一次完整的零停机 Redis 迁移案例

作者丨Sameer Suresh
策划丨小智
在 Nextdoor,我们大量使用了 Redis 这个高性能的内存数据存储,为我们的许多服务提供低延迟的数据访问。现在,我们通过 ElastiCache 使用着十几个不同的 Redis 实例;其中有许多对应于我们的微服务或我们的主要应用 Django 中的特定用例,比如 AB 测试跟踪。它们可以作为数据的真实来源,也可以纯粹作为缓存来提升性能。
除了少数例外,我们大多数的 Redis 部署最初创建时都是主副本节点的单一实例,这样,我们可以保证单个节点的故障不会造成数据的永久损失,同时,我们可以在故障转移时继续提供服务。此外,通过将特定的用例隔离到它们自己的 Redis 实例,我们还可以实现不同的故障模式,限制单个问题的影响。虽然这听起来很像高可用性数据存储的要素,但我们意识到,我们还没有完全做到这一点,特别是当我们的一些实例达到了其负载能力的极限时。在这篇文章中,我们将解释可用性方面的一些缺陷,这些缺陷最终导致我们重新构建我们的整个实例集,以及我们用来监督这个迁移过程使其不影响任何核心服务的方法。

例如,让我们考虑这样一个场景:一个 Redis 实例由一个主节点和一个副本节点组成,在接近 CPU 最大处理能力时触发了故障转移(可能是副本节点遇到了硬件问题,需要准备一个新节点)。主节点现在开始获取其自身的快照,并将其发送给新的副本节点,这将导致主服务器达到最大处理能力。此时,到这个 Redis 实例的请求开始超时,可能一些用户开始看到功能受限。我们甚至可以更进一步;如果我们的 Redis 客户端不够智能,无法恰当地处理这些超时,可能会引起连锁反应,我们可能会备份关键服务的所有流量。
虽然这只是一个特殊的例子,但我们已经确定了一组使我们的 Redis 配置变得脆弱的关键的底层问题。一方面,CPU 利用率成为保证可用性的一个重大瓶颈,这不适合那些一天中经常出现突发事件和流量峰值的服务。然而,更重要的是,没有一种简洁的方法可以用来扩展我们的 Redis 实例以满足我们的服务需求(只能购买更大的实例类型,但这不是一个很有远见的解决方案)。
幸运的是,这类问题相对比较常见,而 Redis 本身提供了一种可以解决这个问题的集群模式。使用集群,我们的数据分布在多个分片上,每个分片拥有整个键空间的一部分。从可用性的角度来看,这是有好处的,因为它允许我们在必要时水平地扩展我们的 Redis 实例(只需向集群添加新节点),而不需很长的停机时间。此外,上述重大问题的影响也有所减轻;如果一个分片达到了 CPU 处理能力,那么剩下的分片可以继续正常运行,因此,问题仅会影响一小部分请求。
随着规模的不断扩大,我们开始着手升级我们所有的 Redis 部署,以下是几个需要优先考虑的事项:
切换到集群化 Redis:这可以满足我们的水平扩展需求,并从根本上解决上述所有问题。
升级旧的实例类型:我们的大多数 Redis 实例都错过了与新硬件结合的性能提升,因此升级可以进一步缓解我们对高 CPU 利用率的担忧。
尽量减少迁移过程的停机时间:由于我们的许多 Redis 实例都是我们的核心服务的组成部分,所以迁移到新实例的过程中不影响会员的体验很重要。
在这里,我们遇到了最大的挑战:弄清楚迁移的过程。虽然我们非常清楚我们的最终状态应该是什么,但是,最后一个要求——最小化停机时间——排除了许多我们可能最终用来切换到新实例的方法。值得注意的是,我们迁移到集群 Redis 的目标意味着我们可能无法直接通过 AWS,因为 AWS 只支持在不更改集群模式的情况下升级引擎版本(例如,从非集群到非集群或从集群到集群)。为此,我们最好的选择是手动创建一个新的单分片的 Redis 集群,从旧实例的备份中恢复它,然后在稍后扩展分片的数量——在几个小时的迁移期间里不能接受写流量。为了实现这三个目标,我们需要一点创造力来帮助我们实现迁移。
大约在这个时候,我们刚刚开始研究 Envoy 的用法,这是 Lyft 构建的一个分布式代理,它为基于微服务的大型架构提供了更好的可观测性。Envoy 使我们能够在服务中添加故障注入和健康检查等功能,从而可以测试推送的稳定性,只需将其与这些服务一起部署即可。它还可以作为一个 Redis 代理,更具体地说,它可以跨不同的上游集群处理 Redis 请求的路由。在这里,我们找到了大规模 Redis 迁移所需的完美抽象;通过将 Envoy 作为中介添加到所有的 Redis 实例,我们可以更智能地协调将数据迁移到新的 Redis 集群的过程,同时继续为用户提供服务。为了说明这一点,让我们按顺序看下从旧实例切换到新实例所需的全部事件。
第一步:将所有流量代理到旧实例
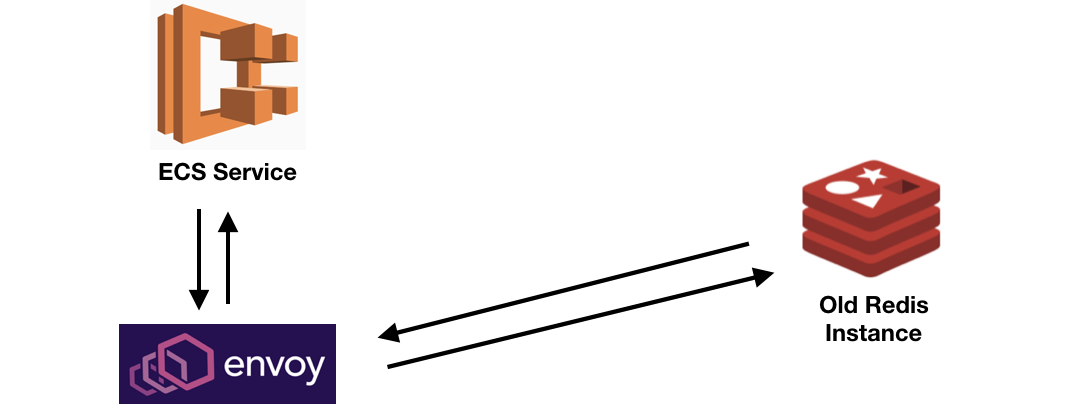
Envoy 作为我们服务的跨斗(sidecar)Docker 容器运行,我们只需修改服务,将 Envoy 视为其上游 Redis 主机。Envoy 负责侦听 Redis 请求的特定端口,它直接将请求(读和写)转发给实际的旧 Redis 实例。重要的是,除了修改 Redis 的地址外,不需要在客户端进行任何更改,客户端基本上不知道它的请求不会直接发送到 Redis(一个例外是原来的 Redis 实例已经集群化;在这种情况下,客户端可能需要改成使用普通的 Redis 客户端库,而不是集群化 Redis 库,因为 Envoy 的行为类似于“非集群化 Redis”)。
第二步:将写入镜像到新集群
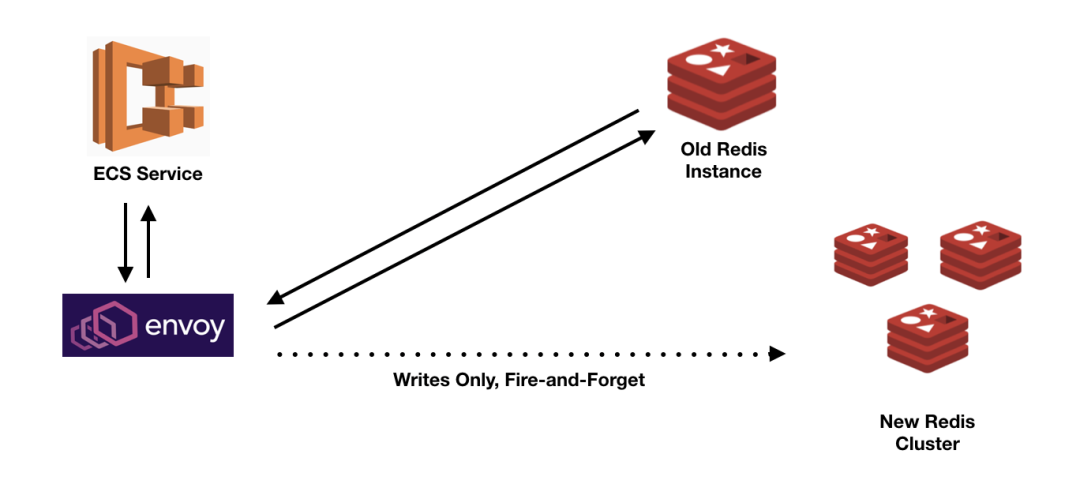
在根据必要的规范配置好新的 Redis 集群之后,我们修改了 Envoy 的 Redis 侦听器定义,将其镜像或双写到新的集群化 Redis。这样,任何新的写入都可以同时写到旧的和新的 Redis 实例。请注意,Envoy 采用了双重写入的即发即弃模型,因此,它不会等着确认新集群的写入是否成功,但通常这里很少出现任何问题。这时,新的 Redis 集群仍然远远落后于旧的集群,但是我们已经比较确定,在实际同步之后,这两个集群不会再次出现差异。
第三步:将内容完整地回填到新集群
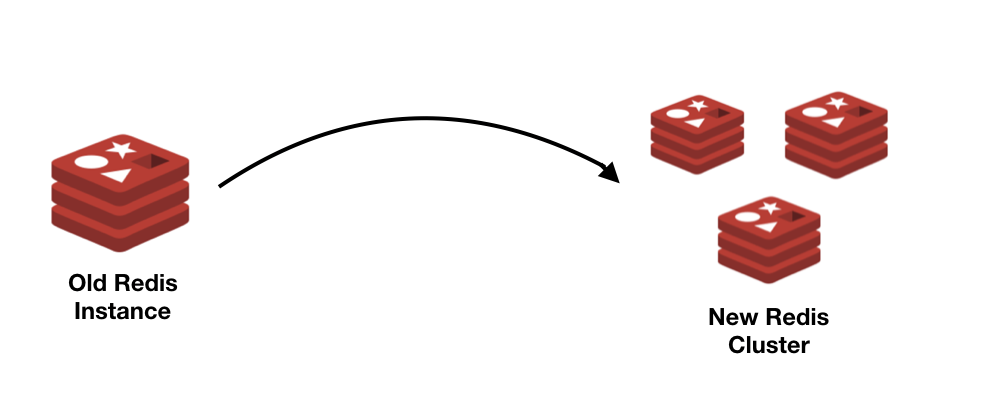
这一步是计算最密集的,需要扫描旧的 Redis 实例并将其所有内容复制到新实例。为了更有效率,我们使用了 RedisShake(一个来自阿里巴巴的优秀开源工具),并围绕它封装了我们自己的 ECS 服务来自动同步。请注意,与捕获快照非常相似,运行此脚本也有挂载 CPU 的能力,因此必须特别注意,使用合理的 QPS(即每秒查询次数)和设置来运行脚本,并且最好在低流量期间运行脚本。现在,这两个实例应该完全同步了,任何错过的双写都应该被捕获了。
第四步:验证并切换
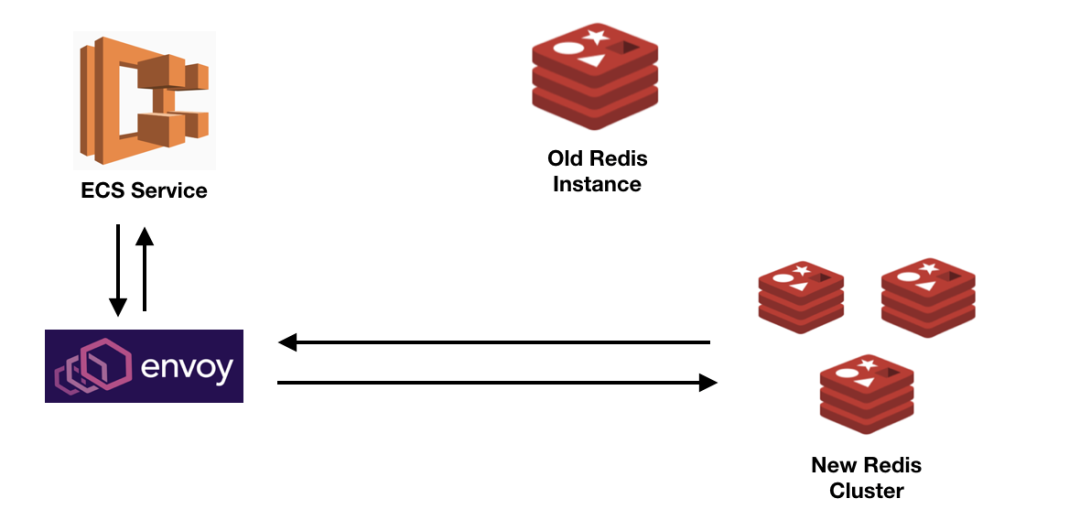
为了确保这两个实例是同步的,我们运行 RedisFullCheck 工具,它经过几轮比较后可以区分旧实例和新实例之间存在差异的键,并将它们存储到 SQLite 数据库中。在我们的例子中,键的差异更可能是因为某个地方某个特定的 Redis 用法与 Envoy 不兼容(下面将描述这些不兼容),而不是因为回填脚本遗漏了写操作;这一步可能需要一些调查工作。一旦检查脚本结果没有问题,我们最后会再次更新 Envoy 侦听器配置,将所有的流量全部路由到新集群,并删除旧实例。
使用上面的策略,我们成功地将所有的 Redis 实例迁移到一个最终状态,其中每个实例都是集群化的,并运行最新版本的 Redis。然而,在实践中,我们发现这种方法也有其局限性,特别是在 Envoy 的使用上。最重要的是,我们发现,Envoy 只支持散列到一个分片的 Redis 请求,它排除了所有与集群相关的命令(由于我们的大多数实例以前都不是集群化的,所以我们很幸运,没有很多这样的命令)。因而使用 Redis MULTI 命令的任何事务逻辑也不受支持。为了解决这个问题,我们修改了基于事务的代码,改为使用 Lua 脚本,它以与 Envoy 兼容的方式提供了相同的原子性优势。
原文链接:
https://engblog.nextdoor.com/data-migrations-dont-have-to-come-with-downtime-eabc15893700
InfoQ 读者交流群上线啦!各位小伙伴可以扫描下方二维码,添加 InfoQ 小助手,回复关键字“进群”申请入群。大家可以和 InfoQ 读者一起畅所欲言,和编辑们零距离接触,超值的技术礼包等你领取,还有超值活动等你参加,快来加入我们吧!


点个在看少个 bug👇




