可视化不确定网络的概率图布局方法

文 | Lijing Lin
不确定网络,在本文表示顶点是确定的(certain),边的存在与否满足某种概率分布的网络。在图1中,左图是确定网络(certain graph),右图是不确定网络(uncertain graph)。
在不确定网络可视分析中,现有的方法往往直接在确定图(exact graph)中用视觉变量(visual variables)表示不确定信息。这些方法可以很好的将图的拓扑结构展示出来,但忽略了不确定信息的概率分布情况。
在这篇文章,作者们提出一个概率图(probabilistic graph)布局方法。这个方法可以同时展示图的拓扑结构和不确定信息的概率分布。它的基本思想是,依据蒙特卡洛方法(Monte Carlo process)对不确定图进行采样;将采样获得图根据力导向算法进行布局;之后,将所有采样图的力导向布局组合起来,获得最后概率图的布局(如图2所示)。
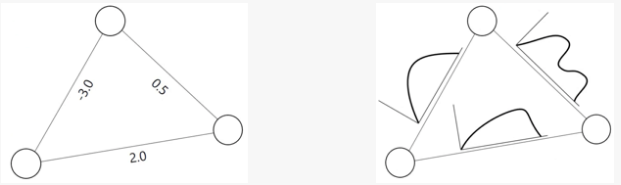
图1 左图是确定图;右图是不确定图
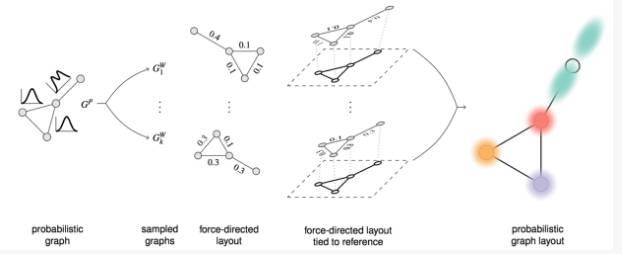
图2 文章提出的概率图布局方法流程图
文章分析的数据可以用G = (V, E, F)表示,其中V表示顶点集合。顶点是确定的元素;E表示边集合。边的存在与否满足F表示的概率密度函数。
在采样阶段,采用随机采样方法。
在力导向布局阶段,他们采用图3公式优化图布局。其中dij表示顶点i和顶点j之间的理想距离;wij表示边被选取的概率。
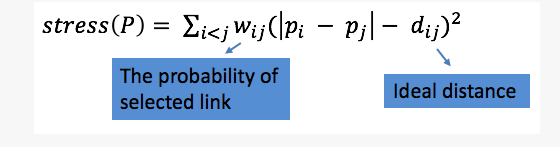
图3 力导向算法优化函数
在组合阶段,目标是将所有采样图的力导向布局整合成一个布局。文章提出的方法是构建一个参考布局(reference layout),然后将所有的采样图根据图4公式,重新布局。

图4 根据参考布局,重新布局的优化函数
在文中,参考布局一般是期望图(expected graph)。在期望图中,边的权重是该边概率分布的期望值。
在可视化阶段,为了更好的将每个顶点的位置分布情况和整体的图结构展示出来,他们对最后计算得到的整合布局进行了一系列的处理。
首先,他们对图中的顶点进行了滚雪球(splatting)处理。这样处理的目的是为了更好的将相同顶点的可能位置展示出来。在实际处理中,他们采用核密度估计函数计算每个顶点位置的概率密度分布函数,然后用ray-casting的方法,将顶点的位置分布展现出来(图5)。在核密度估计函数中,带宽h的值对结果的影响很大。图6展示了在不同h的情况,获取的结果。从左至右,布局从欠平滑状态过渡到过平滑状态。文章作者认为欠平滑的布局更利于用户进一步的分析,因为欠平滑的布局可以清晰展现顶点和边的关系。
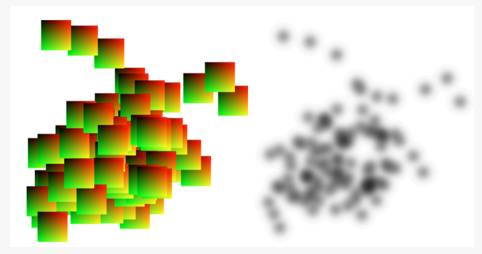
图5 左图每个方块表示每个顶点位置的概率密度分布;右图是在左图基础上进行ray-casting后得到的布局

图6 从左至右,布局从欠平滑状态过渡到过平滑状态
接着,他们对最后计算得到的整合图中的边进行了处理。为了更好的描述边的分布和图的拓扑结构,他们对图中的边进行了层次聚类;接着采用贝赛尔曲线表示这些边,并采用滚雪球的方法对边进行可视化(图7)。

图7 左图,直接用直线展示边的布局;右图,对边进行一系列处理后的布局
最后,他们采用Welsh-Powell方法对图中的顶点进行着色。因为同个顶点的位置分布可能因为一些异常值,导致在空间上不能聚集在一起。为了帮助用户快速的识别同个顶点的位置分布,他们对图中的顶点进行了聚类处理。针对每个聚类,他们计算了群簇的边缘,并将表示同个顶点的群簇通过图8的方法,连接起来。
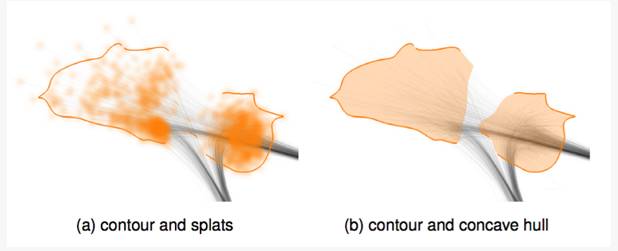
图8 对顶点进行聚类,添加边缘的结果
根据轮廓之间的空缺方向,用户可以将属于同个顶点的群簇链接起来。
接下来,我将介绍两个实例,验证这个方法的可用性。
第一个例子使用的是人造数据。在这个数据中,有五个顶点,8条边。每条边的概率分布如图9(c)第一行所示。图9(a)表示的是这个人造数据的期望图。我们可以发现,这个布局可以清晰的展示图的拓扑结构,但不能将边的不确定信息展示出来;图9(b)表示的是通过文章的方法计算得到的布局。
它清晰的展现了图的拓扑结构和顶点的位置分布;图9(c)表示的是边的统计信息。每一列表示一条边,第一行表示边存在与否的概率分布,第二行表示采样获得的边的概率分布,第三行表示边的欧拉距离分布。我们可以发现,同一列的三个分布都非常的相似。这说明,足够的采样是可以逼近真实概率分布的;也说明他们的方法可以很好的将图拓扑结构展现出来。
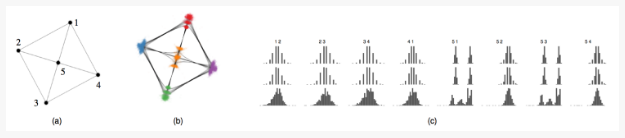
图9 (a)期望图;(b)根据文章的方法得到的布局;(c)边的统计信息分布图
在第二个例子中,他们尝试用这个方法分析城市之间的行程时间。该例子分析了8个城市之间的行程时间。在构图上,他们将每个城市看作顶点,在可到达的城市之间建立边。边的权重表示行程时间。为获取城市之间的行程时间,他们通过Google Direction API随机获取不同时间段,任意两个连接的城市之间的行程时间,并通过直方图处理,获取城市之间行程时间的概率分布图(如图10(a)所示)。
接着,他们根据不同的参考布局,得到了不同的概率图布局。图10(b)和(c)展示的布局,在其参考布局中,顶点的位置是不确定的,但顶点之间的理想距离是相应城市之间的真实距离。图10(d)和(e)展示的布局,在其参考布局中,顶点的位置就是相应城市的地理位置。我们可以发现,这两类参考布局得到的最后布局非常的相似,它们似乎只是旋转了不同的角度。
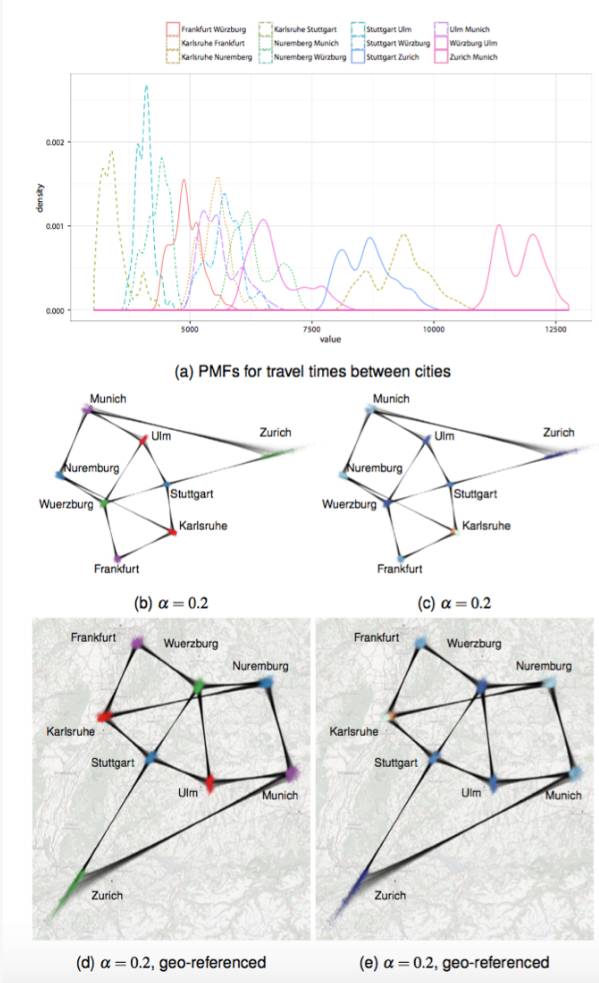
图10 (a)城市之间行程时间的概率分布图;(b)(c)和(d)(e)是两种参考布局得到的概率图布局
总的来说,这篇文章提出了一个新颖的不确定网络的可视化方法。他们的方法可以清晰的展现图的拓扑结构和图中不确定信息的概率分布。
End
视频:大数据到底是什么 都说干大数据挣钱 1分钟告诉你都在干什么
双11剁手幕后的阿里“黑科技” OceanBase/金融云架构/ODPS/dataV

36大数据
长按识别二维码,关注36大数据
搜索「36大数据」或输入36dsj.com查看更多内容。
投稿/商务/合作:dashuju36@qq.com
↓↓↓



