产品经理,你要了解一些音视频技术
关注并标星「人人都是产品经理」
每天早07 : 45 按时送达

在当今的移动互联网时代,直播类产品我们再熟悉不过了,比如看游戏直播、给美女主播打赏、听直播课程等。此外,伴随着抖音、快手等短视频类应用的爆发,视频类产品更是时刻充斥着我们的生活。
那么,直播类或者视频的产品背后涉及到的音视频技术知识都有哪些呢?
本文将从直播类产品的基础架构出发,阐述一些基础的音视频技术知识;推荐相关领域的同学学习:
全文共 6762 字 3 图,阅读需要 14 分钟
音视频领域博大精深,本文仅从一个PM的角度出发,总结一些最基本的内容。
一、直播的基础架构
一个直播功能通用的基础架构涉及三个部分,即音视频采集端、云服务端和音视频播放端。
如下图,是一个APP直播功能的架构:
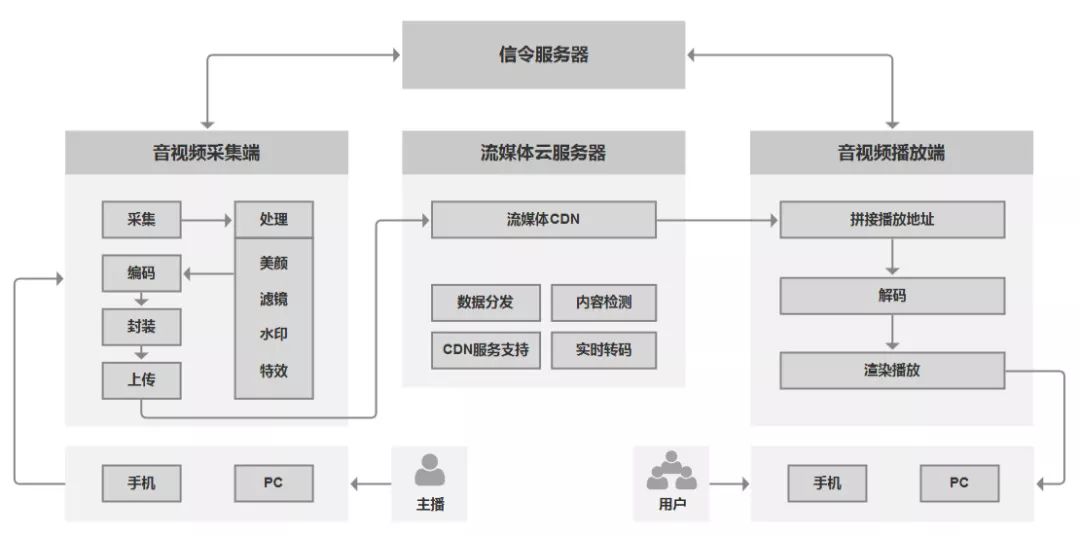
从上图中我们可以看到,每一个部分都有各自要处理的一些工作。
总体来说,视频直播类功能的整体流程包括以下内容:
音视频采集
音视频处理
音视频编码和封装
推流
流媒体服务器处理
拉流
音视频解码
音视频播放
在具体了解每个流程之前,我们先从音视频的基本知识入手。
二、音视频技术基础
1. 音频
声音:
我们平时在手机或电脑里听到的音频,是已经数字化了的音频模拟信号。最初,这些音频都是始于物理的声音。
中学物理都学过,声音是波,是通过物体的振动产生的。
声波具有三要素:
音调:也叫音频,频率越高,波长就会越短,而低频声响的波长则较长。所以这样的声音更容易绕过障碍物。能量衰减就越小,声音就会传播的越远;
音量:就是振动的幅度。用不同的力度敲打桌面,声音的大小势必发生变换。在生活中,我们用分贝描述声音的响度;
音色:在同样的频率和响度下,不同的物体发出的声音不一样。波形的形状决定了声音的音色。因为不同的介质所产生的波形不同,就会产生不一样的音色。
模拟信号的数字化过程:
模拟信号的数字化过程,就是将模拟信号转换为数字信号的过程,包括采样、量化和编码。
我们可以通过下图理解这一过程:

采样:可以理解为在时间轴上对信号进行数字化。通常用采样率来保证一定频率范围内的声音可以被数字化成功,比如:采样频率一般是44.1KHZ,指的就是1秒会采样44100次。
量化:指的是在幅度轴上对信号进行数字化,就是声音波形的数据是多少位的二进制数据,单位是bit。比如:常用16bit的二进制信号来存放一个采样,这又叫做量化级。量化级是数字声音质量的重要指标,通常将声音描述为24bit(量化级)、48KHZ(采样率)。
编码:按照一定的格式记录采样和量化后的数据。音频编码的格式有很多种,通常所说的音频裸数据指的是脉冲编码调制(PCM)数据。PCM音频流的码率可以用来描述PCM数据,它的计算公式是:采样频率*采样大小(量化级)*声道数(单声道、双声道和多声道)。
通过上述的流程,就实现了音频信号的数字化过程。转为数字信号之后,就可以对这些数据进行存储、播放、复制获取等其他操作了。
音频编码:
上面我们说到了,编码就是按照一定的格式记录采样和量化后的数据,那么到底为什么需要编码呢?
采集和量化后的数据是非常大的,从存储或者网络实时传播的角度来说,这个数据量都太大了。对于存储和传输都是非常具有挑战的,所以我们需要通过编码来进行压缩。
压缩编码的指标是压缩比,压缩比通常是小于1的。
压缩编码算法分为2种:有损压缩和无损压缩。
无损压缩:解压后的数据可以完全复原。在常用的压缩格式。用的较多的都是有损压缩。
有损压缩:解压后的数据不能完全复原,会丢失一部分信息。压缩比越小,丢失的信息就会越多,信号还原的失真就会越大。
压缩编码的实质就是压缩冗余的信号,冗余信号就是指不能被人耳感知的信号,包括:人耳听觉范围之外的音频信号以及被掩盖掉的音频信号。信号的掩蔽可以分为频域掩蔽和时域掩蔽,关于信号的掩蔽大家可以自行百度一下,这里就不做过多阐述了。
那么,音频压缩编码的常用格式都有哪些呢?
主要包括:WMA编码;MP3编码;AAC编码,这个是现在比较热门的有损压缩编码技术,也是目前在直播或小视频中常用的编码格式;OGG编码等。
2. 视频
数字视频:
我们平时在手机或PC上看到的视频,是由内容元素、编码格式和封装容器构成的。

内容元素:包括图像(Image)、音频(Audio)和元信息(Metadata)。
编码格式:包括视频常用编码格式H264,和音频常用编码格式AAC。
封装容器:这就是常见的文件格式,如MP4、MOV、FLV、RMVB、AVI等等。
图像:
图像是人对视觉感知的物质重现。三维图像的对象包括:深度、纹理和亮度信息,二维图像包括纹理和亮度信息,我们可以简单的把纹理就理解为图像。
说了图像的概念,现在来说下视频:视频是由多幅图像构成的,是一组连续的图像。一个基本的数字视频,基本是通过“采集——处理——显示”形成的。
编码格式:
上面我们说到了音频的编码,视频同样是存在编码的过程的。视频编解码的过程是指对数字视频进行压缩或解压缩的过程。
在进行视频的编解码时,需要考虑以下因素的平衡:视频的质量、用来表示视频所需要的数据量(通常称之为码率)、编码算法和解码算法的复杂度、针对数据丢失和错误的鲁棒性、编辑的方便性、随机访问、编码算法设计的完美性、端到端的延时以及其它一些因素。
常用的视频编解码方式有H.26X系列和MPEG系列,而目前最常用的视频编码格式是H.264,它的优点是低码率、图像质量高、容错能力强、网络适应性更强,并且已被广泛应用于实时视频应用中。
再介绍一些关于H.264的知识:
封装格式:
视频的封装格式可以看成是一个装载着视频、音频、视频编解码方式等信息的容器。一种视频封装格式可以支持多种的视频编解码方式,比如:QuickTime(.MOV)支持几乎所有的编解码方式,MPEG(.MP4)也支持大部分的编解码方式。
在PC上,我们经常会使用.MOV的视频文件。通过以上的介绍,我们就知道了,这个视频的文件格式是.MOV,封装格式是QuickTime File Format,但是我们无法知道它的视频编解码方式。
如果我们想要专业的去描述一个视频,可以描述成:
H.264/MOV的视频文件
这就是说:它的封装方式是QuickTime File Format,文件格式是.MOV,编码方式是H.264。
H.264:
H.264是一种高性能的视频编解码技术,是由“国际电联”和“国际标准化组织ISO”联合组建的联合视频组共同制定的新的数字视频编码标准。
我们在上面已经说到了H.264编码技术的优势,我们接下来看一下H.264所涉及的关键技术:
我们首先要知道,无论是视频或音频编码,其目的都是压缩。
视频编码的目的,是抽取出冗余信息,这些冗余信息包括:空间冗余、时间冗余、编码冗余、视觉冗余和知识冗余。
基于此,H.264的压缩技术涉及:
a)帧内预测压缩,解决的就是空间数据冗余问题。空间冗余数据就是图里数据在宽高空间内包含了很多颜色和光亮,人的肉眼很难察觉的数据。对于这些数据,我们是可以直接压缩掉的。
帧内压缩对应的是I帧——即关键帧。那么什么是I帧呢?网上教程中有一个经典的例子,如果摄像头对着你拍摄,1秒之内实际你发生的变化是非常少的。
摄像机一般1秒钟会抓取几十帧的数据,比如像动画,就是25帧/s,一般视频文件都是在30帧/s左右。那些对于一组帧来说变化很小的,为了便于压缩数据,就将第一帧完整的保存下来。
如果没有这个关键帧后面解码数据是完成不了的,所以I帧是特别关键的。
b)帧间预测压缩,解决的是时间数据冗余问题。在上面的例子中,摄像头在一段时间内所捕捉的数据没有较大的变化,我们针对这一时间内的相同的数据压缩掉,这就是时间数据压缩。
帧间压缩对应的是P帧和B帧。P帧是向前参考帧,压缩时只参考前一个帧。而B帧是双向参考帧,压缩时即参考前一帧也参考后一帧。
c)整数离散余弦变换(DCT),将空间上的相关性变为频域上无关的数据然后进行量化。
d)CABAC压缩:无损压缩。
H.264除了上述的关键技术,还有几个重要的概念需要了解:
GOF:一组帧,就是一个I帧到下一个I帧,这一组的数据。包括B帧/P帧,我们称为GOF。
SPS和PPS:SPS和PPS是GOF的参数,SPS是存放帧数,参考帧数目,解码图像尺寸,帧场编码模式选择标识等。而PPS是存放熵编码模式选择标识,片组数目,初始量化参数和去方块滤波系数调整标识等。
在进行视频解码的时候,接收到一组帧GOF之前,我们首先收到的是SPS/PPS数据,如果没有这组参数的话,是无法进行解码的。
因此,如果在解码时发生错误,首先要检查是否有SPS/PPS。如果没有,就要检查是因为对端没有发送过来还是因为对端在发送过程中丢失了。
更加详细的H.264编码原理这里就不做介绍了,大家感兴趣的可以上网查阅一下资料,比如:宏块分组划分、宏块查找、帧内预测、DCT压缩以及H.264的码流结构等知识。
三、直播流程详述
通过上面的介绍,我们已经了解音视频一些基本的知识。接下来,我们一起再描述一遍直播类应用的整体流程。
1. 音视频采集
在音视频采集阶段会包括:音频采集和图像采集。
在音频采集时,除了上面我们说到的采样率、量化级数和声道数参数外,还需要音频帧。
音频跟视频很不一样,视频每一帧就是一张图像,而从声音的正玄波可以看出:音频数据是流式的,没有明确的一帧帧的概念。在实际的应用中,为了音频算法处理/传输的方便,一般约定俗成取 2.5ms~60ms 为单位的数据量为一帧音频。
这个时间被称之为“采样时间”,其长度没有特别的标准,它是根据编解码器和具体应用的需求来决定的。
如果某音频信号是采样率为 8kHz、双通道、量化级数是16bit,采样时间是20ms,则一帧音频数据的大小为:
8000 * 2 * 16bit * 0.02s = 5120 bit = 640 byte
在图像采集中,采集的图片结果会组合成一组连续播放的动画,即构成视频中可肉眼观看的内容。
图像的采集过程主要由摄像头等设备拍摄成 YUV 编码的原始数据,然后经过编码压缩成 H.264 等格式的数据分发出去。在图像采集阶段,涉及的主要技术参数包括:图像传输格式、图像格式、传输通道、分辨率以及采样率。
在音视频的采集阶段,常用的采集源包括摄像头,比如手机的前后置摄像头;游戏直播中使用的屏幕录制;和电视节目中视频文件的直接推流。
2. 音视频处理
音视频处理会分为:视频处理和音频处理。
视频处理包括:美颜、滤镜、面部识别、水印、剪辑拼接等。音频处理包括:混音、降噪、声音特效等。
下面我们简要描述一下美颜和视频水印的基本原理:
美颜的主要原理是通过【磨皮】+【美白】来达到整体美颜效果的;磨皮的技术术语是去噪,也就是对图像中的噪点进行去除或者模糊化处理,常见的去噪算法有均值模糊、高斯模糊和中值滤波等。这个环节中也涉及到人脸和皮肤检测技术。
视频水印包括播放器水印和视频内嵌水印两种方式。对于播放器水印来说,如果没有有效的防盗措施,对于没有播放鉴权的推流,客户端拿到直播流之后可以在任何一个不带水印的播放器里面播放,因此也就失去了视频保护的能力。
所以,一般来说会选择视频内嵌水印的方式打水印,这样,水印就会内嵌到视频之内,在视频播放的过程中持续显示。
再多聊一些,视频内嵌水印也会应用在软件中,软件中播出企业内部版权保护的动画段视频时,会应用到内嵌水印的技术。
3. 音视频编码和封装
音视频的编码以及视频的封装在上述基础知识部分已经介绍过了,这里不再赘述。
在这里说一下编码器的知识。上文中我们了解了H.264的编码技术,编码流程是要基于编码器进行的。
编码器的主要流程是:
帧内预测(去除空间冗余)/帧间预测(去除时间冗余)——变换(去除空间冗余)——量化(去除视觉冗余)——熵编码(去除编码冗余)
通过该流程,即可完成音视频的编码步骤。
4. 推流
推流就是将处理过的音频和视频数据通过流媒体协议发送到流媒体服务器。
推流协议:
推流所遵循的协议有RTMP、WebRTC和基于UDP的私有协议。
RTMP协议是基于TCP协议的,RTMP 是目前主流的流媒体传输协议,广泛用于直播领域,市面上绝大多数的直播产品都采用了这个协议。但是,由于基于TCP协议,传输成本高,在弱网环境下丢包率高,不支持浏览器推送。
WebRTC是一个支持网页浏览器进行实时语音对话或视频对话的 API,主要应用于视频会议。它的主流浏览器支持度高,并且底层基于SRTP和UDP,弱网情况优化空间大。
基于UDP的私有协议。有些直播应用会使用 UDP 做为底层协议开发自己的私有协议,因为 UDP在弱网环境下的优势通过一些定制化的调优可以达到比较好的弱网优化效果,但是开发成过高。
CDN:
推出去的流媒体要给各个地理位置的观众看,那么这里就需要CDN网络了。CDN就是为了解决用户访问网络资源慢而产生的技术。
CDN包括边缘节点、二级节点和源站。内容提供方可以将内容放到源站上,用户从边缘节点获取数据,而CDN的二级节点则用于缓存,减轻源站压力。
在直播领域中,CDN要支持的服务如下:
流媒体协议的支持。比如RTMP等;
首屏秒开。从用户点击到播放控制在秒级以内;
1~3 延迟控制。从推流端到播放端,延迟控制在 1~3 秒之间;
全球全网智能路由。可以利用整个CDN网络内的所有节点为某一单一用户服务,不受地域限制。
5. 流媒体服务器处理
流媒体服务器要做的事情包括:数据分发(CDN)、支持上述CDN的一些服务、实时转码以及内容的检测(鉴黄)等。
6. 拉流
拉流就是客户端从流媒体服务器上拉取获得上述步骤中的音视频数据。
同理,这个过程也是要基于上述的协议和CDN。
7. 音视频解码
在上述H.264编码的介绍中,说到了SPS/PPS是解码必备的数据。此步骤就是需要对拉流下来已编码的音视频数据进行解码。
解码过程就是编码的逆过程,这个过程包括:熵解码、变换解码、预测解码。
H.264规范规定了解码器的结构,解码的过程大体如下:以宏块为单位,依次进行熵解码、反量化、反变换,得到残差数据。再结合宏块里面的预测信息,找到已解码的被参考块,进而结合已解码被参考块和本块残差数据,得到本块的实际数据。宏块解码后,组合出片,片再进而组合出图像。
这里要说明的是:如果H264码流中I帧错误或丢失,就会导致错误传递,单独的P帧或B帧是完成不了解码工作的。I帧所保留的是一张完整的视频帧,是解码的关键所在。
8. 音视频播放
在完成了音视频数据的解码后,就可以通过硬件设备(手机或PC)上的播放器对音视频文件进行渲染播放了。
那么,上述架构图中的信令服务器是干什么的呢?
——信令服务器是用来处理主播端和用户端的一些信令指令的。
在网络中传输着各种信号,其中一部分是我们需要的(例如:打电话的语音,上网的数据包等等),而另外一部分是我们不需要的(只能说不是直接需要)它用来专门控制电路的,这一类型的信号我们就称之为信令(摘自百度百科)。也就是说,信令是指通信系统中的控制指令。
我们基于此,再来描述一下这整个的流程:
1. 主播共享端发起一个信令,比如:创建房间(或聊天、发送礼物等),到达信令服务器;信令服务器处理并且创建一个房间,同时返回给主播共享端一个流媒体云的地址。
2. 接下来,主播共享端采集数据(音视频的采集、处理以及编码封装流程)形成RTMP流推送到CDN网络(推流)。
3. 观众要进行观看时,客户端会发送信令到信令服务器,信令服务器将该观众加入到主播的房间中,同时也会返回一个流媒体云的地址(该地址就是之前主播端的流媒体云地址)。
4. 客户端拿到此流媒体云地址后,就会到流媒体云服务器拉取到该媒体流(拉流和解码),从而看到要观看的直播节目(播放器播放)。
好了,以上就是直播类应用的一个最基本的架构和流程了。
四、总结
本文通过直播类应用的架构,介绍了一些音视频技术方面的知识,并且详述了直播类功能的整体流程。
音视频技术是一个高深的领域,本文只是做了一些基础知识的总结,如果大家想要深入了解更多的音视频技术,我推荐大家可以学习一下雷神(雷霄骅)的博客。
———————— END ————————

每个「在看」,都是一次鼓励 ▼




