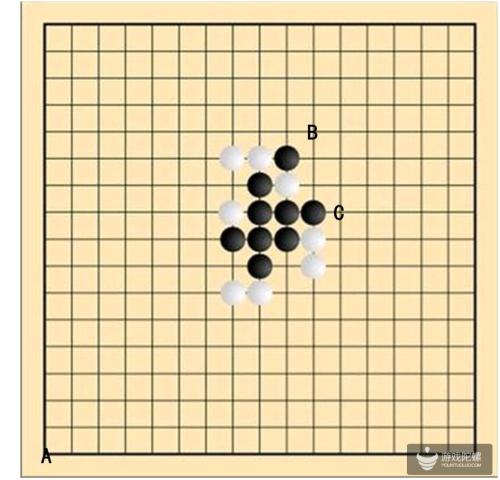
自律、分享、学习——打卡群成员成果分享(3月22日)
噔噔噔噔!大家看到这篇推送的时候想必已经是周五了,再坚持一下就又是一个愉快的周末了呀,在周末休息放松的同时,也不要把学习落下噢!
我们(CreateAMind)是骥智智能科技(上海)有限公司,致力于通用人工智能(AGI)与更智能的无人驾驶研发,做中国的DeepMind。为了与更多有志之士相互学习交流,我们建立了深度强化学习的学习打卡群。
这周群内的一位小伙伴向大家分享了他自己的一个研究成果,并且收到了广泛的好评:
在与该小伙伴取得沟通后,他表示很乐意将他的成果写到推送里分享给大家:
在此让我们都给这位小伙伴鼓鼓掌!希望他能在机器学习这条道路上继续努力下去,创造更多好的成绩!
当然群里的也有着更多优秀的小伙伴,我们之后也会为大家带来他们优秀的成果!
现在就让我们一起来看看今天这位小伙伴他的成果吧!
以下是他的文章内容:
——————————————————————————————
自制Alpha Go,基于深度增强学习和蒙特卡洛树搜索的五子棋AI(强化学习入门和毕设用)附代码
简介:Alpha Zero的风潮已经很久了,我在这里复现一个属于你自己的AI。鉴于本人不会下围棋(相信绝大多数朋友也不会下围棋,自制了一个AI总要与之对弈才有意思吧),而且围棋的样本空间要比五子棋大得多(围棋AI比五子棋AI难得多),在这里我们就应用Alpha Zero的算法做一个五子棋的AI吧。本文章是初学者入门向,小弟如果有什么疏漏还请各路大神尽情指出,不吝赐教。
算法分析:强化学习在这里主要由两个部分组成,一个部分是环境(environment),另一个部分是策略(policy)。环境由三个部分组成(状态(state),动作(action),奖励(reward))通俗点来讲,环境就是一个黑箱函数,该函数的输出为当前的state和上一个action的reward,而接受的输入为action。用围棋来举例子就是,围棋当前棋盘上的棋子的位置就是状态,而我们选择下了一步棋,那么棋盘的状态就发生了改变(多了一个字),我们之前选择下的那步棋的好坏就是我们的reward。而策略(policy)是在这里抽象为一个输入状态,输出action的函数。policy比较类似人类的思考过程,棋手(policy)通过观察棋盘(state),下了一步棋(做出action)。所以强化学习就可以理解为寻找一个输入状态输出动作,来使得我们的环境反馈的reward最大的一个函数。
明白了这个概念,下面我们就来说说五子棋的困难在哪里,假如说五子棋的棋盘大小为15 x 15大小,那么在遍历的情况下一共有(15*15)!≈10^435 可能。而且五子棋的胜负只有在一局棋结束的时候才能判别,在这之前我们很难衡量一步棋的好坏。这就需要我们的的蒙特卡洛树搜索(Monte Carlo Tree Search)算法了。
蒙特卡洛树搜索:
首先简而言之,蒙特卡罗树搜索本质上是一颗有不同节点(node)的树,节点与节点之间相连接。每个节点可以在这里可以代表一个棋盘的状态,假设我们的棋盘大小为15*15 ,而初始棋盘(棋盘上什么都没有的状态)的状态就是我们的最开始的根节点状态,而其下理论上有225个子节点,分别代表了初始玩家下在225个不同位置时的棋盘状态,而这225个字节点,每个子结点其下理论上又单独可有最多224的子节点,以此类推。对于每个节点,上面储存着该节点的访问次数(counter)与每一个子节点的Q值(每一个子节点相对于父节点来说代表着一个走子的动作{action},而Q值在这里可以简要理解为该动作好坏的评分)。PS:在这里我只简要介绍与强化学习相结合的MCTS,不介绍原版的MCTS,普通的蒙特卡罗树与我们这里使用的蒙特卡罗树有区别,请注意。
首先在我们的训练过程中,模型每次下出一步棋,会有两个流程。一个流程是模拟(simulation),一个是实际走子(play out)。模拟过程可以理解为,在我们正式走子之前,进行的预测(simulation),根据我们的预测结果来进行实际走子(play out)。
模拟:
与传统蒙特卡罗树搜索不同,Alpha Zero的模拟是在神经网络输出结果指导下的模拟。传统的MCTS算法如图所示(图片来自于维基百科)。
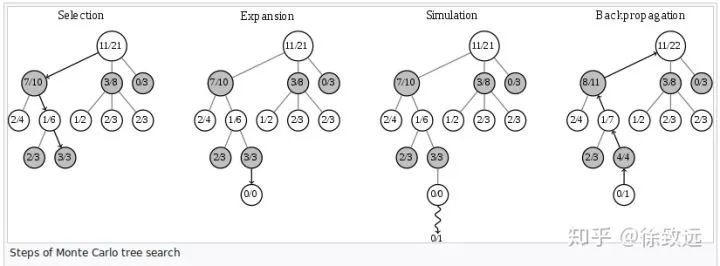
模拟过程一般会进行很多次,我们首先对其中一次进行讲解。对于传统的蒙特卡罗树搜索来说,首先基于选取一个“最优”动作(这里的最优要打引号,因为这并不是真的最优,而是当前该动作的一种综合 估计值+置信度 的衡量,具体后面讲UCB公式时我会讲。)。我们持续不断的选取“最优”动作,直到我们来到一个节点,并选择了一个我们之前从来每访问的动作,也因此这里并没有一个与该动作对应的节点。到这里我们完成了图中selection的部分。然后进入expansion部分,我们在这里创建新节点,记住,每次模拟只创建一个节点。然后进入MCTS的Simulation部分(注意这里的Simulation与上文中提到的模拟Simulation并不是同一个,做好区分)传统的MCTS会进行随机策略,抽象到棋盘上就相当于在棋盘上面随机走子。随机走子走到了尽头,我们就来到了Backpropagation的部分,我们将随机走子的结果(访问次数,胜负之类的信息)更新到这次模拟所经历的所有节点中,也就是说递归更新所有子节点的父节点。(对于一个节点来说,其执行一个动作会前进到其下的节点,其下的节点就是子节点,而相对于子节点来说,该节点就是父节点。如图中节点(12/21)是节点(7/10),节点(5/8),节点(0/3)的父节点,而这三个节点是(12/21)的子节点)。
我们这里使用的MCTS与传统的MCTS有所不同,首先在selection阶段,我们选择节点是根据神经网络指导下进行选择的,每次选择选取最大的upper confidence bound值的节点
UCB公式为:
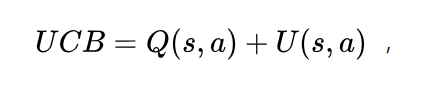
其中
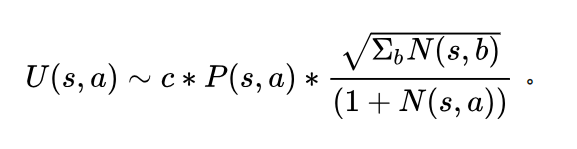
在这里UCB是一个权衡置信度(或者方差)和探索值的公式,通俗点来说,就是未探索的action和已经探索很多次但是探索反馈很高的action都会有较大的UCB值。Q值代表蒙特卡罗树中以探索的值,Q值的更新就是在之前蒙特卡罗树搜索中每一次backpropagation反馈的值的平均值。而P值是先验概率,是由神经网络计算得到的值,而N是该action的探索次数,而c是一个用于调节平衡模型探索的超参数。所以这个公式的特点就是,对于一个反复探索同时有很好的奖励的action,和缺乏探索的action都会有很高的值。这样就能很好的平衡探索与最优之间的平衡了。
其次的不同点是,在MCTS的backpropagation阶段,如果当前节点并没有分出胜负,是由神经网络进行打分(value),反馈的是value而不是随机探索出来的结果。具体value是什么我们放在神经网络阶段继续讲解。
走子:
当模拟过程结束后,我们进入了走子过程。在这一步我们用不同action的探索次数之间的比例当作我们实际的概率分布,我们按照该概率分布选择我们的action(概率可以增加一点噪音做一些额外的exploration)。这里的概率分布要保存下来,训练神经网络的时候要用。我们按照 模拟 - 走子 - 模拟 - 走子的流程一直走下去,直到我们的游戏结束。游戏结束的时候我们将游戏记录保存下来,可以用于神经网络的训练。
神经网络:
本文中所用的神经网络结构可以自行设计的,原文中使用了一个40个block的ResNet,在这里我们就不强调使用Resnet,任由各位自由设计。神经网络输入为当前棋盘,原版输入是一个17x19x19的大型矩阵,有8个代表自己下棋的历史记录,8个代表对手下棋的历史记录,另外一个代表当前player。我们在这里也做一些简化,保留当前player的输入信息,将自己的历史记录和对手的历史记录都压缩为一个channel。这样我们的输入就为3 x board size x board size的矩阵。输出为双端口,分别为当前棋盘的状态值(value)和当前棋盘各个位置的走子的概率。关于状态值,你可以理解为一个机器评价的当前局面的“好坏”。另一个不必过多赘述,就是走棋盘每一个位置的概率。而更新的Loss function定义为:
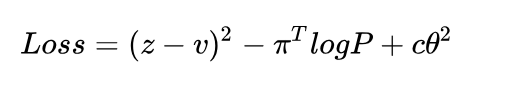
其中v是value,z是当游戏结束的时候的实际的胜负,对于当前的player来说,如果他胜利了z的值就是+1,如果是失败了就是-1。在这里我们做一个回归的loss,经过大数据的训练,神经网络会掌握一个宏观的胜负概率的。而第二项是我们神经网络的输出与MCTS探索出来的概率分支之间的交叉熵,第三项就是一个L2正则项。
在这里我们选择普通的SGD进行优化,虽然Adam优化具有更好的收敛速度等优点,但是收敛性能却未必比SGD好。见仁见智,各位读者可以按照自己的喜好来做。
代码
完整的代码请看这里(跪求各位大佬给星星)
github.com/pandezhao/al
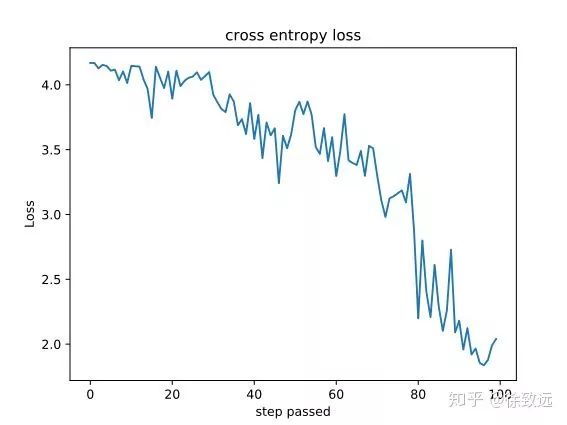
效果展示:
这是经过自我对抗1000局训练出来的自我对抗的记录:

Loss经过训练,cross-entropy的loss大概会下降到2点多左右:
完整的代码请看这里(跪求各位大佬给星星)
github.com/pandezhao/al
总结+下集预告(下集也可能没有!!既然是薛定谔的有没有,为什么不通过“观测”我来确定是否有没有呢?)
到这里为止我们已经基本完成一个简化版的工作了,后续我还会择机更新一个带多线程数据生成来适用于多机运行的程序,以及看情况更新一个Alpha Zero中的“新的模型对抗老的模型胜率达到55%才会取代老模型”的功能,以及其他一些杂七杂八的功能或优化。
在这里恬不知耻的求赞求关注~, 也希望各位知乎大佬能够指教一二。
顺便一提,知乎上已经有前辈写过一个五子棋了,在这里我也把他的文章链接附加上来,用于各位拓展学习。
致谢:感谢我Li Lab实验室里的两位大佬给予的各种支持,在此感谢
@恒拓
@二月的逆流
参考文献:Mastering the game of Go without human knowledgeAlphaGo Zero: Mastering the game of Go without human knowledge
________________________________________________________________________
以上就是这次分享的全部内容了,是不是觉得非常精彩?让我们再次为这位小伙伴鼓鼓掌!!
当然,如果你有关于文章里面的疑问或者想和作者交流探讨的欢迎你直接联系作者或者加入到我们的打卡群当中!!
群内已有50+成员,每周二、四、六准时打卡,分享学习经验。
详情请点击:最严强化学习打卡群。
我们期待更多的人加入我们,与我们一同为AI学习添砖加瓦!
如果你有自己的实验成果想要展示或者有想和大家分享交流的学习经验我们随时欢迎你的加入!!
同时,如果你有志研究和开发自动驾驶技术、提升AI的智能、提高自动驾驶的智能水平,我们欢迎你的加入!
年薪百万来奋斗-骥智CreateAMind2019招聘目标:年薪百万招聘大牛50+ 推荐成功送mate20
最后祝各位读者有个愉快轻松的周末!我们下周再见!!