第四范式 ‖ 大规模机器学习平台的整体架构和实现细节(万字解析,附PPT)
近日,第三届“国际人工智能与大数据高峰论坛”在北京国家会议中心召开,本届峰会聚焦于前沿人工智能技术与产业应用。
作为人工智能行业领军人物,第四范式联合创始人、首席架构师胡时伟受邀出席大会,并以“大规模机器学习平台的技术实现”为题,发表了主题演讲。
胡时伟曾主持了百度商业客户运营、凤巢新兴变现、商业“知心”搜索、阿拉丁生态等多个核心系统的架构设计工作;后作为链家网创始团队成员,从0开始完成链家网新主站的架构设计,推动链家系统和研发体系的互联网化转型。
现任第四范式首席架构师,带领研发团队打造出国内首款人工智能全流程平台“第四范式·先知”。
以下内容根据胡时伟主题演讲编写,略有删减。
大家好!我是来自第四范式的胡时伟,非常荣幸能够与大家分享第四范式在AI技术方面的探索以及全新的尝试。
首先,我们讲到人工智能时,大家会问,它是不是还停留在一个不确定是否成立的时代?尽管它已经可以做一些图像识别的工作,在下围棋或者打游戏等方面甚至战胜了人类。但是人工智能在商业和工业生产领域的实际表现如何呢?
我们列出了以下几个方向,均是第四范式在服务客户的过程中,真正利用人工智能技术产生效果的领域,比如实时风控、交易反欺诈、个性化推荐等,这些领域都实现了运营效果数倍的提升。
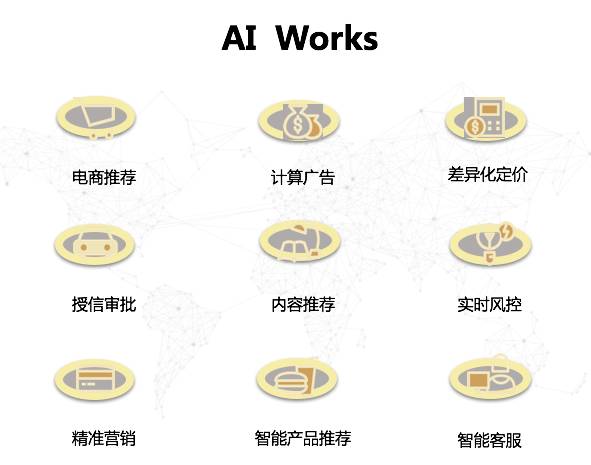
AI为何能促进业务提升呢?我们总结了一下,在以下三个方面,AI会和以前的方式有所区别。
首先是精细,人工智能系统对个性化和微观业务场景的分析和预测能力的要求已经超过过去的想象。以反欺诈为例,如今,大部分交易都已经转移到移动支付或者互联网上,欺诈交易的比例和绝对数量变得越来越多。
我们过去怎么解决这个问题呢?
每当出现一笔欺诈交易时,由案件中心来对交易进行分析,然后整理出一些规则,例如这笔交易的金额大于某个数额,或是一定时间范围内,该笔交易的地点与上一个交易地点之间的距离过大,案件中心会认为它是一笔欺诈的交易。
实际上,在影响欺诈的因素当中除了强规则,还有很多长尾因素,例如全国每一个区域发生交易欺诈的规律都是不一样的,所以过去专家整理出的上百条规则只能对全国的交易进行分析,而对于每个具体的省市,甚至是某一个村,这些规则其实是覆盖不了的。

如今,我们利用AI技术,可以实现更加精细的分析和预测。就像上图表示的一样,传统的方式是基于一些规则将人群划分,假设全国有两亿名移动支付用户的话,划分为上百种人群,单一群体就有两千万,丢失了对每个客户的个性化描述。
而机器可以把客群分成上千万甚至是上亿份,可以直接定位到个人来总结出统计规律,这样便不易造成误判或者是漏判。
其次是智能。此前,为了产生商业智能我们会利用大数据进行分析,去找规律中的较强的变量。
但随着时间的变化,这些变量会发生一定的改变,例如在营销领域,以往的做法是找出一些规则——买苹果手机或者相机可能是高端的消费,对其进行营销比较有效果。但是不同时代的高端消费品是不同的。
所以,采用专家规则的话,每隔三个月到半年就要对规则进行更新,人工智能则不然,我们可以基于数据做成一个闭环的系统,它能够用机器代替人,从广泛的数据当中筛选出海量的规则,并且规则以及权重可以随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
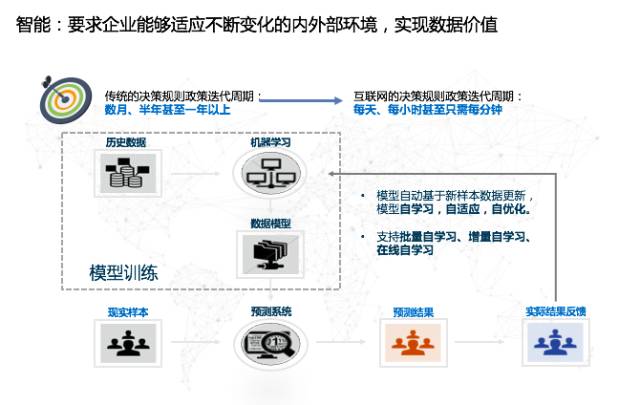
最后一点是高效。之前提及的反欺诈、新闻推荐、营销等领域,它们对实时性的要求越来越高,反欺诈系统必须在几十毫秒之内判定交易是否有问题,营销系统需快速判定客户对某个商品的消费意愿。在某种意义上讲,企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
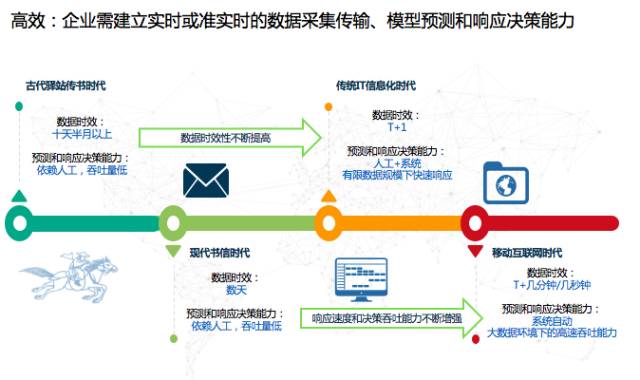
那AI究竟是什么呢?在AlphaGo1.0时代,它学习了几千万盘的棋谱数据,并依靠深度学习、迁移学习,强化学习等机器学习算法,成为了围棋界的顶尖高手。
我们认为大数据就是大米,机器学习是电饭锅,人工智能就是做出来的米饭。在AI领域,就是利用各个领域的海量数据,依靠机器学习的方式,来输出人工智能的能力。
我们认为构建商业AI的能力有5个要素,分别是有意义的过程数据、反馈数据、算法、计算资源、业务需求。
这里通过一个实际案例来解释这5个要素,假如我是一个市场覆盖率很高的点餐Pad提供商,为了实现AI一键点餐的功能,增加食客满意度,同时提升翻台率,那么我就需要收集食客们历史点菜记录、浏览记录,以及当前餐馆的菜品安排、客流量等等相关数据,也就是上文提到的过程数据。
此外,企业还需要找到可被机器学习优化的业务目标。比如,尽管点餐Pad的最终优化目标是翻台率,但企业需要将它转换为机器能够理解并且优化的指标,即点餐时间、上菜时间,食客进食时间这三个指标,只要能够提升这三项指标,就可以提高翻台率。
假设餐厅有25种菜,PAD选择推荐一道菜,即使推荐错,也并不太会影响实际体验。但这个反馈数据可以用于判断某个食客对某道菜品的喜爱程度,将这个概率和厨房做菜时间、菜品平均进食时间等指标,合做成函数后进行排序,再通过Pad实时推荐的方式供给客户选择。
这样就完成了实际需求(翻台率)到机器学习问题(某个人喜欢某个菜品的概率)的转换。
除此之外,企业还需要收集数字化、不间断的反馈数据,形成闭环。今天给顾客A推荐了X这个菜,如果他选择了,就反馈1,不选择就反馈0。这些数据在如今很多企业以及场景中是可以收集的,因此我们要把数据的采集及存储过程做好。
如今,有很多行业已经具备了以上三个要素,为什么AI并没有广泛的应用?我们认为还缺少算法和计算资源。如果我想判定A喜不喜欢X,机器会给出一个概率,算法解决的是让这个概率变得更准。
像AlphaGo、无人驾驶、人脸识别等运用的机器学习算法,其实都是用大量的计算资源来对数据进行计算,优秀的算法下层还要有很强的计算资源来支持。
对于企业来说,想要走向AI时代,应该具备什么样的条件呢?首先从如何利用数据的角度上讲,这个数据的维度应该是数千万到数十亿的。
我们不仅要进行全国欺诈交易规则的判定,还要精细到每个省、市、村,每个商品、每类人群。如果要把全国十几亿人划分成不同的组,每个组里面可能有几千万人,这就需要非常庞大的AI进行大规模的特征工程探索。
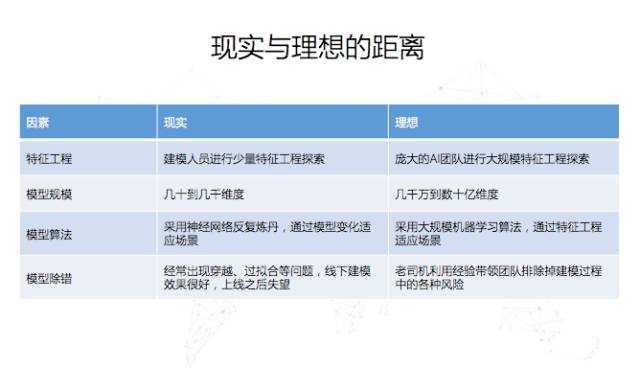
我们今天应该考虑的是以省的成分去区分还是以市的成分去区分,如果以市的成分区分,那这两个市是合并还是区分。
如果用人工的方式,我们就需要非常多的技术人员或业务专家通过一些方式去写算法或者规则。假设我们有几千万条数据,将这些数据进行机器学习时,是需要一个非常大规模的算法。
如今,在业界最为流行的算法就是神经网络,神经网络最大的特点就是深层,深层的神经网络能够表示的客观现象非常丰富。理论上说,对于训练好的网络,我们把数据输入进去,它会告诉你哪个是猫和狗。
但是实际上,这个训练好的网络非常难获得。我们用神经网络去判断一个交易是不是欺诈,还是判别每个食客对这个菜是否产生兴趣时,神经网络的结构和中间的函数,都需要经验丰富的机器学习专家来进行反复的调试。
通常大家会说这个过程是炼丹,通过一个模型的变化,来适应场景,这就导致企业面临需要招聘大量AI人才的困境。且反欺诈的模型,是不复用在点餐PAD上的。
这里面存在着一个改进的机会,本身人去探索模型的过程,是不是也可以被机器替代?我们可否用一个人工智能的数据科学家去替代人,并通过特殊工程的方式自动的对场景建模。
另外还有一个点叫做模型除错。建立好的模型在实际的应用过程中,会出现各种各样的问题,其中最常见的就是过拟合。
教科书上告诉大家要做交叉验证,但验证过程中,发现你的模型在线下销售特别好,线上却出现大量时间序列的问题,比如我们利用历史数据得到规律去预测未来。
但由于数据极为复杂,有时却无法分清哪些是历史和未来,这与系统如何设计信息有关系,理想状况下,专家会利用经验排除过程中的风险。
如何把一个团队的数据工程师变成AI专家呢?我们认为需要对下图这四个方面进行一些改进。首先是特征工程,它是把原始的数据通过一些方式进行衍生,能够把人群能够划分足够精细的这么一种变量衍生的方式。

其次是模型规模。我们原先用统计的方式做模型,通常有十到二十个变量,现在用大数据、分布式的方式可以做到成百上千个变量。由于现在拥有海量的数据,所以足够支撑一个上亿乃至数千亿规模的维度变量,这就需要极高维度、分布式的机器学习系统。
另外在模型算法和除错方面,我们也需要一些成型的产品,让数据科学家、工程师直接调用,产生有效的模型,避免犯错。
沿着这个思路,第四范式打造了先知平台,它可以大幅缩减数据工程师在数据处理、模型调参、模型评估以及上线方面的工作量,从而把大量的时间花在如何搜集有意义的数据上。
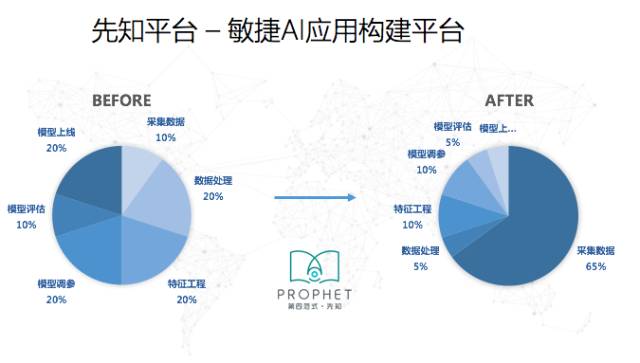
下图是类似于操作系统的先知界面,如果我们有一个TB级的原始数据,例如某银行历史年交易数据,里面可能覆盖了几千万条,甚至上亿条交易数据,其中包含了交易时所对应的人、卡与交易的信息,我们只要通过拖拽的方式做一个图(如下图),就能轻松实现一个完整的机器学习过程。
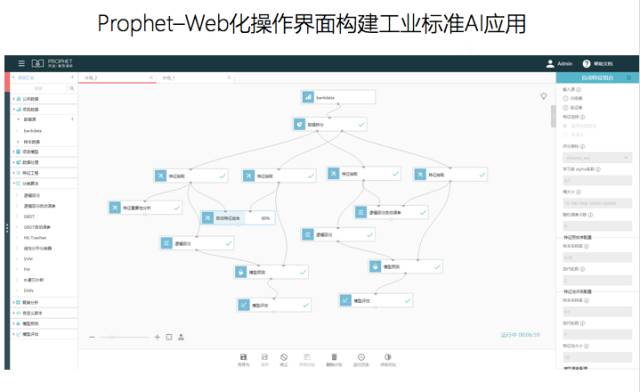
先知会在数据拆分、数据清洗、特征工程等方面做一些简化。更进一步讲何为特征工程,比如如何能够生成一条规则,机器可以把人的职业、性别、年龄、工作地点、消费地点、时间、以及消费金额等特征进行组合,就相当于把几千万条交易分成几百万类或者几十万类,让机器从这几百万类当中判定哪些交易具有欺诈风险。
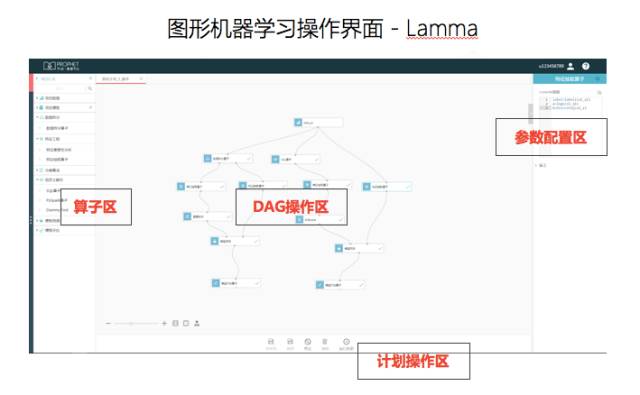

该过程以往要技术人员去写SQL或者Spark脚本的方式产生,如今在先知中,机器可以自动产生脚本、程序,其中有两种特征编码的方式和支持多种高维特征处理方法,像数值处理,日期处理,切词和排序等等。
另外,特征重要性分析防止穿越。比如,我们用过去的交易行为数据来判断该用户是否会在短信营销之后,购买理财产品。
因为用户购买理财产品要预测的事情,我们不会把它当做已有的变量,而用户资产会随着买理财的数额发生变化。
所以,一旦把用户购买的资产作为一个特征的话,就会发现凡是用户在月底资产上升的都喜欢买理财产品,这就是一个典型的穿越特征。并不是因为该用户资产上升,才喜欢买理财产品,而是因为他买了理财产品之后资产才上升。
★推荐阅读★
长期招聘志愿者
加入「AI从业者社群」请备注个人信息
添加小鸡微信 liulailiuwang