苹果M1「徒有其表」?「地表最强」芯只能剪视频引知乎热议

新智元报道
新智元报道
来源:网络
编辑:好困 小咸鱼
【新智元导读】5nm工艺,570亿晶体管,70%CPU性能提升,4倍GPU性能提升。号称史上最强芯片的M1 Max,只能「剪剪视频」?


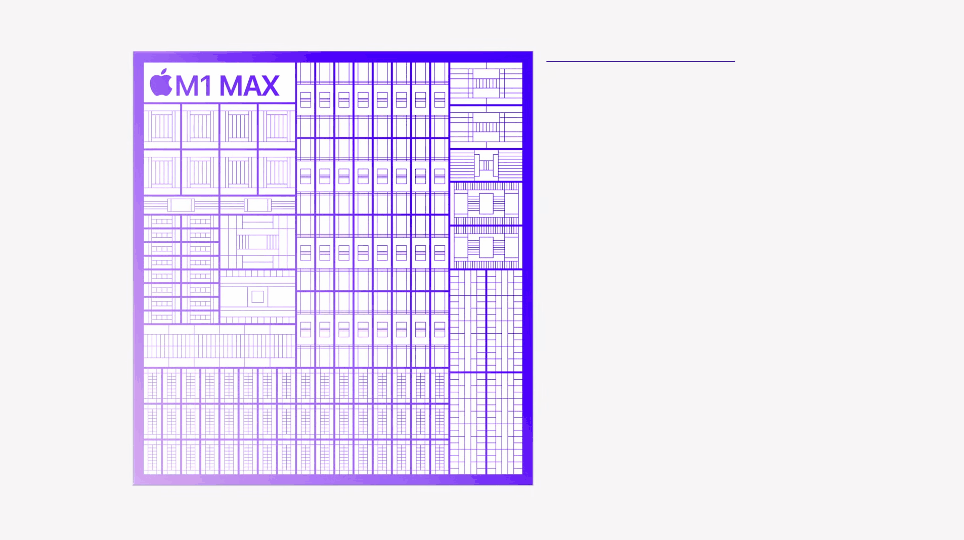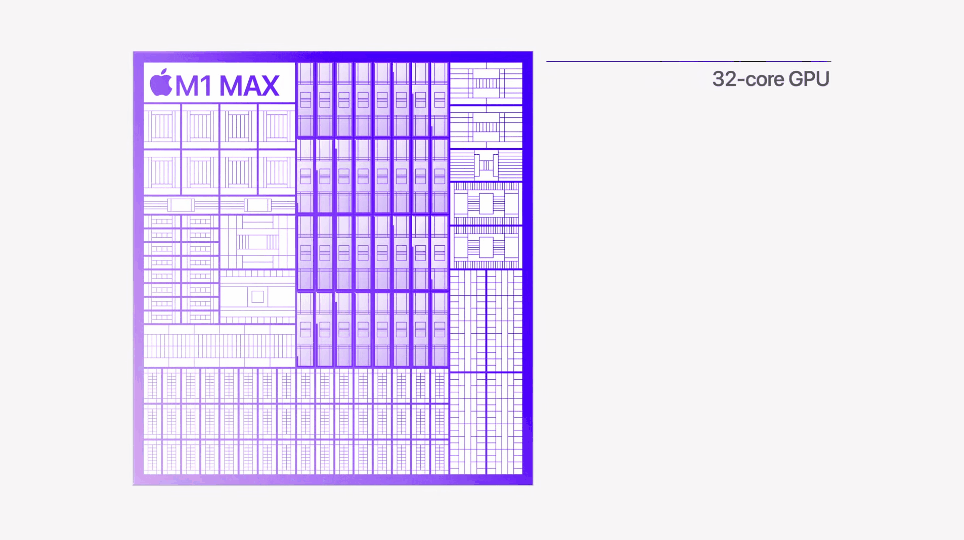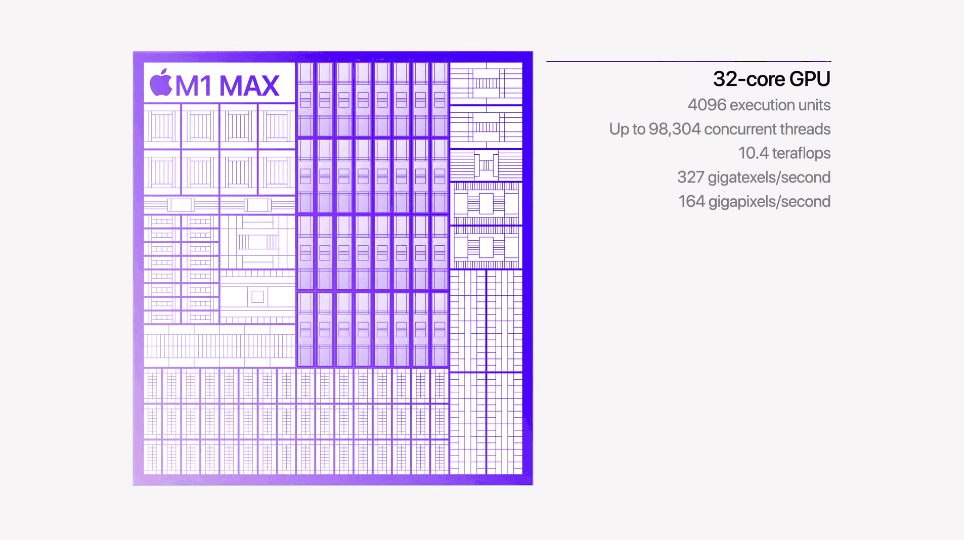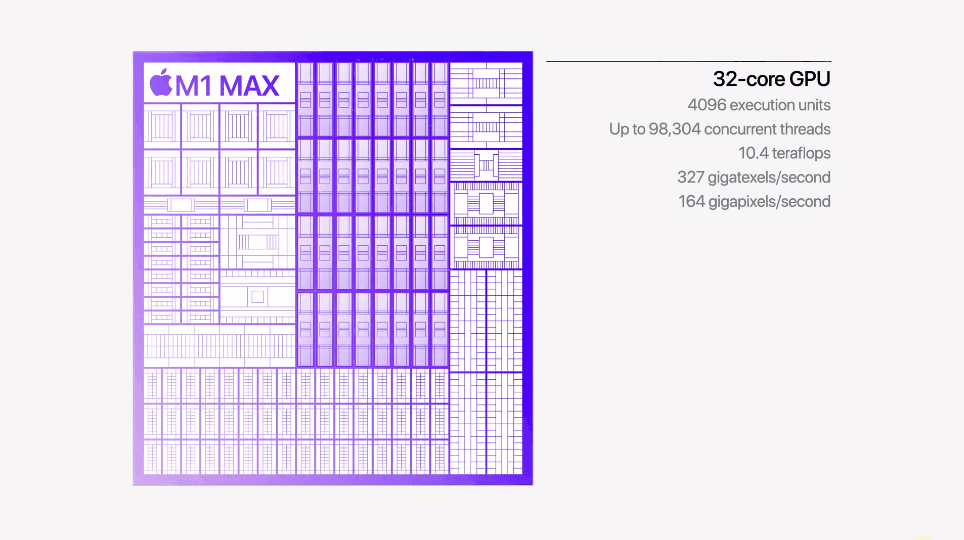
M1 |
M1 Pro |
M1 Pro |
M1 Max |
M1 Max |
|
GPU核心数 |
8 |
14 |
16 |
24 |
32 |
Teraflops |
2.6 |
4.5 |
5.2 |
7.8 |
10.4 |
AMD GPU |
RX 560 (2.6TF) |
RX 5500M (4.6TF) |
RX 5500 (5.2TF) |
RX 5700M (7.9TF) |
RX Vega 56 (10.5TF) |
Nvidia GPU |
GTX 1650 (2.9TF) |
GTX 1650 Super (4.4TF) RTX3050-75W(4.4TF |
GTX 1660 Ti (5.4TF) |
RTX 2070 (7.4TF) |
RTX 2080 (10TF) RTX3060-80W(10.94TF) |
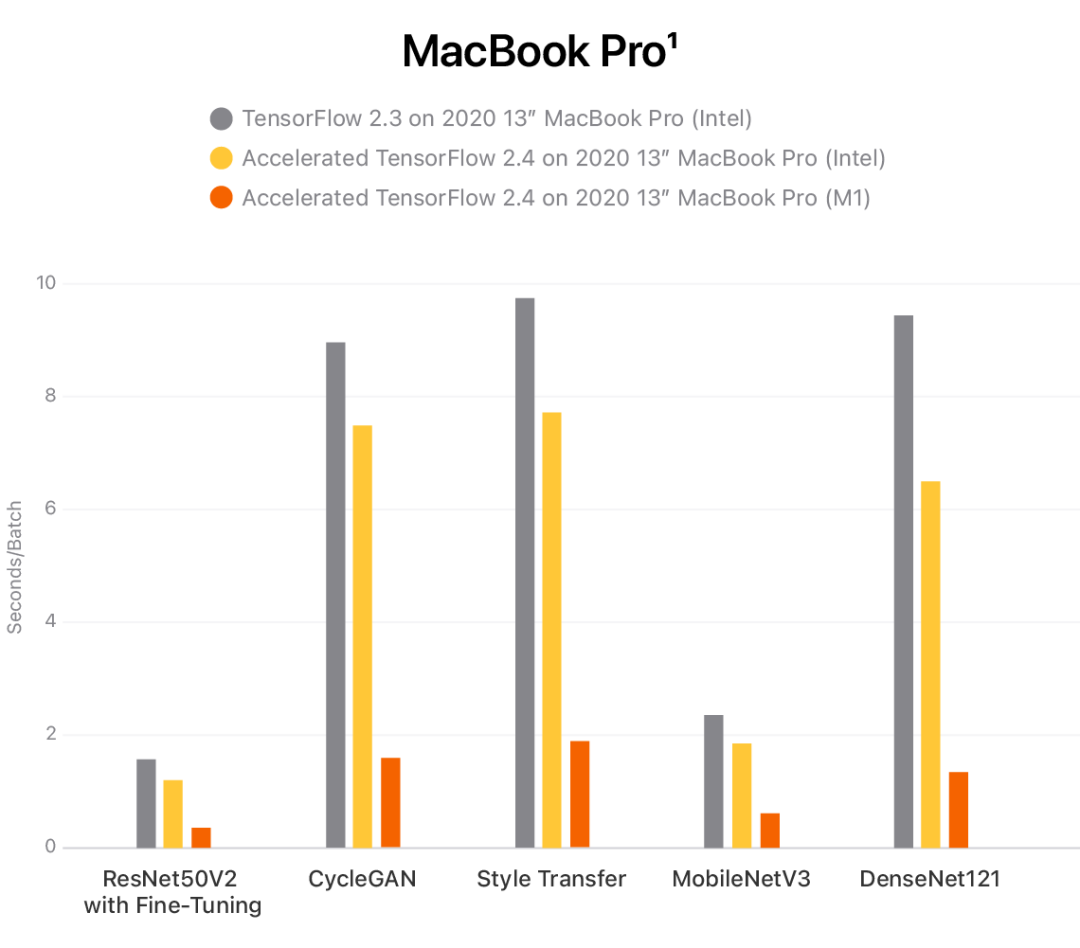
M1 VS 2080Ti
M1 VS 2080Ti

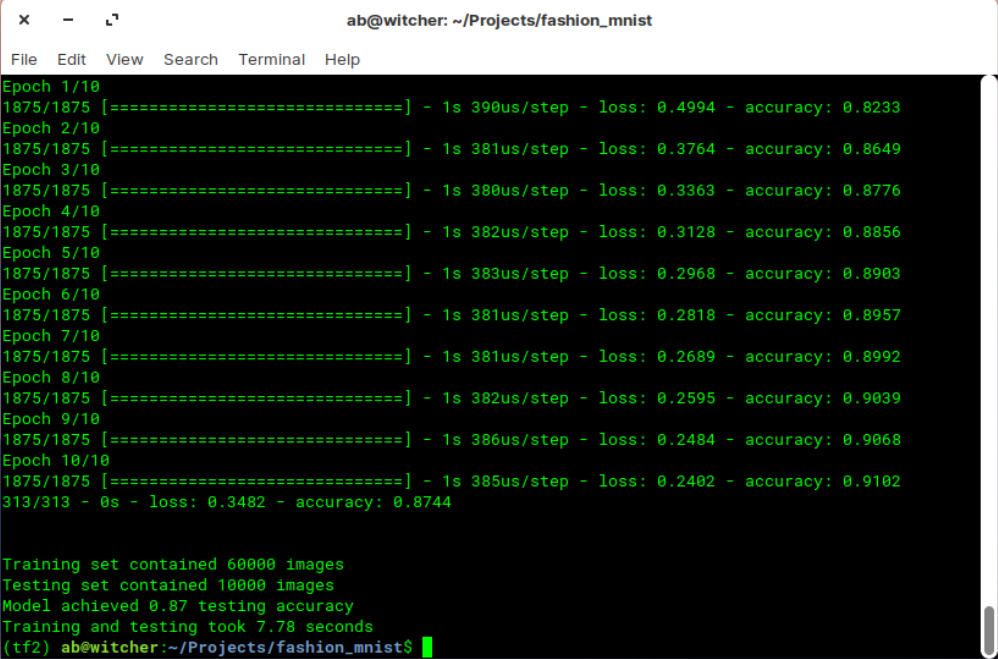
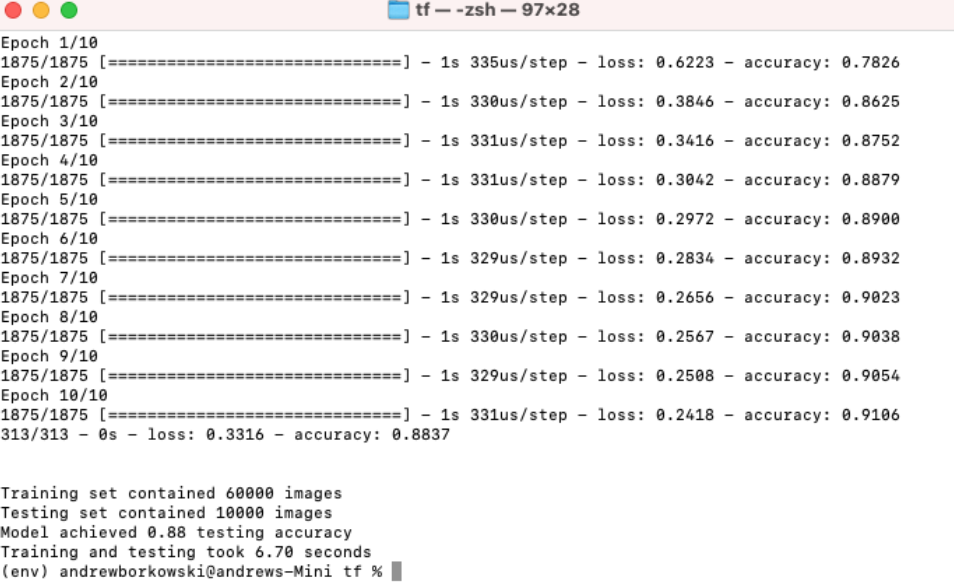
#import librariesimport tensorflow as tfimport time#download fashion mnist datasetfashion_mnist = tf.keras.datasets.fashion_mnist(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()train_set_count = len(train_labels)test_set_count = len(test_labels)#setup start timet0 = time.time()#normalize imagestrain_images = train_images / 255.0test_images = test_images / 255.0#create ML modelmodel = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(10)])#compile ML modelmodel.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])#train ML modelmodel.fit(train_images, train_labels, epochs=10)#evaluate ML model on test settest_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)#setup stop timet1 = time.time()total_time = t1-t0#print resultsprint('\n')print(f'Training set contained {train_set_count} images')print(f'Testing set contained {test_set_count} images')print(f'Model achieved {test_acc:.2f} testing accuracy')print(f'Training and testing took {total_time:.2f} seconds')
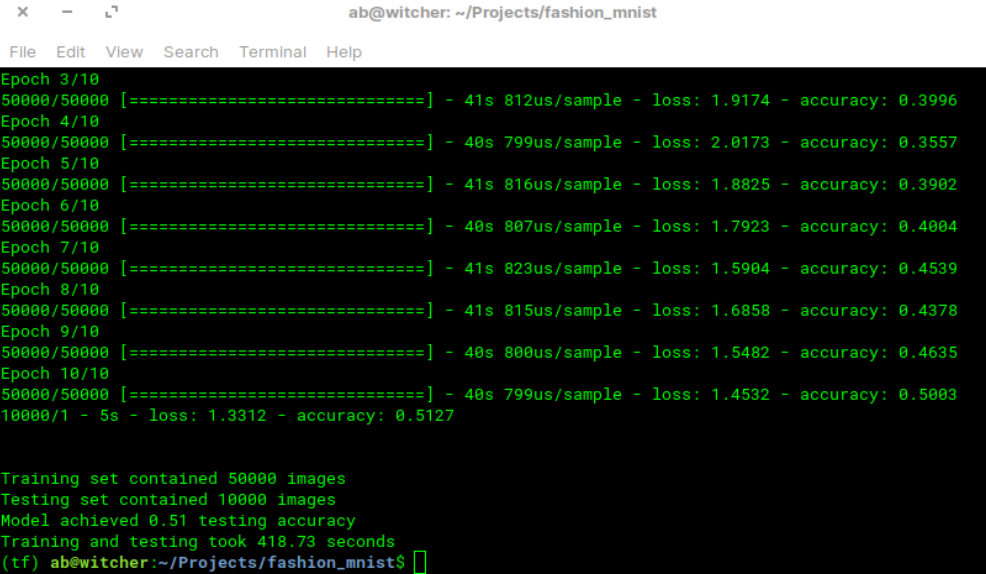
#import librariesimport tensorflow as tffrom time import perf_counter#download cifar10 datasetcifar10 = tf.keras.datasets.cifar10(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()train_set_count = len(train_labels)test_set_count = len(test_labels)#setup start timet1_start = perf_counter()#normalize imagestrain_images = train_images / 255.0test_images = test_images / 255.0#create ML model using tensorflow provided ResNet50 model, note the [32, 32, 3] shape because that's the shape of cifarmodel = tf.keras.applications.ResNet50(include_top=True, weights=None, input_tensor=None,input_shape=(32, 32, 3), pooling=None, classes=10)# CIFAR 10 labels have one integer for each image (between 0 and 10)# We want to perform a cross entropy which requires a one hot encoded version e.g: [0.0, 0.0, 1.0, 0.0, 0.0...]train_labels = tf.one_hot(train_labels.reshape(-1), depth=10, axis=-1)# Do the same thing for the test labelstest_labels = tf.one_hot(test_labels.reshape(-1), depth=10, axis=-1)#compile ML model, use non sparse version here because there is no sparse data.model.compile(optimizer='adam',loss=tf.keras.losses.CategoricalCrossentropy(),metrics=['accuracy'])#train ML modelmodel.fit(train_images, train_labels, epochs=10)#evaluate ML model on test settest_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)#setup stop timet1_stop = perf_counter()total_time = t1_stop-t1_start#print resultsprint('\n')print(f'Training set contained {train_set_count} images')print(f'Testing set contained {test_set_count} images')print(f'Model achieved {test_acc:.2f} testing accuracy')print(f'Training and testing took {total_time:.2f} seconds')
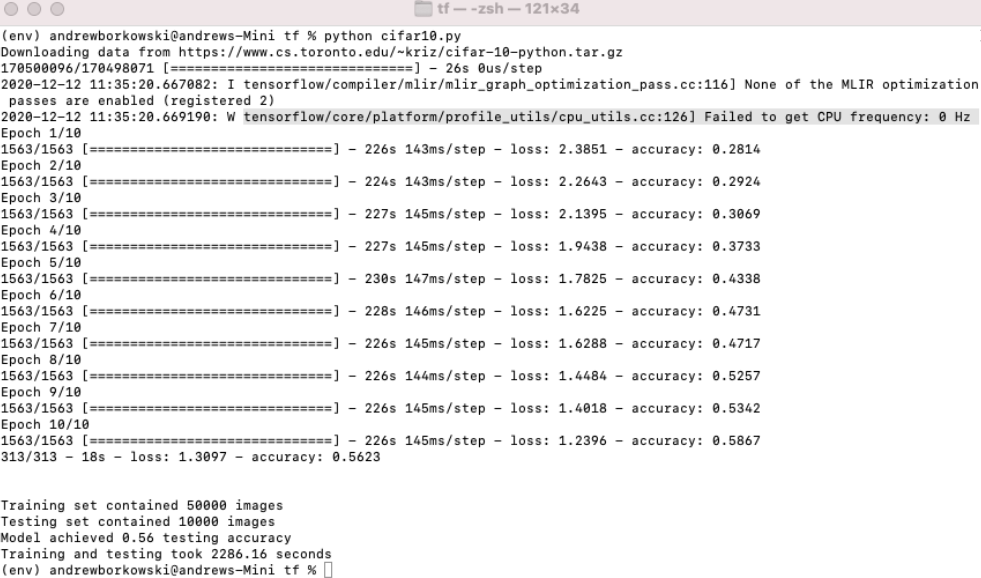
为啥评测只有「剪视频」
为啥评测只有「剪视频」





参考资料:
文中引用了青空,Hate Letter等人的回答,具体参见:
https://www.zhihu.com/question/460373656
https://www.zhihu.com/question/493188474
https://www.zhihu.com/question/493188575
https://appleinsider.com/articles/21/10/19/m1-pro-and-m1-max-gpu-performance-versus-nvidia-and-amd
https://developer.apple.com/metal/tensorflow-plugin/
https://medium.com/analytics-vidhya/m1-mac-mini-scores-higher-than-my-nvidia-rtx-2080ti-in-tensorflow-speed-test-9f3db2b02d74
https://twitter.com/theshawwn/status/1449930512630525956?s=21






