谷歌大脑提出概念激活向量,助力神经网络可解释性研究
选自 KDnuggets
最近,谷歌大脑团队发表了一篇论文,文中提出了一种叫做概念激活向量(Concept Activation vectors,CAV)的新方法,这种方法为深度学习模型的可解释性提供了一个全新的视角。
论文地址:https://arxiv.org/pdf/1711.11279.pdf
GitHub 地址:https://github.com/tensorflow/tcav
可解释性与准确率
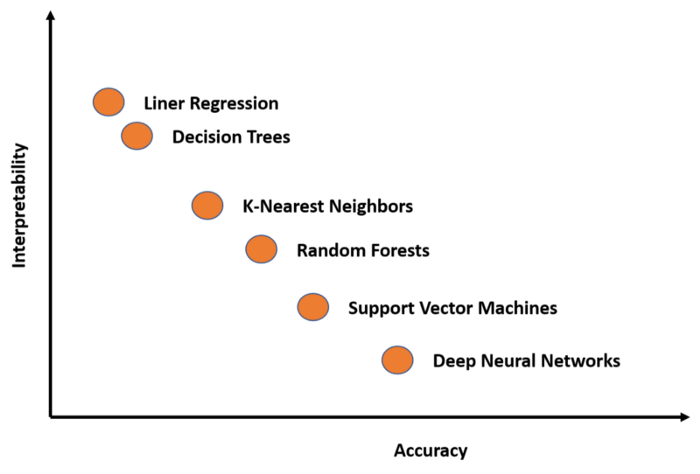
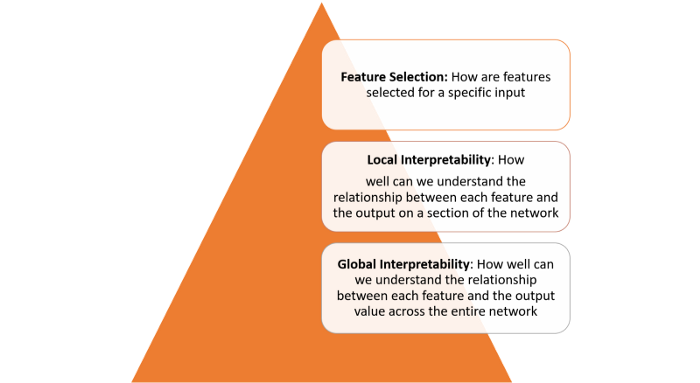
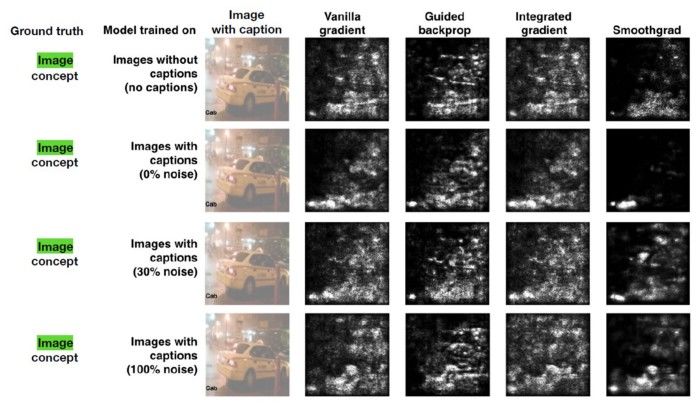
理解隐藏层做了什么:深度学习模型中的大部分知识是在隐藏层中形成的。要解释深度学习模型,必须要从宏观角度理解不同隐藏层的功能。
理解节点是如何激活的:可解释性的关键不是理解网络中单一神经元的功能,而是要理解在同一空间位置一起激活的互相连接的神经元组。通过互相连接的神经元组分割网络可以从更简单的抽象层次来理解其功能。
理解概念是如何形成的:深度神经网络如何形成可组装成最终输出的单个概念,理解这一问题是另一个关键的可解释性构建块。
易于访问:用户几乎不需要 ML 专业知识。
可定制化:适应任何概念(比如性别),而且不受限于训练过程中所考虑的概念。
插件准备:不需要重新训练或修改 ML 模型就可以直接工作。
全局量化:用单个量化方法就可以解释整个类或整组示例,而且不只是解释数据输入。
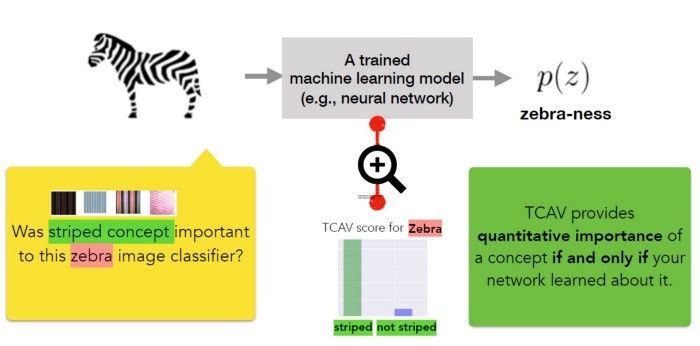
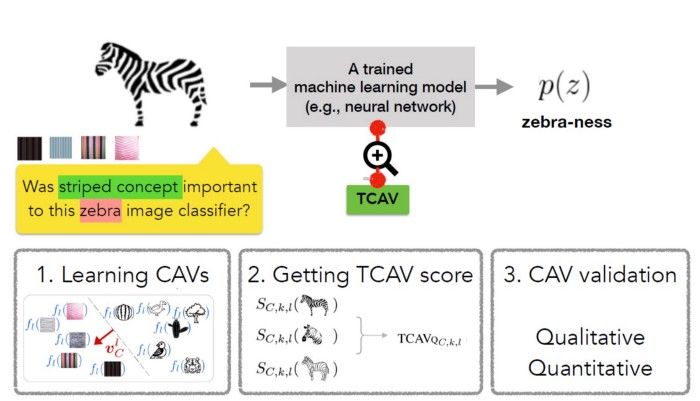
给模型定义相关概念;
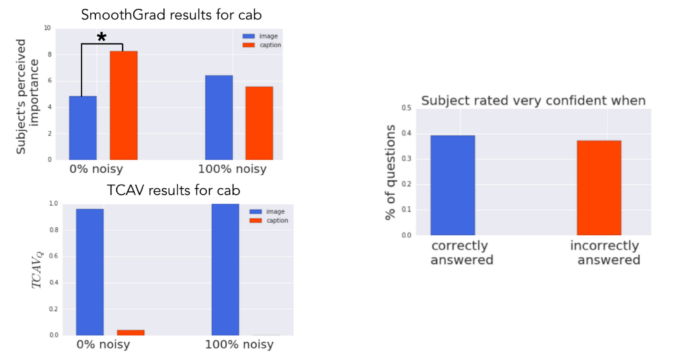
理解预测结果对这些概念的敏感度;
全局定量解释每个概念对每个模型预测类的相对重要性。
登录查看更多
相关内容

会议涵盖了从理论结果到具体应用的各个方面,重点讨论了实际的验证工具以及实现这些工具所需的算法和技术。CAV认为,在向生物系统和计算机安全等新领域扩展的同时,继续推动硬件和软件验证的进步至关重要。会议记录将发表在《计算机科学》系列的斯普林格-维拉格讲稿中。预计将邀请一些论文参加《系统设计中的形式化方法》专刊和《ACM杂志》。官网链接:http://i-cav.org/2019/
Arxiv
4+阅读 · 2019年11月5日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年11月5日