EMNLP 2020 | BERT-of-Theseus:基于模块替换的模型压缩方法

背景
标题:
BERT-of-Theseus: Compressing BERT by Progressive Module Replacing
作者:
Canwen Xu, Wangchunshu Zhou, Tao Ge, Furu Wei, Ming Zhou
机构:
武汉大学、北京航空航天大学、微软亚洲研究院
论文地址:
https://arxiv.org/abs/2002.02925
论文代码:
https://github.com/JetRunner/BERT-of-Theseus

摘要
Q: 文章想要解决什么问题?
A:看不惯BERT系列模型五大三粗、土肥圆的样子,想要对ta们强(模)行(型)瘦(压)身(缩)!

Q:文章提出了什么方案?
A:文章开出的治疗方案名为:Theseus,该方法通过逐步更换BERT的各个模块实现模型压缩。该方法先将原始的BERT分为数个模块,并为其创建对应的压缩模块(即替代模块),再随机地用压缩模块替换掉原始的模块,并训练这些压缩模块使其能够效仿原始的模块。整个过程中循序渐进,逐步增加替换的概率,从而实现整体模块(即整个模型)替换。
举个栗子,有7个菜逼想要学习武当七侠的真武七截阵,先派一个菜逼,替换掉武当七侠中的一位,比如莫声谷,然后让这6神+1菜的组合不断的练习。经过一段时间,在6位大神的指(毒)导(打)下,新加入的菜逼实力会提升,这个6神+1菜的组合拥有接近武当七侠真武七截阵的真正实力。再陆续派出其他菜逼,重复上述过程,直到所有菜逼都接受了都被充(社)分(会)训(毒)练(打),那么最终7个菜逼也能施展真武七截阵。所以,名师出高徒,组团抢大龙。
Q:该方案疗效如何?
A:基于Theseus的方法在GLUE上优于知识蒸馏,且相比于BERT的知识蒸馏方案,基于theseus的压缩方法只需要一个损失函数和一个超参数,简洁得不要不要的,泥们其他在座的,都太繁琐。

模型
Theseus之船
既然文章模型名为 BERT-of-Theseus ,那先说说Theseus(忒修斯)之船的典故。忒修斯(Theseus)是传说中的雅典国王。克里特岛国王米诺斯在战争中打败过雅典。他要求雅典人每九年(亦传每年)奉祭七名少年七名少女给怪物米诺陶洛斯(米诺斯的儿子,半人半牛,被囚禁于米诺斯迷宫)。轮到第三次奉祭时,忒修斯自告奋勇要去杀死那个怪物。他和父亲埃勾斯(海神波塞冬的儿子)约定,当他的船回航时若成功则挂白帆。在克里特,米诺斯的女儿阿里阿德涅爱上了忒修斯,她给了他一个线团,以便他在迷宫中标记退路。忒修斯杀死了米诺陶并带领其他雅典人逃离了迷宫,他还带走了阿里阿德涅,但在回航路上将她丢在在纳克索斯岛,所幸酒神狄俄倪索斯怜悯她,娶她为妻.阿里阿德涅诅咒了忒修斯,他忘记挂上白帆,埃勾斯以为忒修斯失败身亡,悲痛之下堕下海岸而死,从此这片海域就被称为爱琴海。人们为了纪念他的英雄壮举,忒修斯回航所乘的船据说在雅典保留了很多年,随着时光流逝,那艘船逐渐破旧,木头朽毁后不断修补替换,人们依次更换了船上的甲板,以至最后更换了它的每一个构件。这时人们禁不住发出疑问:更换了全部构件的忒修斯之船还是原来那艘船吗?后来人们常把部分替换后主体是否仍然保留的哲学命题称为忒修斯之船后来,常把其所有部分被替换后原主体是否仍然存留的哲学问题称为“忒修斯之船”,其挑战性在于:如何理解和刻画跨越时间或空间的个体的同一性?

文归正传,继续介绍BERT-of-Theseus的其他细节。
模块替换
模型压缩致力于在降低模型尺度和计算量的同时最大程度地保持原有精度。常见的模型压缩方法有剪枝、量化和知识蒸馏。剪枝是用二分类器剪除模型中多余的权重,从而使其变为参数较少的小模型;量化不改变模型结构,但将模型换一种数值格式,比如通常训练模型用的是 float32 类型,而如果换成半精度float16 就不仅能提速还能节约显存,有时会进一步转换成 8 位整数甚至 2 位整数(二值化);知识蒸馏则是训练student模型来模仿teacher模型,除了学习输出之外,有的还是设计模型的中间层结果、Attention 矩阵等部分的学习,这就涉及到多项损失函数的设计。
BERT-of-Theseus模型压缩的核心思想:循序渐进地用更少参数的模块替换BERT中的各个原始模块。原始模块和用以替换的压缩模块分别称为 predecessor(前辈) 和 successor(传人),successor要学习效仿predecessor,这类似于知识蒸馏中的teacher和student。但与知识蒸馏所不同的是,知识蒸馏一方面需要确切地定义teacher和student之间的相似损失函数,且最终性能严重依赖于所设计的损失函数。此外,该损失函数还需要联合特定任务的损失。Theseus压缩只面向下游任务阶段,而不涉及预训练阶段,所以只需要特定下游任务的损失函数。换句话说,Theseus压缩是面向微调阶段的模型压缩方案。受Dropout启发,文章中提出一种模块替换策略:
(1)将原始模型划分 predecessor,并为每个predecessor模块指定一个successor模块。比如,对于BERT压缩,为每2层 Transformer 作为一个 predecessor,为其指定1层的Transformer作为 successor。如此,则12层的BERT划分出6个predecessor模块,压缩后的BERT则由6个successor模块组成。
(2)第 i+1 个模块,通过一个伯努利分布,采样一个随机变量 ,则该变量值为1的概率为 ,值为0的概率为 。
(3)第 i+1 个模块的输出:
通过这种方式,predecessor 模块和 successor 模块在训练过程协同工作。由于上述混合模型中引入了一个伯努利分布,所以在模型中引入了额外的噪声可以作为训练 successor 中的正则化操作(类似Dropout)。
(4)这个训练过程跟微调阶段很类似,都是面向下游特定任务。另外,这里需要关注一个训练细节:在梯度反向传播的时候, predecessor 的权重参数都freeze不参与梯度计算,只有 successor 模块的权重参数会参与梯度更新。BERT-of-Theseus的具体架构如Figure 1所示:
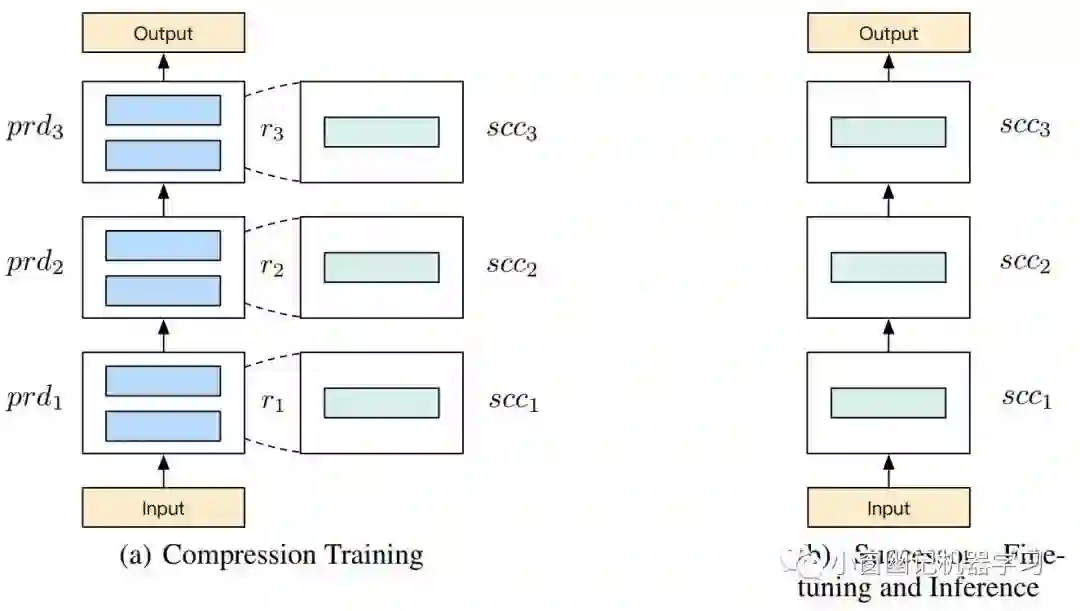
successor 的微调和推理
在上述训练阶段后,将所有 successor 进行联合训练,即所谓的替换后的微调阶段。这是因为上述的模块替换训练阶段,各个 successor 模块都是孤立地训练,所以需要将所有 successor 模块整合到一起进行微调。
替换概率策略
对于整个模型压缩方法来说,撇去原始NLP任务中的超参数外,只有替换概率p(即替换率)这一超参数需要关注。一般来说,使用一个常量0.5就可以达到比较不错的效果。但是文章还提出了一个线性策略来为每个训练step设置不同的替换概率,即文章中提到的curriculum学习策略,其具体公式如下:
其中,t表示当前训练的step,k表示每个step的增长率,b表示初始的替换概率。通过这种策略,统一了此前谈及的两个训练阶段成为一个端到端的从易到难的学习过程。在初始阶段,暴露较多的 predecessor,让这些predecessor参与训练,能够提升整个模型的质量,得到更小的loss,这能够平滑整个训练过程平滑而不会过于震荡;而在训练后期,由于模型整体学习都比较好了,模型可以逐渐摆脱对 predecessor 的依赖,并让更多的successor参与后续的训练,进而使整个模型能够平稳过度到 successor 微调阶段。此外,在替换训练的初试阶段,当 ,训练过程平均被替换的模块数量的期望值是 n* p_d,所有n个 successor 的期望学习率:
lr表示整个训练过程设置的固定学习率,lr'表示所有successor模块的等效学习率。因此,使用这种替换策略相当于在训练阶段间接得给学习率应用了一个warm-up策略,间接得提升了模型训练的效率。
实验结果
实验数据集是 GLUE。由于基于 Theseus 的模型压缩方案并不是针对预训练阶段而是面向特定任务(即常说的微调阶段),所以只需要用到GLUE中的train set即可进行模型压缩。相比于 DistillBERT 的模型压缩需要耗费720个小时的GPU,基于 Theseus方案只需约20个小时的GPU。不同模型压缩方法的对比如 Table 1所示:
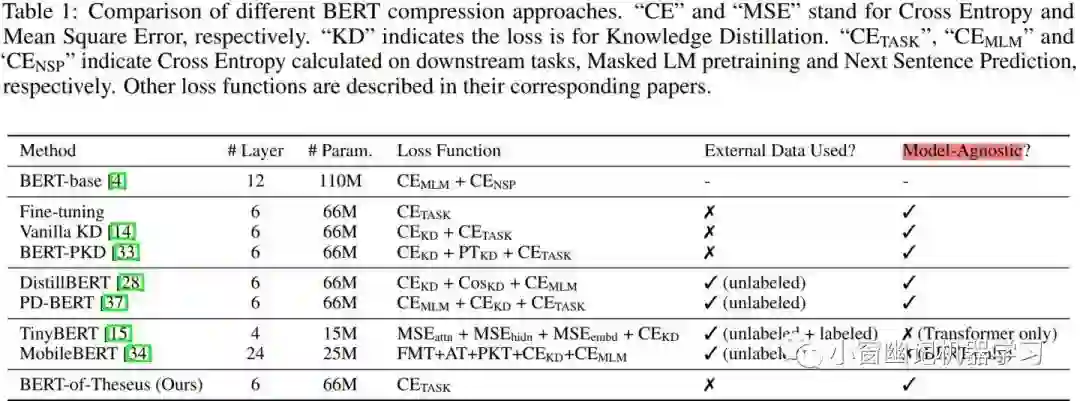
对比的方面有:层数、参数量、损失函数、使用外部数据的使用情况等。另外,由于TinyBERT的尺寸设置不同、不仅使用2阶段蒸馏还使用了数据扩增,所以在后续试验阶段的对比并不考虑TinyBERT。如果从损失函数、是否使用外部数据和是否局限特定模型来看,基于 Theseus 的方案无疑是最佳的。
各个模型在GLUE dev、test数据集上的评测结果如 Table 2和 Table 3所示:

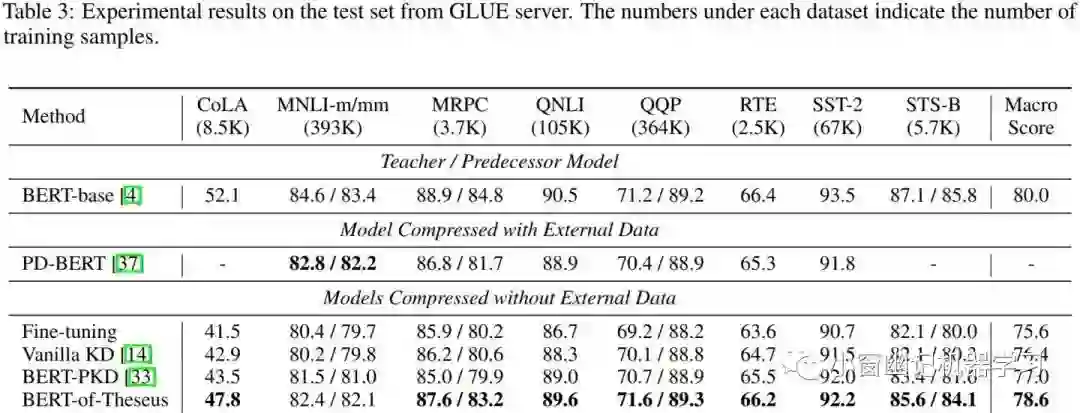
可以看出,BERT-of-Theseus在GLUE的dev set 和 test set上分别能够保持BERT-base的98.4%、98.3%性能。其中 Fine-tuning 模型是用6-layer(层数与BERT-of-Theseus一样) 的BERT在GLUE上fine-tune的结果。在GLUE的每个任务上,BERT-of-Theseus都优于Fine-tuning 模型,由于使用相同损失函数,所以这充分表明BERT-of-Theseus中所用到的方法确实可以将知识从 predecessor 有效地转移到 successor。
此外,有学者发现在 MNLI 数据集上微调过的模型能够成功迁移到其他句子分类任务。因此,文章将基于 MNLI 压缩后的模型作为一个通用压缩版BERT,以用于下游任务。再用其他句子分类任务来微调压缩后的模型,该模型与 DistillBERT 在GLUE dev数据集上的对比如 Table 4所示:

可以看出,通用型的BERT-of-Theseus在MRPC上与DistillBERT的得分相同,但在其他句子级任务上碾压式地将DistillBERT摁在地上摩擦。

总结
文章提出一种名为 Theseus的模型压缩方法,并将该方法应用于BERT模型压缩,实验结果表明该方法优于其他知识蒸馏方法,更加可(气)喜(人)的是该方法只有一个超参数和一个损失函数,无需额外的数据。文章所提出的 theseus 模型压缩方法在模型压缩领域开创了一个新的方向。基于theseus的模型压缩并不依赖于任何与特定模型相关的特征,因此有潜力将其应用到其他大模型(比如ResNet)的压缩。作者表示后续的研究方向是将基于theseus的模型压缩方法应用于卷积神经网络和图神经网络,期待下吧~~~
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


