PyTorch必备神器 | 唯快不破:基于Apex的混合精度加速

作者丨Nicolas
单位丨追一科技AI Lab研究员
研究方向丨信息抽取、机器阅读理解
PyTorch实现
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
理论部分
1. 什么是FP16?
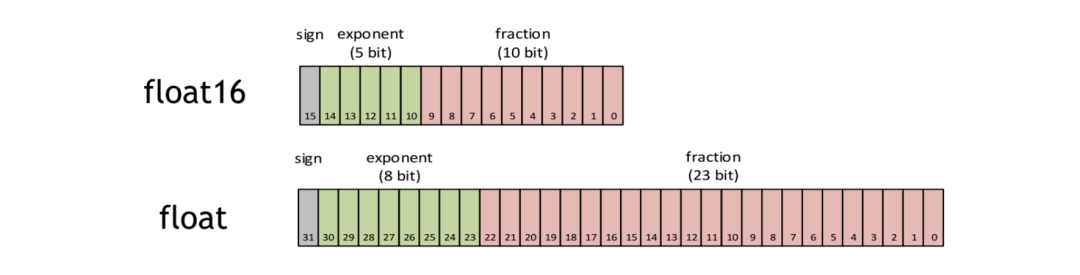
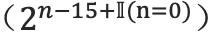 ,
fraction
位表示的是分数
,
fraction
位表示的是分数
▲ FP16的表示范例
2. 为什么需要FP16?
减少显存占用 现在模型越来越大,当你使用 Bert 这一类的预训练模型时,往往模型及模型计算就占去显存的大半,当想要使用更大的 Batch Size 的时候会显得捉襟见肘。由于 FP16 的内存占用只有 FP32 的一半,自然地就可以帮助训练过程节省一半的显存空间。
加快训练和推断的计算 与普通的空间时间 Trade-off 的加速方法不同,FP16 除了能节约内存,还能同时节省模型的训练时间。在大部分的测试中,基于 FP16 的加速方法能够给模型训练带来多一倍的加速体验(爽感类似于两倍速看肥皂剧)。
张量核心的普及 硬件的发展同样也推动着模型计算的加速,随着 NVIDIA 张量核心(Tensor Core)的普及,16bit 计算也一步步走向成熟,低精度计算也是未来深度学习的一个重要趋势,再不学习就 out 啦。
3. FP16带来的问题:量化误差
溢出错误(Grad Overflow / Underflow)由于 FP16 的动态范围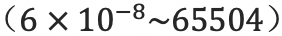
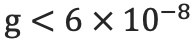
在深度学习中,由于激活函数的的梯度往往要比权重梯度小,更易出现下溢出的情况。
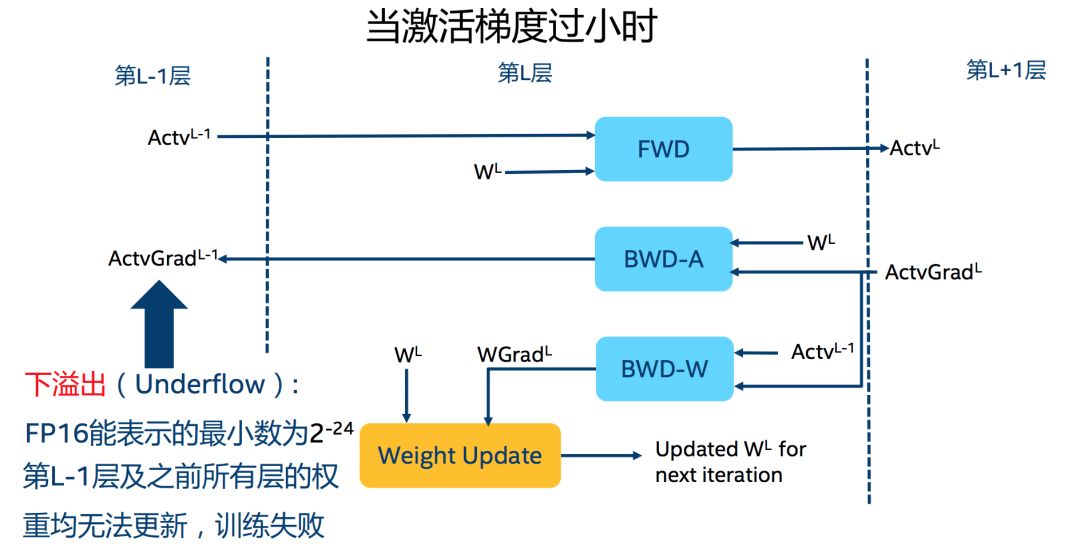
▲ 下溢出问题
舍入误差(Rounding Error)舍入误差指的是当梯度过小,小于当前区间内的最小间隔时,该次梯度更新可能会失败,用一张图清晰地表示:

4. 解决问题的办法:混合精度训练+动态损失放大
混合精度训练(Mixed Precision)混合精度训练的精髓在于“在内存中用 FP16 做储存和乘法从而加速计算,用 FP32 做累加避免舍入误差”。混合精度训练的策略有效地缓解了舍入误差的问题。
损失放大(Loss Scaling)即使用了混合精度训练,还是会存在无法收敛的情况,原因是激活梯度的值太小,造成了下溢出(Underflow)。损失放大的思路是:
反向传播前,将损失变化(dLoss)手动增大
倍,因此反向传播时得到的中间变量(激活函数梯度)则不会溢出;
反向传播后,将权重梯度缩小
倍,恢复正常值。
Apex的新API:Automatic Mixed Precision (AMP)
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
O0 :纯 FP32 训练,可以作为 accuracy 的 baseline;
O1 :混合精度训练(推荐使用),根据黑白名单自动决定使用 FP16(GEMM, 卷积)还是 FP32(Softmax)进行计算;
O2 :“几乎 FP16”混合精度训练,不存在黑白名单,除了 Batch Norm,几乎都是用 FP16 计算;
O3 :纯 FP16 训练,很不稳定,但是可以作为 speed 的 baseline。

干货:踩过的那些坑
这一部分是整篇文章最干货的部分,是笔者在最近在 apex 使用中的踩过的所有的坑,由于 apex 报错并不明显,常常 debug 得让人很沮丧,但只要注意到以下的点,95% 的情况都可以畅通无阻了:
1. 判断你的 GPU 是否支持 FP16:支持的有拥有 Tensor Core 的 GPU(2080Ti、Titan、Tesla 等),不支持的(Pascal 系列)就不建议折腾了;
2. 常数的范围:为了保证计算不溢出,首先要保证人为设定的常数(包括调用的源码中的)不溢出,如各种 epsilon,INF 等;
3. Dimension 最好是 8 的倍数:NVIDIA 官方的文档的 2.2 条 [2] 表示,维度都是 8 的倍数的时候,性能最好;
4. 涉及到 sum 的操作要小心,很容易溢出,类似 Softmax 的操作建议用官方 API,并定义成 layer 写在模型初始化里;
5. 模型书写要规范:自定义的 Layer 写在模型初始化函数里,graph 计算写在 forward 里;
6. 某些不常用的函数,在使用前需要注册: amp.register_float_function(torch, 'sigmoid') ;
7. 某些函数(如 einsum)暂不支持 FP16 加速,建议不要用的太 heavy,XLNet 的实现改 FP16 [4] 困扰了我很久;
8. 需要操作模型参数的模块(类似 EMA),要使用 AMP 封装后的 model;
9. 需要操作梯度的模块必须在 optimizer 的 step 里,不然 AMP 不能判断 grad 是否为 Nan;
10. 欢迎补充。
总结
这篇从理论到实践地介绍了混合精度计算以及 Apex 新 API(AMP)的使用方法。笔者现在在做深度学习模型的时候,几乎都会第一时间把代码改成混合精度训练的了,速度快,精度还不减,确实是调参炼丹必备神器。目前网上还并没有看到关于 AMP 以及使用时会遇到的坑的中文博客,所以这一篇也是希望大家在使用的时候可以少花一点时间 debug。当然,如果读者们有发现新的坑欢迎交流,我会补充在专栏的博客 [5] 中。
Reference
http://market.itcgb.com/Contents/Intel/OR_AI_BJ/images/Brian_DeepLearning_LowNumericalPrecision.pdf

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐


