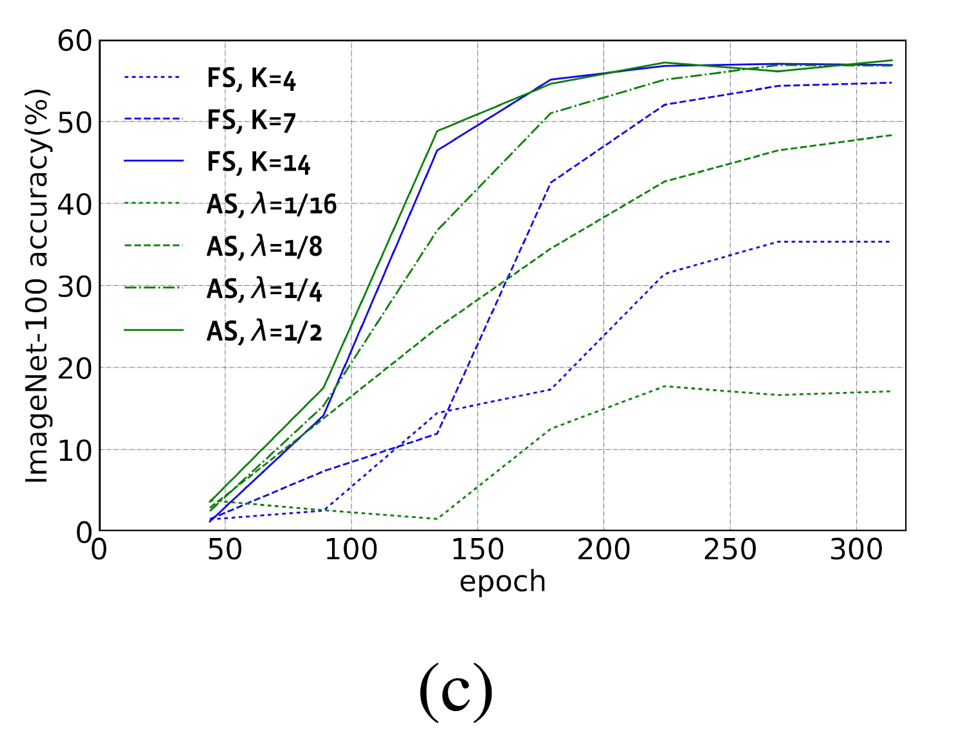
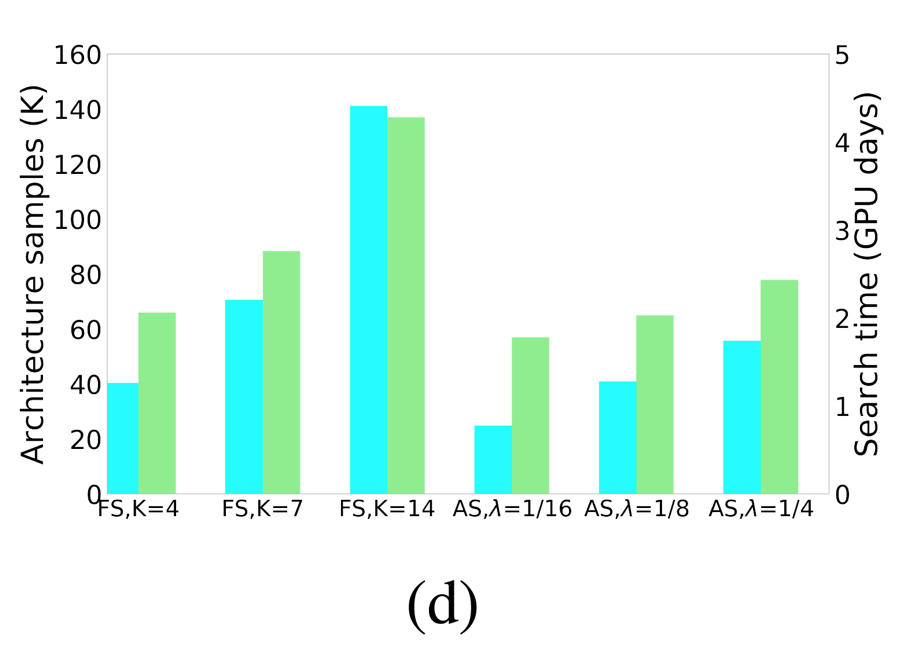
PARSEC 方法在每个优化迭代中固定采样(FS: Fixed Sampling)若干个架构(K=8 或者 16)。在图 3(a)中,我们发现固定样本数目 K 和搜索得到的架构的精度 / 复杂度权衡(ATC: Accuracy-To-Complexity)高度相关。在图 3(b)中,当 K 取值变大时,架构分布的概率熵下降得更快。在图 3(c)中,我们发现在搜索阶段结束的时候,ImageNet-100 上验证集上的精度随着 K 取值变大而变高。在图 3(d)中,我们看到总共的采样样本数量和搜索时间都随着 K 取值变大而线性增长。
对于新提出的自适应采样方法(AS: Adaptive sampling),我们试验了不同的超参数
![]() 。在图 3(a)中,我们发现采用
。在图 3(a)中,我们发现采用
![]() 的自适应采样搜索得到的架构已经能达到用Κ=14的固定采样搜索得到的架构相似的 ATC,但是搜索时间大大缩短。在图 3(b)中,我们发现采用
的自适应采样搜索得到的架构已经能达到用Κ=14的固定采样搜索得到的架构相似的 ATC,但是搜索时间大大缩短。在图 3(b)中,我们发现采用
![]() 的时候,自适应采样方法将架构概率分布的熵降低到一个很低的水平,表明最有可能的架构已经被搜索到。在图 3(c)中,我们发现采用
的时候,自适应采样方法将架构概率分布的熵降低到一个很低的水平,表明最有可能的架构已经被搜索到。在图 3(c)中,我们发现采用
![]() 的时候,自适应采样方法在 ImageNet-100 验证集上的分类精度已经和固定采样方法的分类精度几乎一样高。在图 3(d)中,我们看到与采用 K=14 的固定采样方法相比,采用
的时候,自适应采样方法在 ImageNet-100 验证集上的分类精度已经和固定采样方法的分类精度几乎一样高。在图 3(d)中,我们看到与采用 K=14 的固定采样方法相比,采用
![]() 的自适应采样方法能够减少 60% 的样本总数量,加快搜索达 1.8 倍。
的自适应采样方法能够减少 60% 的样本总数量,加快搜索达 1.8 倍。
![]()
![]()
![]()
![]()
图 3: 固定采样方法 (FS) 和自适应采样方法 (AS) 的比较。
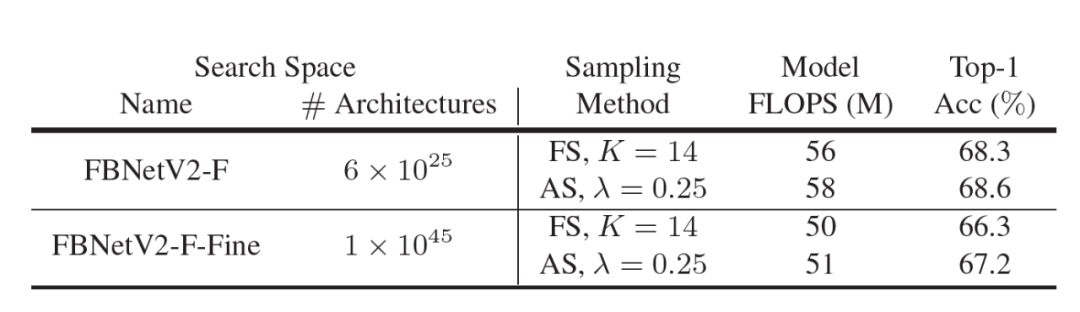
在更大的搜索空间里,我们需要采样更多的架构样本来充分探索空间。对于固定采样来说,使用一个固定的样本量 K 会阻碍搜索得到最优的架构。对于自适应采样来说,使用一个固定λ的仍然能够保证样本数量随着架构分布熵来自动调整,不需要人工进行调参。为了验证这一点,在表 4 中,我们比较了固定采样和自适应采样在 FBNetV2-F 和 FBNetV2-F-Fine 空间里的搜索结果。可以看到,在较小的 FBNetV2-F 空间中,使用两种采样方法得到的最终架构拥有相似的 ATC。但是在较大的 FBNetV2-F-Fine 空间中,在不手工改变超参 K 和 λ 的情况下,自适应方法得到的最终架构的分类精度高出 0.9%。
![]()
表 4: 比较采用不同采样方法在不同搜索空间中得到的最终架构。
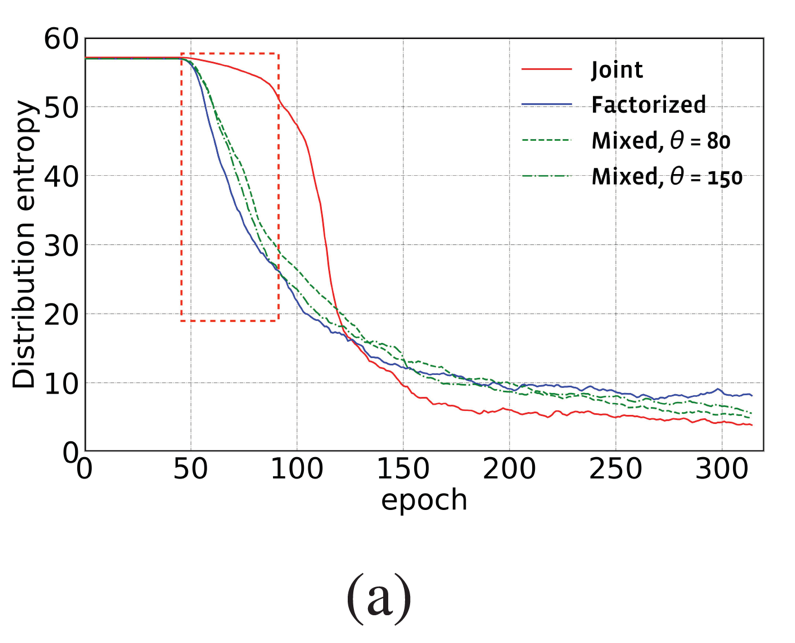
在图 4 中,我们比较联合概率分布 (JD) 和分解概率分布(FD)。在搜索前期迭代 80 次时,架构分布概率熵有很大不同(54.4 Vs 30.6)。但是在搜索后期,分解概率分布降低架构分布概率熵的速度却较慢,并不能精确地区分一小部分高概率的架构。因此,我们提出混合架构分布概率调度(MD)。在搜索开始采用分解概率分布,然后在迭代θ次的时候,将其无缝转换到联合概率分布。在图 4(a)中,我们呈现了采用不同
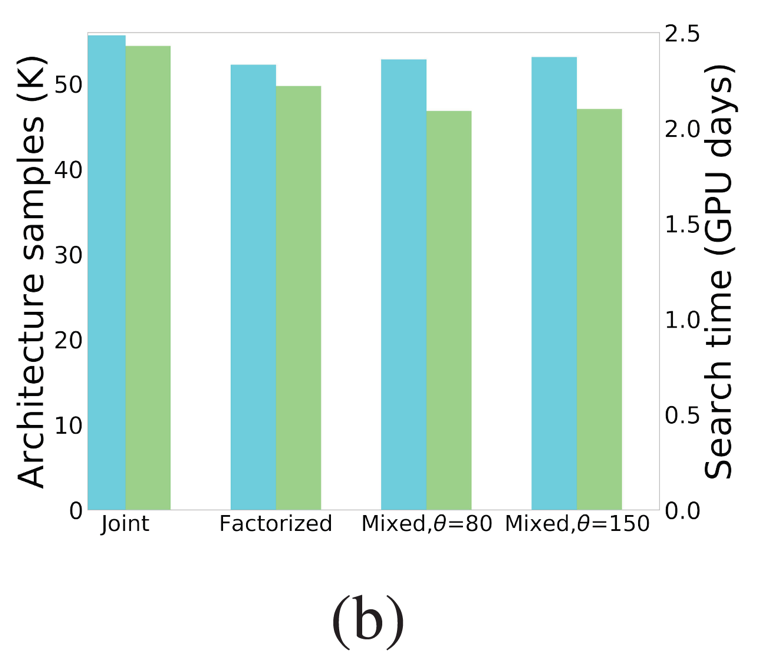
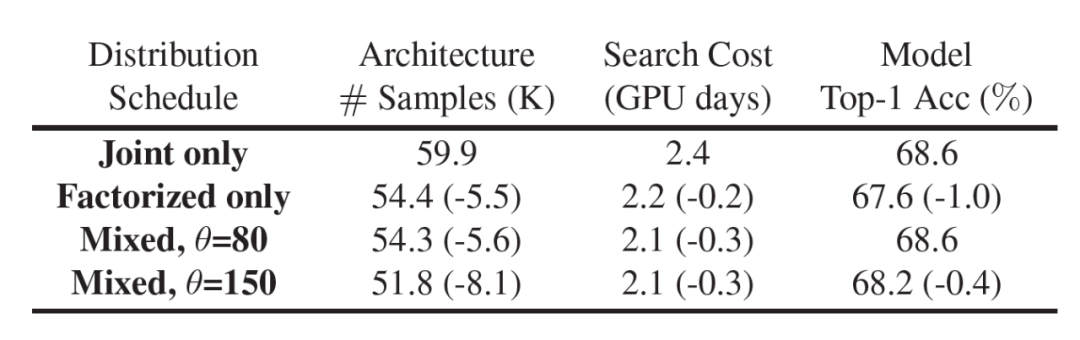
![]() 的混合架构分布概率调度的搜索结果。由于其能够在搜索前期和后期中都能较快降低架构分布概率熵,因此在自适应采样的情况下,我们能够显著减少采样的架构样本数量。在图 4(b)和表 5 中,我们验证采用混合架构分布概率调度由粗到细的搜索策略能够进一步减少架构样本达 9%,加速搜索 1.2 倍,并且不影响最终搜索架构的性能。总结来说,当同时采用自适应样本采样和混合架构分布概率调度,FP-NAS 能够减少采样样本数量达 64%,加快搜索达 2.1 倍。
的混合架构分布概率调度的搜索结果。由于其能够在搜索前期和后期中都能较快降低架构分布概率熵,因此在自适应采样的情况下,我们能够显著减少采样的架构样本数量。在图 4(b)和表 5 中,我们验证采用混合架构分布概率调度由粗到细的搜索策略能够进一步减少架构样本达 9%,加速搜索 1.2 倍,并且不影响最终搜索架构的性能。总结来说,当同时采用自适应样本采样和混合架构分布概率调度,FP-NAS 能够减少采样样本数量达 64%,加快搜索达 2.1 倍。
![]()
![]()
图 4: 比较联合概率分布调度、分解概率分布调度和本文提出的混合概率分布调度。
![]()
表 5: 比较架构概率分布的调度和最终搜索架构的精度。
![]()
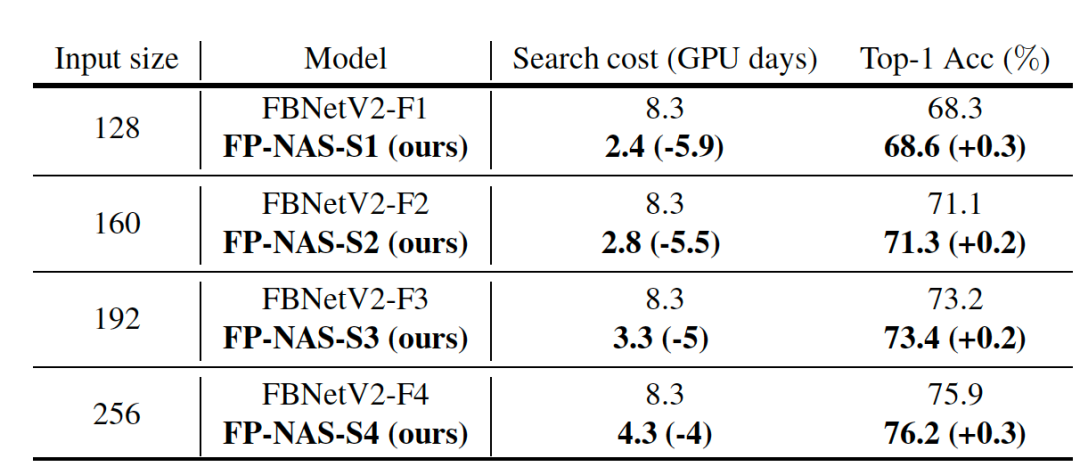
表 6:和 FBNetV2 搜索方法比较搜索小模型的结果。
我们使用同样的 FBNetV2-F 搜索空间,比较 FP-NAS 和 FBNetV2 两种不同的搜索方法。在表 6 中,我们发现 FP-NAS 可以加快搜索达 1.9 到 3.6 倍,并且最终得到的架构能达到更高的分类精度。
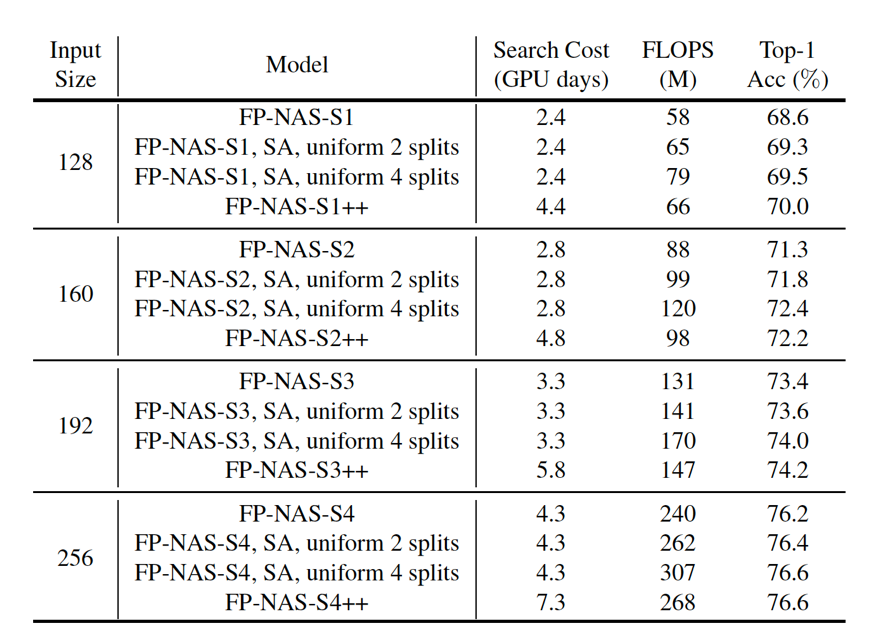
表 7 中我们比较了在 FBNetV2-F 和 FBNetV2-F++ 空间中采用 FP-NAS 搜索得到的架构。我们发现在后者空间搜得的 FP-NAS-S++ 模型可以达到更好的精度 / 复杂度权衡。我们还把在前者空间搜得的 FP-NAS-S 模型进行简单修改,把 splits 数目统一地从 1 改成 2 或者 4。我们发现通过这样简单统一的修改 splits 数目而得到的模型会有较差的精度 / 复杂度权衡。
![]()
表 7: 比较在 FBNetV2-F 和 FBNetV2-F++ 空间中搜索得到的架构。
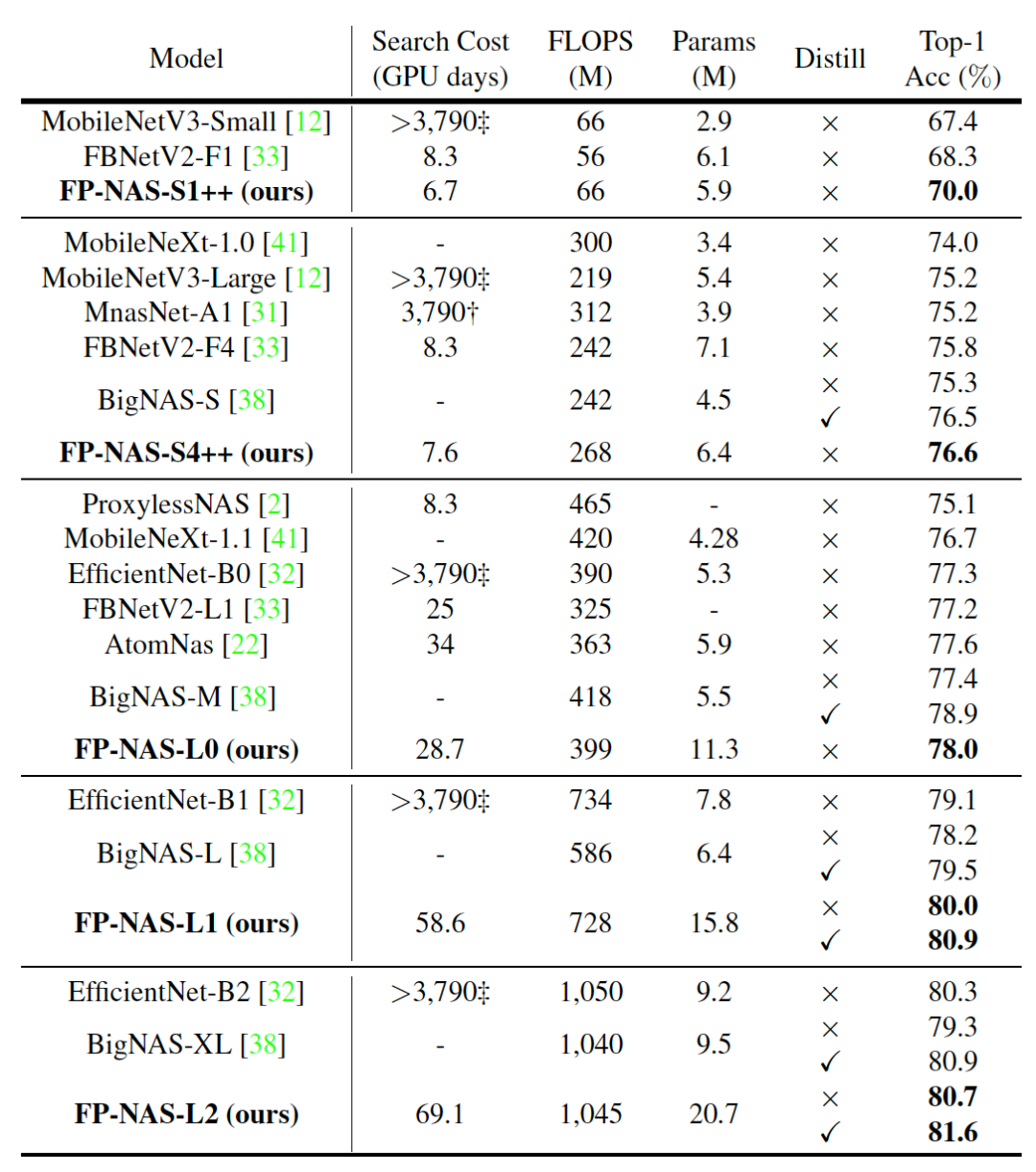
我们在 FP-NAS L 空间里搜索复杂度为{0.4G, 0.7G, 1.0G} FLOPS 的大模型。结果见表 8 和图 1。跟 EfficientNet 相比,FP-NAS-L0 模型和 EfficientNet-B0 模型的复杂度都是 0.4G FLOPS 左右,但是 FP-NAS 的搜索速度快了 132 倍,并且最终的模型分类精度提高了 0.7%。EfficientNet B1 和 B2 模型是通过扩大 B0 模型得到的。FP-NAS L1 和 L2 模型是直接搜索得到的。在搜索极大加速的情况,他们的分类精度分别提高了 0.9% 和 0.4%。
![]()
在表 8 里,我们还将 FP-NAS 跟其他主要搜索方法进行比较,并且确认 FP-NAS 搜索的高效率和最终模型的高性能。跟 BigNAS 相比,采用简单知识蒸馏的 FP-NAS-L2 模型能够比采用更复杂的就地蒸馏的 BigNAS-XL 模型,提高了 0.7% 分类精度。
自动化神经架构搜索已经成为一种主流的搭建深度模型的方法。尽管在搜索小模型方面, 已有的搜索方法已经取得显著进展,如何扩展他们用于直接快速地搜索更大的模型仍然是一个极具挑战性的课题。本文 FP-NAS 的工作是基于概率性神经架构搜索的框架,在其低内存消耗优势基础上,显著加速其搜索过程,使得 NAS 的科研工作朝着更好的可复制性和可扩展性方向迈进一步。
严志程博士,脸书(Facebook)人工智能应用研究院主任科学家及技术经理。研究方向为大规模图像视频理解、物体和环境感知、及其在增强现实中的应用。FP-NAS、 HACS、HD-CNN 等科研项目的负责人和主要作者。2016 年于伊利诺伊香槟厄巴纳分校获得计算机科学专业的博士学位。从 2016 年至今,在脸书从事计算机视觉相关的科研项目和面向大规模应用的工程项目。曾主导开发脸书第一个商业产品的视觉识别服务,第一个实时处理 Facebook 和 Instagram 所有用户视频的大规模视频语义理解服务。
![]()
[1] Probabilistic neural architecture search. arXiv preprint arXiv:1902.05116, 2019
[2] Fbnetv2: Differentiable neural architecture search for spatial and channel dimensions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12965–12974, 2020
[3] Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 2019.
[4] BigNAS: Scalingup neural architecture search with big single-stage models.arXiv preprint arXiv:2003.11142, 2020
建新·见智 —— 2021亚马逊云科技 AI 在线大会
4月22日 14:00 - 18:00
大会包括主题演讲和六大分会场。内容涵盖亚马逊机器学习实践揭秘、人工智能赋能企业数字化转型、大规模机器学习实现之道、AI 服务助力互联网快速创新、开源开放与前沿趋势、合作共赢的智能生态等诸多话题。
亚马逊云科技技术专家以及各个行业合作伙伴将现身说法,讲解 AI/ML 在实现组织高效运行过程中的巨大作用。每个热爱技术创新的 AI/ML 的爱好者及实践者都不容错过。
识别二维码或点击阅读原文,免费报名看直播。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

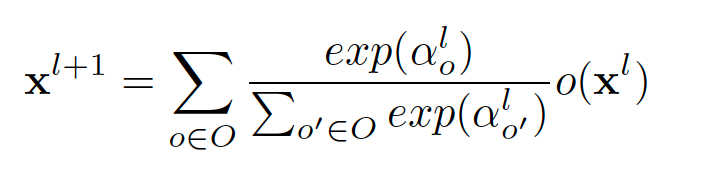
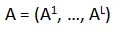 。架构的分布可以用一个概率
。架构的分布可以用一个概率
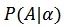 来刻画。假定,每个模型层的架构是独立的,每个架构 A 的概率可以表示如下。
来刻画。假定,每个模型层的架构是独立的,每个架构 A 的概率可以表示如下。
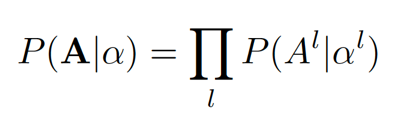
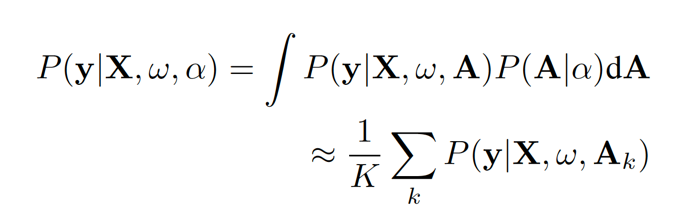
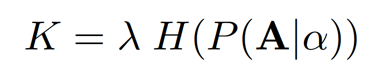

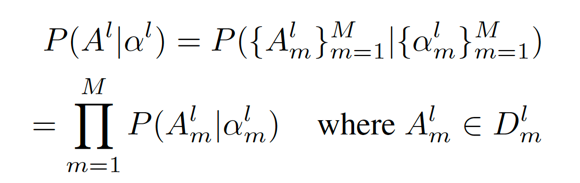

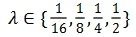 。在图 3(a)中,我们发现采用
。在图 3(a)中,我们发现采用
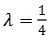 的自适应采样搜索得到的架构已经能达到用Κ=14的固定采样搜索得到的架构相似的 ATC,但是搜索时间大大缩短。在图 3(b)中,我们发现采用
的自适应采样搜索得到的架构已经能达到用Κ=14的固定采样搜索得到的架构相似的 ATC,但是搜索时间大大缩短。在图 3(b)中,我们发现采用
 的时候,自适应采样方法将架构概率分布的熵降低到一个很低的水平,表明最有可能的架构已经被搜索到。在图 3(c)中,我们发现采用
的时候,自适应采样方法将架构概率分布的熵降低到一个很低的水平,表明最有可能的架构已经被搜索到。在图 3(c)中,我们发现采用
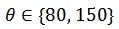 的混合架构分布概率调度的搜索结果。由于其能够在搜索前期和后期中都能较快降低架构分布概率熵,因此在自适应采样的情况下,我们能够显著减少采样的架构样本数量。在图 4(b)和表 5 中,我们验证采用混合架构分布概率调度由粗到细的搜索策略能够进一步减少架构样本达 9%,加速搜索 1.2 倍,并且不影响最终搜索架构的性能。总结来说,当同时采用自适应样本采样和混合架构分布概率调度,FP-NAS 能够减少采样样本数量达 64%,加快搜索达 2.1 倍。
的混合架构分布概率调度的搜索结果。由于其能够在搜索前期和后期中都能较快降低架构分布概率熵,因此在自适应采样的情况下,我们能够显著减少采样的架构样本数量。在图 4(b)和表 5 中,我们验证采用混合架构分布概率调度由粗到细的搜索策略能够进一步减少架构样本达 9%,加速搜索 1.2 倍,并且不影响最终搜索架构的性能。总结来说,当同时采用自适应样本采样和混合架构分布概率调度,FP-NAS 能够减少采样样本数量达 64%,加快搜索达 2.1 倍。