导 读
在星际争霸 2 的首场「人机大战」结束后不久,DeepMind 又宣布即将投身另一个游戏「烟花」。与以往不同的是,这是一款非完整信息、多人合作的游戏。研究人员相信这项研究可以带来全新的技术,引导 AI 学会自我学习以及与人类合作的新方法。
来源:机器之心
编译:王淑婷、贾伟、李泽南
物联网智库 转载
转载请注明来源和出处
导 读
在星际争霸 2 的首场「人机大战」结束后不久,DeepMind 又宣布即将投身另一个游戏「烟花」。与以往不同的是,这是一款非完整信息、多人合作的游戏。研究人员相信这项研究可以带来全新的技术,引导 AI 学会自我学习以及与人类合作的新方法。
近日,DeepMind 与 Google Brain 团队合作发布了 Hanabi 学习环境(HLE)的代码和论文,这是一个基于流行纸牌游戏的多智能体学习和即时通信研究平台。HLE 为 AI 智能体提供了一个游戏界面,并附带了一个基于 Dopamine 框架的学习智能体。
项目 GitHub:https://github.com/deepmind/hanabi-learning-environment
《Hanabi》是以日文命名,中文的直接转写为「花火」,顾名思义就是烟花的意思,它由法国人 Antoine Bauza 设计。这是一款 2-5 人的合作游戏,玩家们尝试通过以正确的顺序在桌面上放置卡牌创造完美的烟花。
在 Hanabi 中,共有五张不同颜色的卡片序列。让游戏变得有趣的是玩家可以看到队友的牌,但不能看到他们自己的牌。沟通在很大程度上通过「提示」动作发生,其中一个人告诉另一个关于他们的牌的事情,以便他们知道要玩什么或丢弃。由于可以提供有限数量的提示,优秀的玩家可以进行战略性沟通并利用惯例,例如「首先丢弃最旧的卡片」。
顶级 Hanabi 沟通战略是「finesse」:finesse 是一个队友的举动,乍一看似乎很糟糕(对我们而言),但如果我们假设队友知道我们不知道的事情,实际上是很棒的。假设我们的同伴玩得很好,我们可以排除这个「第一眼」的解释,并总结一下自己的牌。基于技巧的典型推理可能是:「我的队友知道'红色 2'非常有价值。然而她故意放弃了她的「红色 2」。唯一合乎逻辑的解释是,我现在正拿着另一个'红色 2'。「(如果你玩纸牌游戏 Hearts,你会熟悉黑桃皇后的类似游戏)。由于「finesse」,玩家最终会对游戏形成复杂的解释。从应急沟通(emergent communication)的角度来看,「finesse」很有吸引力,因为玩这个游戏和理解它们都需要超越提示的字面含义并推断出队友的意图——有时候称为「theory of mind」。
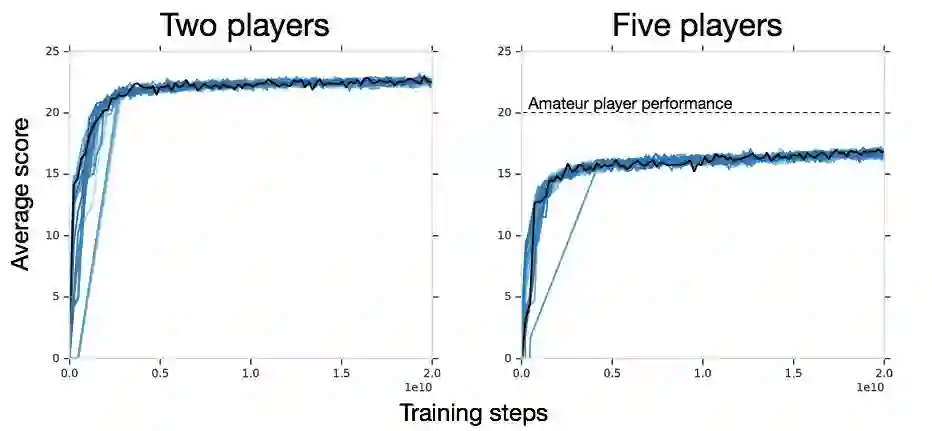
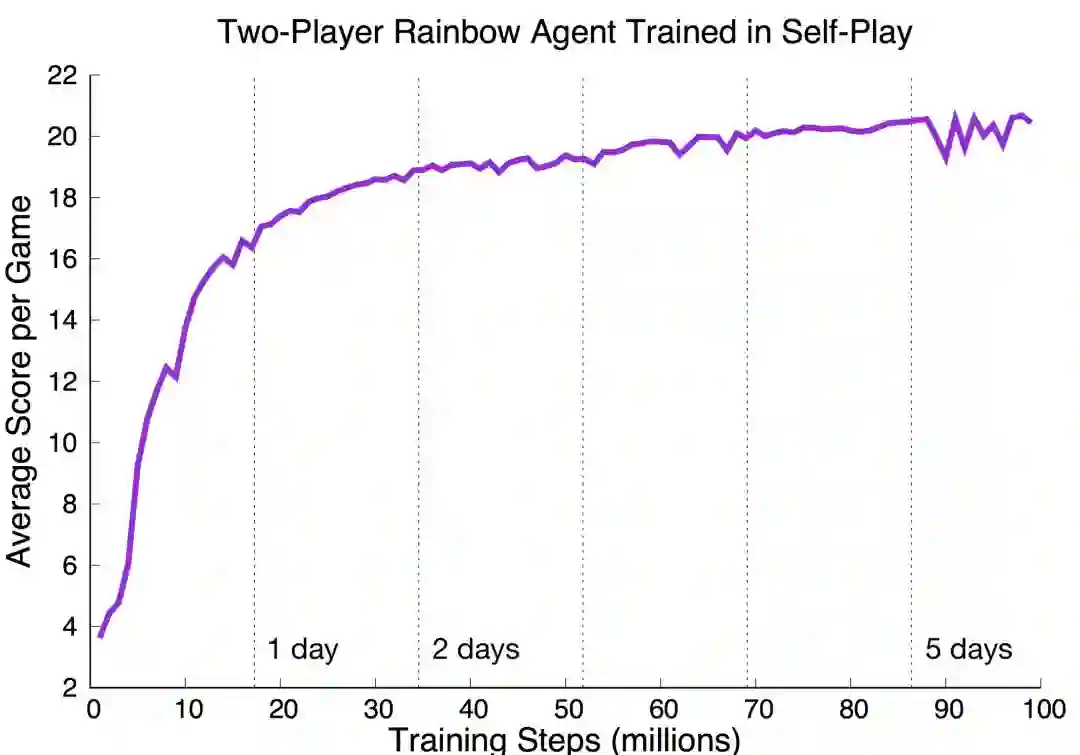
那对于 Hanabi,现有的强化学习方法如何呢?事实上,并不如想象的那么好。DeepMind 的第一个实验通过向修改后的重要性加权 Actor - Learner 通过提供有效的、无限量训练来推动这一趋势。他们确定了 200 亿次「有效无限」的动作:这个数字相当于大约 3 亿次游戏或 1.66 亿小时的人类游戏(如果假设一个休闲玩家每次移动大约需要 30 秒)。该算法使用自身的副本进行训练,称之为「self-play setting」。虽然该算法在双人游戏环境中可以学习成功的惯例(平均 22.73 分,可能总共 25 分),但它在四人和五人游戏环境中的表现要比专业玩家或手动编码的机器人差得多:
研究人员在第二次实验中证实了这些发现,这次实验中使用了 1 亿次移动这样更合理的预算,以及我们发布的修改后的 Rainbow 架构(你可以试试:大约 16 小时内在一个 GPU 上训练能够获得 15 分的智能体)。Rainbow 在 2 人游戏中表现也不错,但是在 4 人和 5 人游戏中表现相当差。虽然确实有些技术(如 BAD 方法)能够提高这些分数,但是实现它所需的样本数量表明,在 Hanabi 中发现惯例仍然是一个未解决的问题。
然而,打破自我游戏设置只是一个开始。在其他环境中成功的交流需要高效的编码(不要浪费文字)和适应性(理解听众)。当我们遇到新的人时,我们可能不会对语言的所有术语都达成一致,因此我们倾向于让事情变得更简单一点。例如,DeepMind 将 operator 规范和 Lyapunov 函数排除在(大多数)社交会面之外。适应能力的需求是 Hanabi 的核心:当和一个新的团队一起玩时,这样做你承担的风险才更小——或许是没有进行联系就落子,或许是等待队友先走第一步。虽然人类很容易适应陌生的听众,但 DeepMind 目前最好的智能体却做不到:它们遵循复杂且相当僵化的惯例。
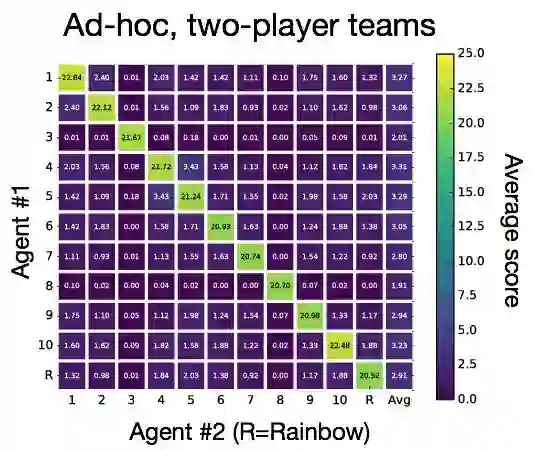
当一个智能体被要求与不熟悉的智能体合作时,这种情况被称为「特定团队游戏(ad hoc team play)」。当自我游戏(self-play)环境要求我们学习最好的惯例时,特定团队游戏需要适应先验未知的惯例。在本文中,DeepMind 团队发现用自我游戏策略训练的智能体在特定环境中惨败。在一个实验中,DeepMind 挑选了 10 个完全训练的 actor-learner 智能体,actor-learner 智能体得分超过 23 分。相比之下,新团队几乎立即出局,平均得分为 2~3 分。DeepMind 发现使用类似相关矩阵的东西来可视化这种效果是有用的,对角线对应于自我游戏评估:
从长远来看,一个提供随机提示的简单手动编码策略平均得分为 5.1 分。当然,这并不是什么很惊奇的事,因为 DeepMind 设计的这款自我游戏智能体并不适合其他玩家。话虽如此,其影响大小的变化(从接近完美到接近零)说明这是现有智能体的一个重要缺点。
很明显,考虑过去十年的结果,机器学习潜力惊人。AI 的下一大步将是让智能体学会交流和推理意图。与 Atari 2600 游戏对深度强化学习领域的激励类似,Hanabi 是一个很好的培养皿,可以用来测试算法如何在对人类来说简单但对 AI 来说比较挑战的场景中学习合作。DeepMind 团队期待能够从 Hanabi 研究中看到完美的合作。
论文:The Hanabi Challenge: A New Frontier for AI Research
论文地址:https://arxiv.org/abs/1902.00506
摘要:在计算机的发展历史上,游戏一直是研究机器如何做出复杂决策的重要试验平台。近年来,机器学习取得了显著的进步,人工智能体在很多领域取得了超越人类专家的表现,其中包括围棋、Atari 游戏以及一些扑克游戏。与它们的国际象棋、跳棋、双陆棋前身一样,这些游戏通过复杂的定义和挑战推动了人工智能的研究。在本论文中,我们希望将「Hanabi」游戏作为新的挑战,这一领域具有新颖的问题,这些问题源于纯粹合作的游戏玩法,和 2-5 个玩家环境中不完全信息的结合。
特别的是,我们认为 Hanabi 将试图理解其它智能体的意图推理推向了前台。我们相信开发能够使人工智能理解这种心理理论的技术不仅可以玩好这款游戏,还可以应用于更广泛的合作任务中——尤其是那些与人类合作的任务。为了便于未来研究,我们引入了开源的 Hanabi 学习环境,为研究人员提供实验框架,用于评估算法的进步,并评估当前最先进技术的性能。
往期热文(点击文章标题即可直接阅读):