UBC、谷歌联合Hinton等提出3D点云的无监督胶囊网络,多任务上实现SOTA
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转自机器之心
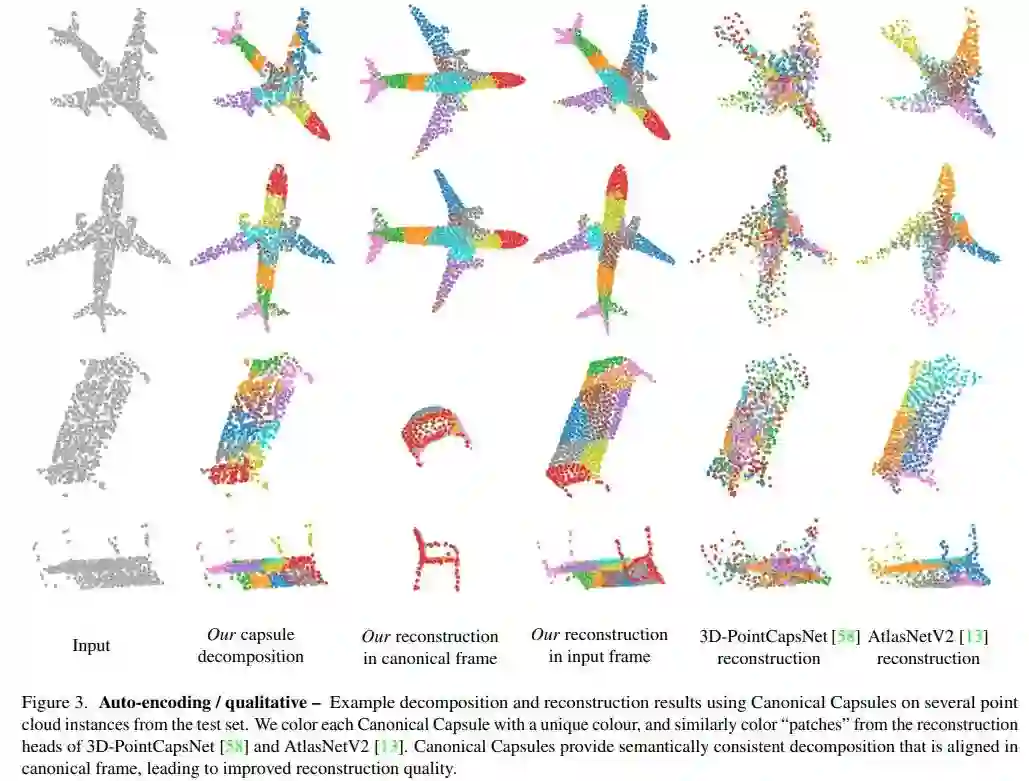
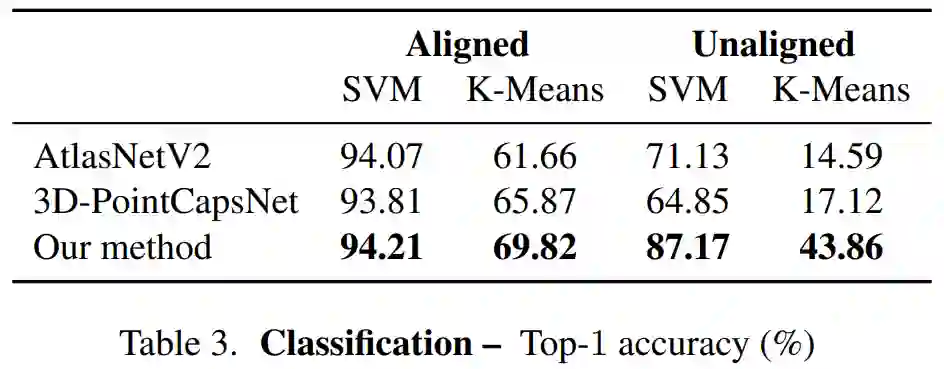
这是一种为 3D 点云提出的无监督胶囊架构,并且在 3D 点云重构、配准和无监督分类方面优于 SOTA 方法。

论文链接:https://arxiv.org/abs/2012.04718
项目主页:https://canonical-capsules.github.io/
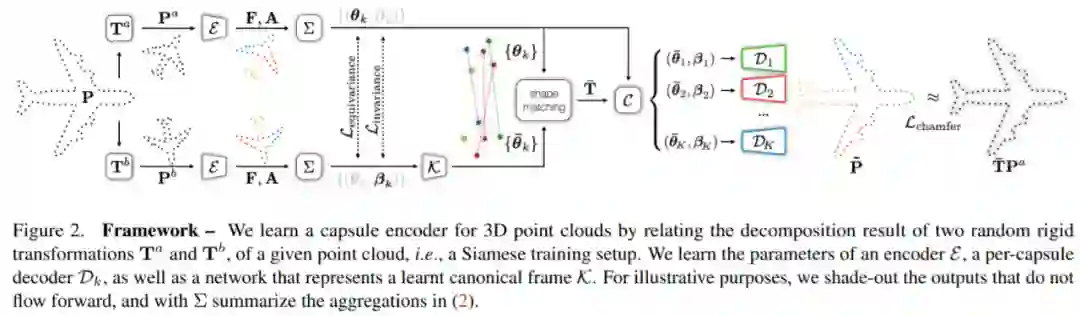
编码器 E。我们的架构是基于 [42] 提出一种类似于点网的架构,具有残差连接和注意力上下文归一化;
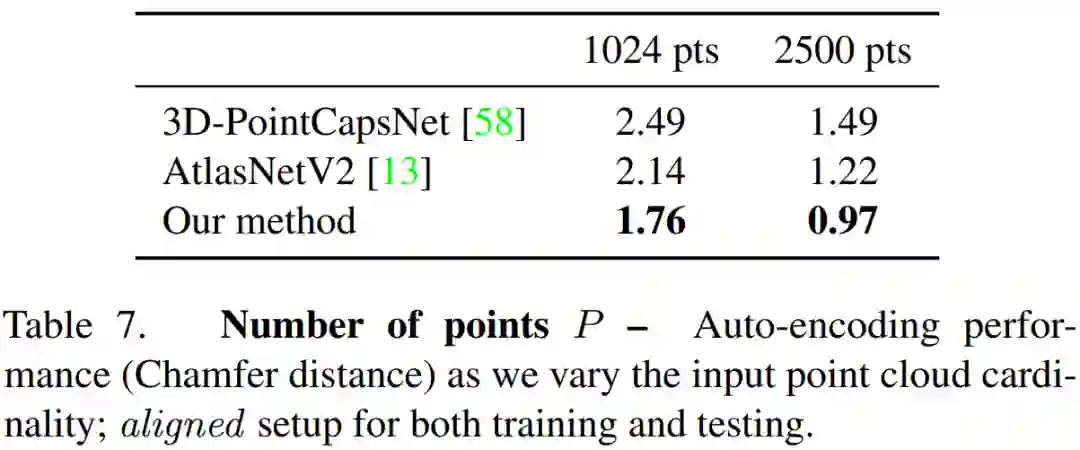
解码器 D。公式 (4) 中的解码器基于每个胶囊运行。本研究采用的解码器架构类似于 AtlasNetV2 [13](带有可训练的网格)。不同之处在于本研究通过相应的胶囊姿态转换每个胶囊的解码点云;

回归器 K。研究者只需连接描述符,并通过 ReLU 激活函数调用一系列全连接层,以回归 P 胶囊定位。在输出层,研究者使用线性激活函数,并进一步减去输出平均值,以使回归位置在规范化框架中以零为中心(zero-centered);
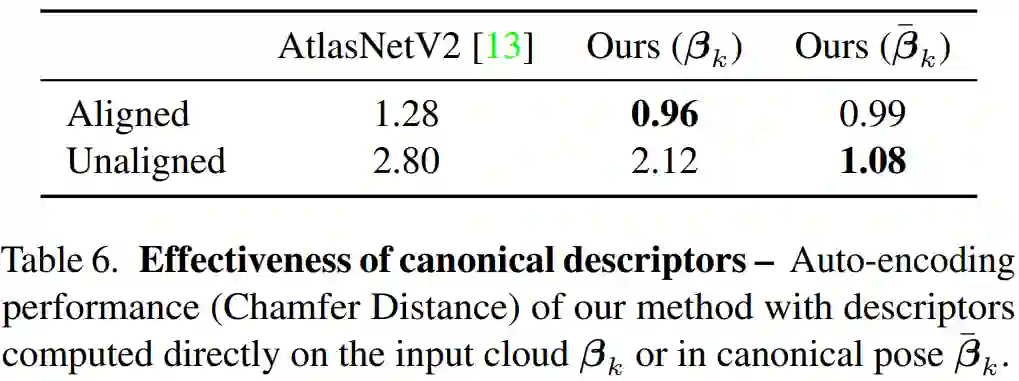
规范化描述符。由于本研究的描述符只是近似旋转不变(通过扩展),研究者发现在规范化之后重新提取胶囊描述符β_k 很有用。
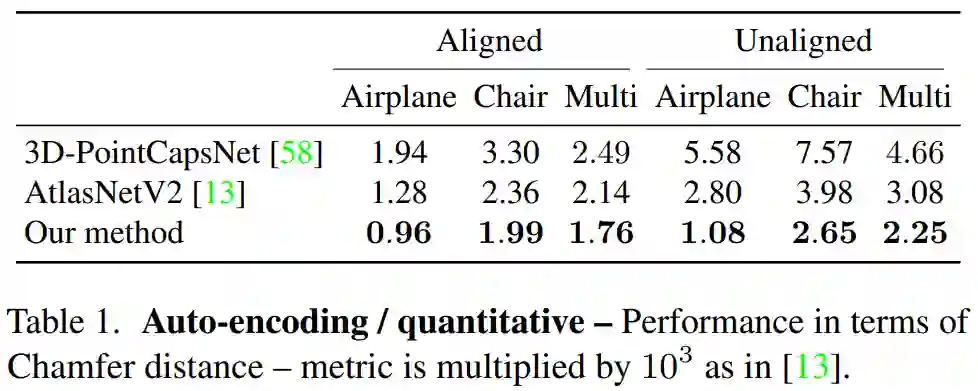
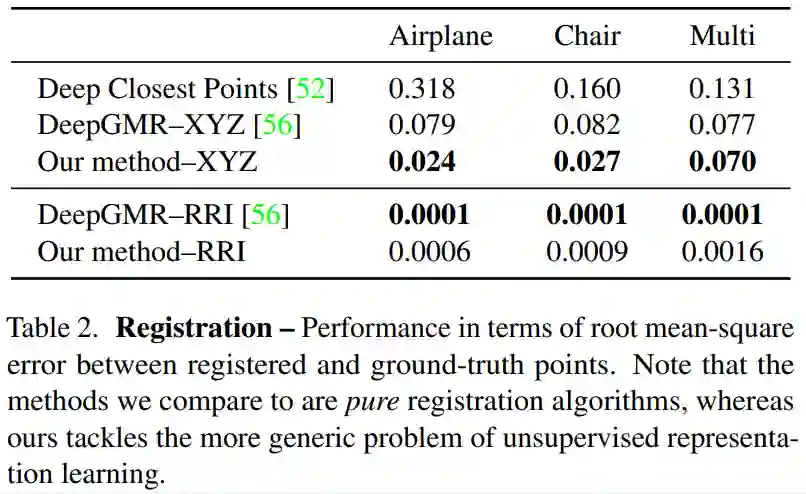
Deep Closest Points (DCP) [52]:一种基于深度学习的点云配准方法;
DeepGMR–RRI [56],一种 SOTA 方法,该方法可以将云分解为具有旋转不变特征的高斯混合;
DeepGMR–XYZ [56],其中将原始 XYZ 坐标用作输入,而不使用旋转不变特征;

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓


