【NeurIPS100】NeurIPS2019 七篇获奖论文揭晓 入选论文深度分析!
NeurIPS 2019于当地时间12月8日在温哥华正式开幕!
今年的NeurIPS可谓盛况空前,参会总人数已经突破了 13000 人。
今天,NeurIPS 2019官方公布了本届杰出论文奖、经典论文奖等重磅奖项,其中微软华人研究员Lin Xiao获得经典论文奖。
为了便于大家了解NeurIPS 2019会议最新消息与录用论文情况,我们也最新上线了会议助手1.0版,从该页面可以查看NeurIPS的会议议程,收录论文与作者详情,以及论文解读与会议报道等信息,欢迎大家使用并拍砖。
扫描以下二维码或者点击阅读原文,进入会议助手!

NeurIPS 2019论文分析
本次大会共收到有效投稿6743篇,最终1428篇论文被接收,接收率达到21.2%(略高于去年的20.8%)。在接收的论文中,还有36篇Oral论文和164篇Spotlight论文。
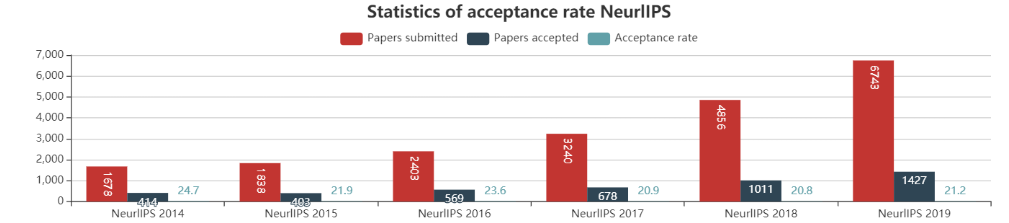
从上图可以看出,随着NeurIPS论文投稿量的逐年上升,论文接收量也逐渐提高,但是录取率近年来却有略微下降的趋势。随着机器学习的热度高涨, NeurIPS论文录用难度也将会逐年增加。
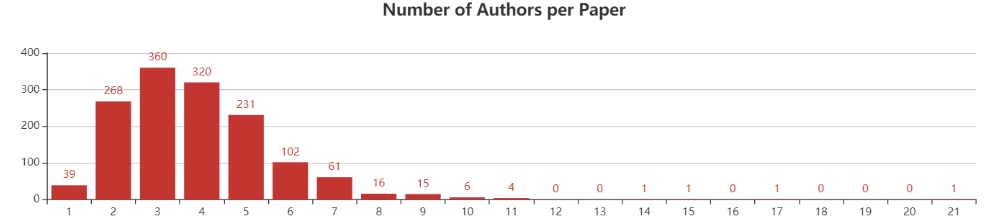
从每篇论文作者数量来看, NeurIPS2019接收的论文大多数都有3-4个作者,其中3个作者的共有360篇,4个作者的共有320篇。拥有10个作者以上的论文共有15篇,其中有1篇文章拥有21个作者。
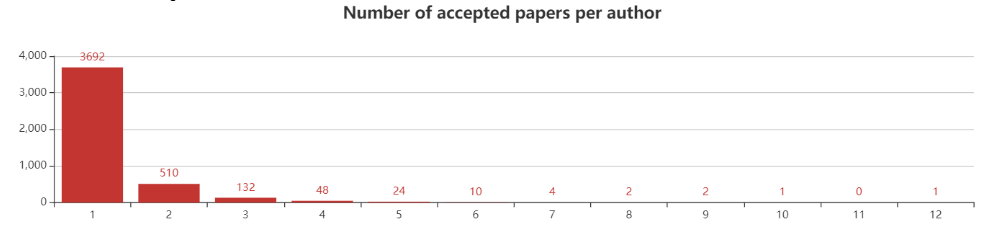
从作者维度分析,NeurIPS2019接收的1427篇共来自4423位作者。其中3692位作者有1篇入选,510位作者有2篇入选,132位作者有3篇入选,48位作者有4篇入选。
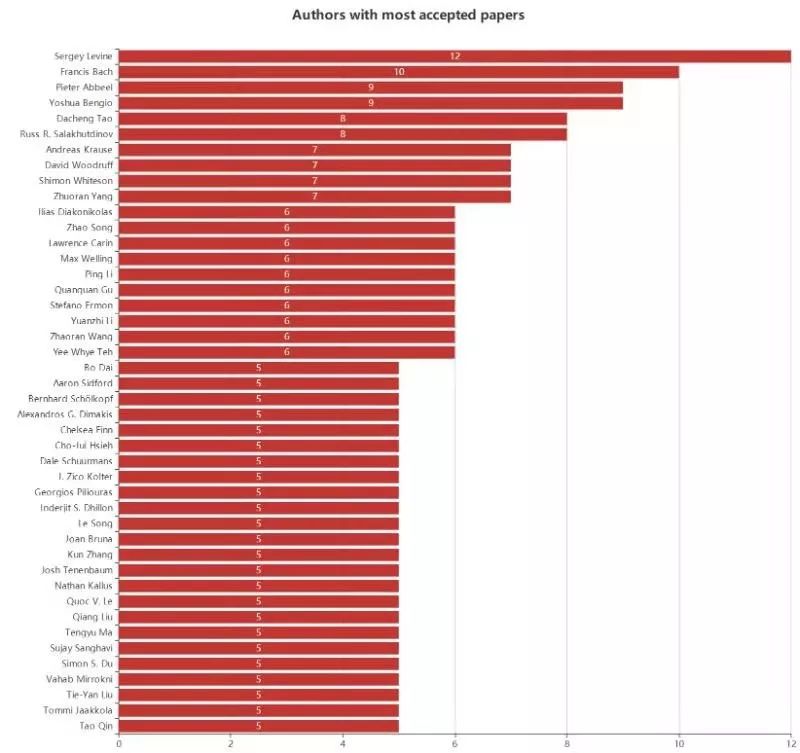
超过5篇入选的作者共有44位。其中,有1位作者有12篇入选,他就是加州大学伯克利分校EECS助理教授Sergey Levine;其次是INRIA的大牛Francis Bach,共有10篇。伯克利大牛Pieter Abbeel和图灵奖得主Yoshua Bengio都有9篇入选。
在华人作者中,论文入选数最多的是陶大程,共有8篇入选。陶大程是澳大利亚科学院院士、悉尼大学教授,同时也担任优必选机器人的首席科学家。
来自普林斯顿大学运筹学与金融工程系的博士研究生杨卓然与美国西北大学助理教授Zhaoran Wang分别有7篇和6篇论文入选。
Zhuoran Yang(杨卓然)是普林斯顿大学运筹学与金融工程系的博士研究生。于2015年获得清华大学数学系学士学位,研究方向是统计机器学习和增强学习。
从一作统计,共有59位作者有2篇以上(包括2篇)论文入选,其中,以一作身份发表3篇以上论文作者的共有8位,还有1位作者发表了4篇,他就是“计算机金牌王子”--朱泽园,在NeurIPS2018与 ICML 2017 上,朱泽园分别也有4篇、5篇以一作论文被接收。
朱泽园目前就职于微软总部研究院,主要致力于机器学习和优化问题的数学基础的相关研究,并将它们应用于深度学习、理论计算机科学、运筹学和统计学。
从作者所属国家来看,华人参与的论文共有656篇,占总论文数的46%。其中华人一作论文共有471篇,占华人参与论文数的71.8%,占总论文数的33%。
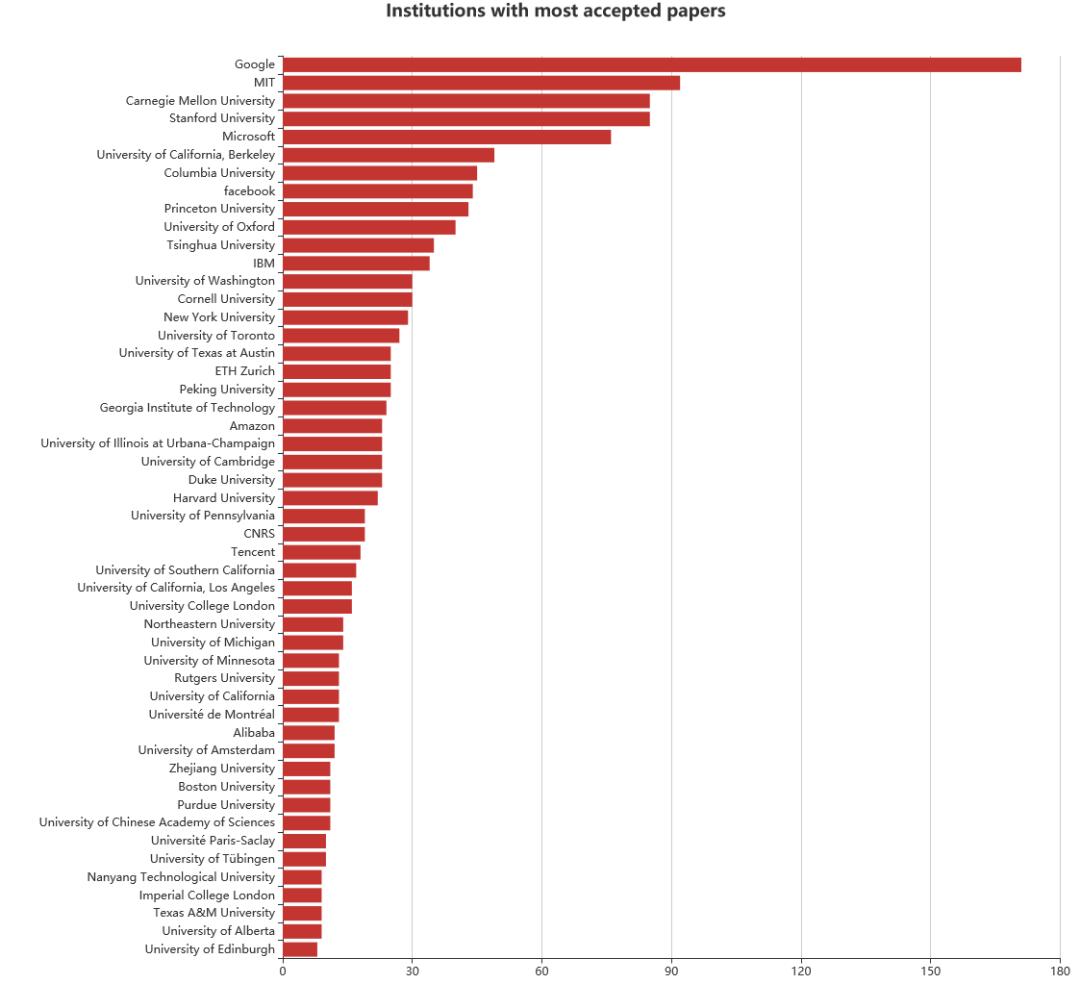
从论文所属机构来看,Google+DeepMind组合高居榜首,入选论文共计171篇。MIT排名第二,92篇论文入选。斯坦福大学、卡内基梅隆大学排名第三,都有85篇入选。
国内高校中,清华大学入选论文最多,共计35篇,排在总榜的第13位;北京大学有25篇入选,排在总榜第19位。
杰出论文等奖项公布
今天,NeurIPS 2019官方公布了本届杰出论文奖、经典论文奖等重磅奖项,其中微软华人研究员Lin Xiao获得经典论文奖。

今年组委会还特别增设的杰出新方向论文奖,主要表彰在“面向未来研究的创新途径”方面表现优秀的研究者。
在会议上评选出最优秀的论文历来是NeurIPS的传统。这些杰出论文是如何评选出来的呢?
NeurIPS2019 杰出论文委员会的五位成员会从做oral presentation的论文中进行选择,根据论文的长期潜力、洞察力、创造性、革命性、科学性、可重复性等原则作为评选标准进行初步分类,选出三篇论文的短名单和一个八篇备选论文的长名单,然后各自再对对这八篇论文进行评估并为每篇论文定级,同时也会寻求更多的专家意见作为参考,最终确定获奖名单。
杰出论文奖
Distribution-Independent PAC Learning of Halfspaces with Massart Noise
作者:Ilias Diakonikolas、Themis Gouleakis、Christos Tzamos(威斯康辛大学麦迪逊分校、马普所)
论文地址:https://www.aminer.cn/pub/5d1eb9d3da562961f0b0dc62/distribution-independent-pac-learning-of-halfspaces-with-massart-noise
摘要:这篇论文研究了在训练数据中有未知的、有界的标签噪声的情况下,如何为二分类问题学习线性阈值函数。论文推导出一个在这种情境下非常高效的学习算法,解决了一个基础的、长期存在的开放性问题:在有Massart噪声的情况下高效地学习半空间;这也是机器学习的核心问题之一,这篇论文带来了巨大的进步。
论文中的一个简单的例子证明了该方法的效果。在此之前,只有1% Massart噪声就会让弱学习无效(达到49%的错误率)。论文中展示了如何高效地让错误水平上限仅仅等于Massart噪声水平+ε (算法的运行时间为(1/ε)的多项式,正如预期)。算法的实现方法很精密,达到这样的结果也有一定的技术挑战。最终的结果是,能够高效地在(1/ε)的多项式运行时间内让错误水平上限为Massart噪声水平+ε 。
杰出新方向论文奖
Uniform convergence may be unable to explain generalization in deep learning
作者:Vaishnavh Nagarajan、J. Zico Kolter(卡耐基梅隆大学、博世人工智能中心)
论文地址:https://www.aminer.cn/pub/5cede0ecda562983788cad9e/uniform-convergence-may-be-unable-to-explain-generalization-in-deep-learning
为了解释过参数化深度网络令人惊讶的良好泛化性能,近期的论文为深度学习开发出了各种泛化边界,这些边界都是基于一致收敛理论上的基本学习技巧。许多现有的边界在数值上都很大,通过大量的实验,作者揭示了这些界限的一个更值得关注的方面:实际上,这些边界可以随着训练数据集的增大而增大。
根据观察结果,他们随后给出了一些用梯度下降(gradient descent, GD)训练的过参数化线性分类器和神经网络的例子,而在这些例子中,一致收敛被证明不能「解释泛化」--即使尽可能充分地考虑了梯度下降的隐含偏见。更加确切地说,即使只考虑梯度下降输出的分类器集,这些分类器的测试误差小于设置中的一些小的ε。研究者也表明,对这组分类器应用(双边,two-sided)一致收敛将只产生一个空洞的大于 1-ε的泛化保证。通过这些发现,研究者对基于一致收敛的泛化边界的能力提出了质疑,从而全面了解为什么过参数化深度网络泛化得很好。
杰出论文奖荣誉提名
Nonparametric density estimation & convergence of GANs under Besov IPM losses
作者:Ananya Uppal、Shashank Singh、Barnabás Póczos(卡内基梅隆大学)
论文地址:https://www.aminer.cn/archive/nonparametric-density-estimation-convergence-rates-for-gans-under-besov-ipm-losses/5db9297547c8f766461f721d
在本文中,作者探究了大型损失函数族(Besov IPM)的非参概率密度估计问题,该函数族包括 L^p 距离、总变分距离,以及 Wasserstein 距离和 KolmogorovSmirnov 距离的泛华版本。对于各种损失函数设置,研究者提供了上下界,精确明确了损失函数与数据假设的选择,如何影响极小极大最优收敛率的确定。
作者同样展示了线性分布估计经常不能达到最优收敛率,例如经验分布或核密度估计器等线性分布。他们得出来的上下界能帮助泛化、统一或提升一些最经典研究成果。此外,IPM 可以用于形式化生成对抗网络的统计模型。因此,研究者展示了该结果如何表明 GAN 的统计误差边界,例如 GAN 要严格超越最好的线性估计器。
Fast and Accurate Least-Mean-Squares Solvers
作者:Alaa Maalouf、Ibrahim Jubran、Dan Feldman(以色列海法大学)
论文地址:https://www.aminer.cn/pub/5db9294547c8f766461f2185/fast-and-accurate-least-mean-squares-solvers
本文从线性、Lasso回归到奇异值分解和Elastic net,最小均方算法是许多ML算法的核心。本文展示了如何在不损失精度的情况下,将其计算复杂度降低一到两个数量级,并改进了数值稳定性。该方法依赖于Caratheodory定理,建立一个coreset (d维中d2 + 1个点的集合)足以表征凸集中的所有n个点。它的新颖之处在于提出了一种分治算法,在复杂度可承受的情况下(O(nd + d5 log n),其中d << n))提取coreset。
杰出新方向论文奖荣誉提名
Putting An End to End-to-End:Gradient-Isolated Learning of Representations
作者:Sindy Lwe、Peter O‘Connor、Bastiaan Veeling(阿姆斯特丹大学)
论文地址:https://www.aminer.cn/pub/5de799ee9e795e775806935a/putting-an-end-to-end-to-end-gradient-isolated-learning-of-representations
本文重新审视了深度网络的分层构建,使用了van Oord等人提出的自监督标准,特别是当前输入的表示与空间或时间相近的输入之间的相互信息。
Scene Representation Networks:Continuous 3D-Structure-Aware Neural Scene Representations
作者:Vincent Sitzmann 、Michael Zollhfer、Gordon Wetzstein(斯坦福大学)
论文地址:https://www.aminer.cn/archive/scene-representation-networks-continuous-3d-structure-aware-neural-scene-representations/5d04e90fda56295d08de0a15
本文提出了CV中的两种主要方法:多视图几何方法和深度表示方法完美地结合在一起。具体而言,本文的三大贡献表现在:1.基于每个体素的神经渲染器,实现了场景的3D感知无分辨率渲染;2.提出一种可微分的ray-marching 算法,解决了沿着摄像机投射光线寻找曲面交点的难题;3.提出一种潜在的场景表示方法,利用自动编码器和超级网络对场景来回归表示网络的参数。
经典论文奖
NeurIPS经典论文奖的授予原则为"重要贡献、持久影响和广泛吸引力",本届大会从 2009 年 NIPS 的 18 篇引用最多的论文中选出了持续影响力最高、对研究领域具有杰出贡献的研究。
最终,今年的这一奖项授予 了NIPS 2009 论文《Dual Averaging Method for Regularized Stochastic Learning and Online Optimization》及其作者,微软首席研究员 Lin Xiao。
Lin Xiao曾就读于北京航空航天大学和斯坦福大学,自 2006 年起就职于微软研究院。他的研究兴趣包括大规模优化的理论和算法,机器学习的随机和在线算法,并行计算和分布式计算。
Dual Averaging Method for Regularized Stochastic Learning and Online Optimization
论文地址:https://www.aminer.cn/pub/53e99858b7602d9702091d2a/dual-averaging-methods-for-regularized-stochastic-learning-and-online-optimization
该研究提出了用于在线最优化求解的RDA(Regularized Dual Averaging)方法,是Lin Xiao在微软10年的研究成果。该方法是Simple Dual Averaging Scheme一个扩展,并更有效地提升了特征权重的稀疏性。
点击下方“阅读原文”进入会议助手!
↓↓↓




