综述:如何给模型加入先验知识

极市导读
端到端的深度神经网络虽然能够自动学习到一些可区分度好的特征,但是往往会拟合到一些非重要特征,导致模型会局部坍塌到一些不好的特征上面。本文通过一个简单的鸟类分类案例来总结了五个给模型加入先验信息的方法。>>加入极市CV技术交流群,走在计算机视觉的最前沿
模型加入先验知识的必要性
端到端的深度神经网络是个黑盒子,虽然能够自动学习到一些可区分度好的特征,但是往往会拟合到一些非重要特征,导致模型会局部坍塌到一些不好的特征上面。常常一些人们想让模型去学习的特征模型反而没有学习到。
为了解决这个问题,给模型加入人为设计的先验信息会让模型学习到一些关键的特征。下面就从几个方面来谈谈如何给模型加入先验信息。
为了方便展示,我这边用一个简单的分类案例来展示如何把先验知识加入到一个具体的task中。我们的task是在所有的鸟类中识别出一种萌萌的鹦鹉,这中鹦鹉叫鸮(xiāo)鹦鹉,它长成下面的样子:

这种鸟有个特点:
就是它可能出现在任何地方,但就是不可能在天上,因为它是世界上唯一一种不会飞的鹦鹉(不是唯一一种不会飞的鸟)。
好,介绍完task的背景,咱们就可以分分钟搭建一个端到端的分类神经网络,可以选择的网络结构可以有很多,如resnet, mobilenet等等,loss往往是一个常用的分类Loss,如交叉熵,高级一点的用个focal loss等等。确定好了最优的数据(扰动方式),网络结构,优化器,学习率等等这些之后,往往模型的精度也就达到了一个上限。
然后你测试模型发现,有些困难样本始终分不开,或者是一些简单的样本也容易分错。这个时候如果你还想提升网络的精度,可以通过给模型加入先验的方式来进一步提升模型的精度。
基于pretrain模型给模型加入先验
给模型加入先验,大家最容易想到的是把网络的weight替换成一个在另外一个任务上pretrain好的模型weight。经过的预训练的模型(如ImageNet预训练)往往已经具备的识别到一些基本的图片pattern的能力,如边缘,纹理,颜色等等,而识别这些信息的能力是识别一副图片的基础。如下图所示:
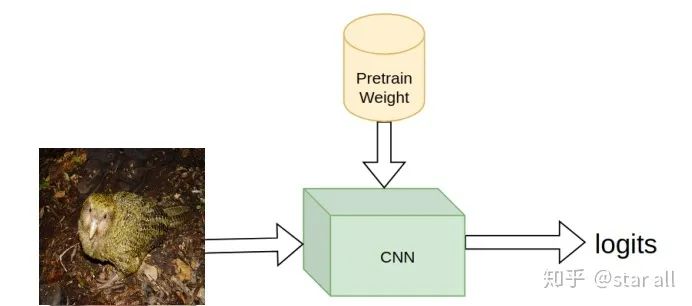
但这些先验信息都是一些比较general的信息,我们是否可以加入一些更加high level的先验信息呢。
基于输入给模型加入先验
假如你有这样的一个先验:
你觉得鸮鹦鹉的头是一个区别其他它和鸟类的重要部分,也就是说相比于身体,它的头部更能区分它和其他鸟类。
这时怎么让网络更加关注鸮鹦鹉的头部呢。这时你可以这样做,把整个鸮鹦鹉和它的头部作为一个网络的两路输入,在网咯的后端再把两路输入的信息融合。以达到既关注局域,又关注整体的目的。一个简单的示意图如下所示。
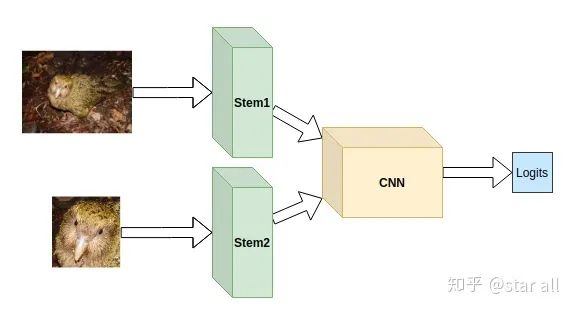
基于模型重现给模型加入先验
接着上面的设定来,假如说你觉得给模型两路输入太麻烦,而且增加的计算量让你感觉很不爽。
这时,你可以尝试让模型自己发现你设定的先验知识。
假如说你的模型可以自己输出鸟类头部的位置,虽然这个鸟类头部的位置信息是你不需要的,但是输出这样的信息代表着你的网络能够locate鸟类头部的位置,也就给鸟类的头部更加多的attention,也就相当于给把鸟类头部这个先验信息给加上去了。
当然直接模仿detection那样去回归出位置来这个任务太heavy了,你可以通过一个生成网络的支路来生成一个鸟类头部位置的Mask,一个简单的示意图如下:
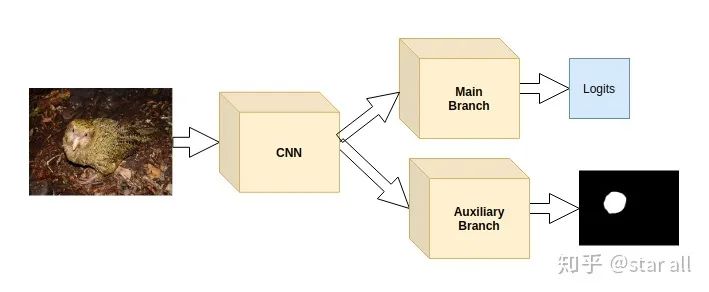
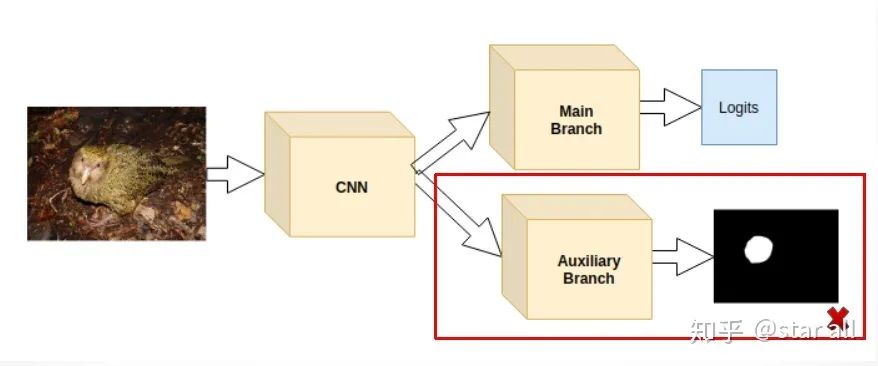
基于CAM图激活限制给模型加入先验
针对鸮鹦鹉的分类,我在上面的提到一个非常有意思的先验信息:
那就是鸮鹦鹉是世界上唯一一种不会飞的鹦鹉。
这个信息从侧面来说就是,鸮鹦鹉所有地方都可能出现,就是不可能出现在天空中(当然也不可能出现在水中)。
也就是说不但鸮鹦鹉本身是一个分类的重点,鸮鹦鹉出现的背景也是分类的一个重要参考。假如说背景是天空,那么就一定不是鸮鹦鹉,同样的,假如说背景是海水,那么也一定不是鸮鹦鹉,假如说背景是北极,那么也一定不是鸮鹦鹉,等等。
也就是说,你不能通过背景来判断一只未知的鸟是鸮鹦鹉,但是你能通过背景来判断一只未知的鸟肯定不是鸮鹦鹉(是其他的鸟类)。
所以假如说获取了一张输入图片的激活图(包含背景的),那么这张激活图的鸟类身体部分肯定包含了鸮鹦鹉和其他鸟类的激活,但是鸟类身体外的背景部分只可能包含其他鸟类的激活。

所以具体的做法是基于激活图,通过限制激活图的激活区域,加入目标先验。
CAM[1]激活图是基于分类网络的倒数第二层卷积层的输出的 feature_map 的线性加权,权重就是最后一层分类层的权重,由于分类层的权重编码了类别的信息,所以加权后的响应图就有了基于不同类别的区域相应。(具体的介绍可以看 https://zhuanlan.zhihu.com/p/51631163),具体的激活图生成方式可以如下表示:
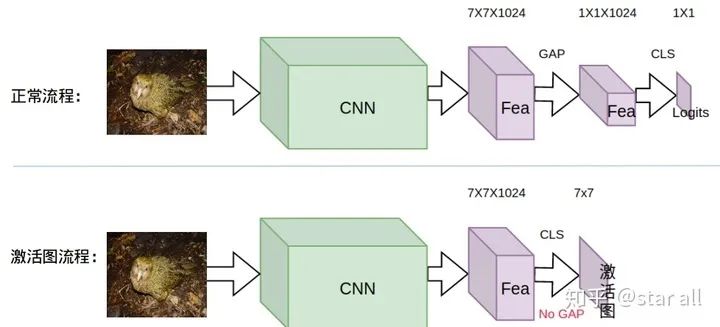
说了这么多,下面就展示展示激活图的样子:


大家可以看到,上面一张是一只鸮鹦鹉的激活图,下面是一只在天空飞翔的大雁的激活图。
因为鸮鹦鹉的Label是0,其他鸟类的Label是1,所以在激活图上,只要是负值的激活区域都是鸮鹦鹉的激活,也就是Label为0的激活,只要是正值的激活都是其他鸟类的激活,也就是Label为1的激活。
为了方便展示,我把负值的激活用冷色调来显示,把正值的激活用暖色调来显示,所以就是变成了上面两幅激活图的样子。而右边的数字是具体的激活矩阵(把激活矩阵进行GAP就可以变成最终输出的Logits)。
到这里不知道大家有没有发现一个问题,就是无论对于鸮鹦鹉还是大雁的图片,它们的激活图除了分布在鸟类本身,也会有一部分分布在背景上。 对于大雁我们好理解,因为大雁是飞在天空中的,而鸮鹦鹉是不可能在天空中的,所以天空的正激活是非常合理的。但是对于鸮鹦鹉来说,其在鸟类身体以外的负激活就不是太合理,因为,大雁或者是其他的鸟类,也可能在鸮鹦鹉的地面栖息环境中(但是鸮鹦鹉却不可能在天空中)。
所以环境不能提供任何证据来证明这一次鸟类是一只鸮鹦鹉,鸮鹦鹉的负激活只是在鸟类的身体上是合理的。而其他鸟类的正激活却可以同时在鸟类身体上又可能在鸟类的背景上(如天空或者海洋)。
所以我们需要这样建模这个问题,就是在除鸟类身体的背景上,不能出现鸮鹦鹉的激活,也就是说不能出现负激活(Label为0的激活)。 所以下面的激活才是合理的:

从上面来看,在除鸟类身体外的背景部分是不存在负激活的,虽然上面的背景部分有一些正的激活(其他鸟类的激活),但是从右边的激活矩阵来看,负激活的scale是占据绝对优势的,所以完全不会干扰对于鸮鹦鹉的判断。
所以问题来了,怎么从网络设计方面来达到这个目的呢?
其实可以从Loss设计方面来达到这个效果。我们假设每一个鸟都有个对应的mask,mask内是鸟类的身体部分,mask外是鸟类的背景部分。那么我们需要做的就是抑制mask外的背景部分激活矩阵的负值,把那一部分负值给抑制到0即可。
鸟类的激活矩阵和mask的关系如下图(红色的曲线代表鸟的边界mask):

我们的Loss设计可以用下面的公式表示:
Loss_cam = -sum(where(bird_mask_outside<0))
具体的网络的framework可以如下所示:
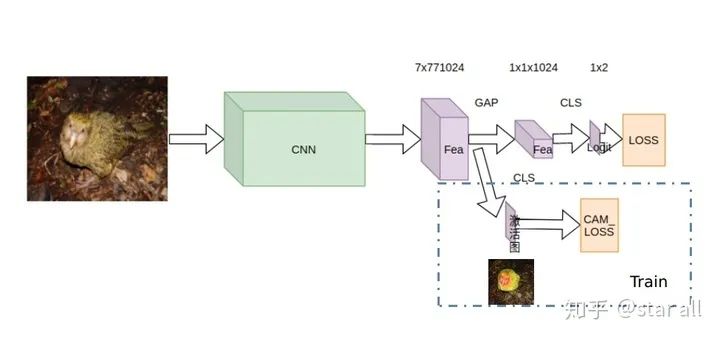
其中虚线部分只是训练时候需要用到,inference的时候是不需要的,所以这种方法也是不会占用任何在inference前向时候的计算量。
基于辅助学习给模型加入先验知识
到现在为止,咱们还只是把我们的鸟类分类的task当成一个二分类来处理,即鸮鹦鹉是一类,其他的鸟类是一类。
但是我们知道,世界的鸟类可不仅仅是两类,除了鸮鹦鹉之外还有很多种类的鸟类。而不同鸟类的特征或许有很大的差别,比如鸵鸟的特征就是脖子很长,大雁的特征就是翅膀很大。

假如只是把鸮鹦鹉当做一类,把其他的鸟类当做一类来学习的话,那么模型很可能不能学到可以利用的区分非鸮鹦鹉的特征,或者是会坍塌到一些区分度不强的特征上面,从而没有学到能够很好的区分不同其他鸟类的特征,而那些特征对去区别鸮鹦鹉和其他鸟类或许是重要的。
所以我们有必要加入其他鸟类存在不同类别的先验知识。而这里,我主要介绍基于辅助学习的方式去学习类似的先验知识。首先我要解释一下什么是辅助学习,以及辅助学习和多任务学习的区别:
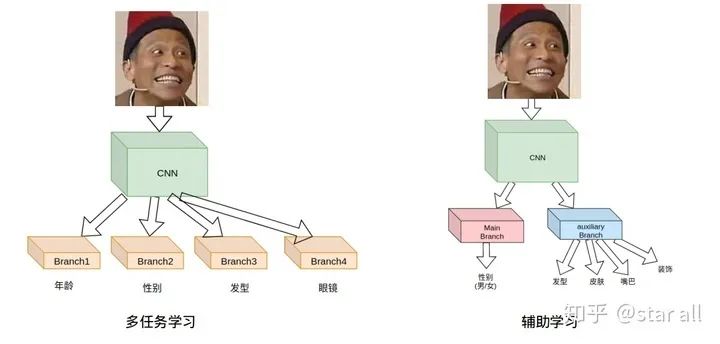
上图的左侧是多任务学习的例子,右侧是辅助学习的例子。左侧是个典型的face attribute的task,意思是输入一张人脸,通过多个branch来输出这一张人脸的年龄,性别,发型等等信息,各个branch的任务是独立的,同时又共享同一个backbone。右边是一个典型的辅助学习的task,意思是出入一张人脸,判断这一张人脸的性别,同时另外开一个(或几个)branch,通过这个branch来让网络学一些辅助信息,比如发型,皮肤等等,来帮助网络主任务(分男女)的判别。
好,回到我们的鸮鹦鹉分类的task,我们可能首先会想到下面的Pipeline:
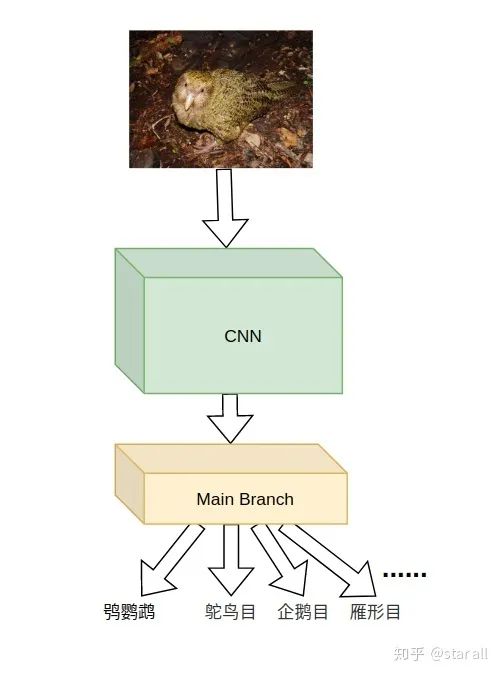
这样虽然可以把不同类别的鸟类的特征都学到,但是却削弱了网络对于鸮鹦鹉和其他鸟类特征的分别。
经过实验发现,这种网络架构不能很好的增加主任务的分类精度。为了充分的学到鸮鹦鹉和其他鸟类特征的分别,同时又能带入不同种类鸟类类别的先验,我们引入辅助任务:
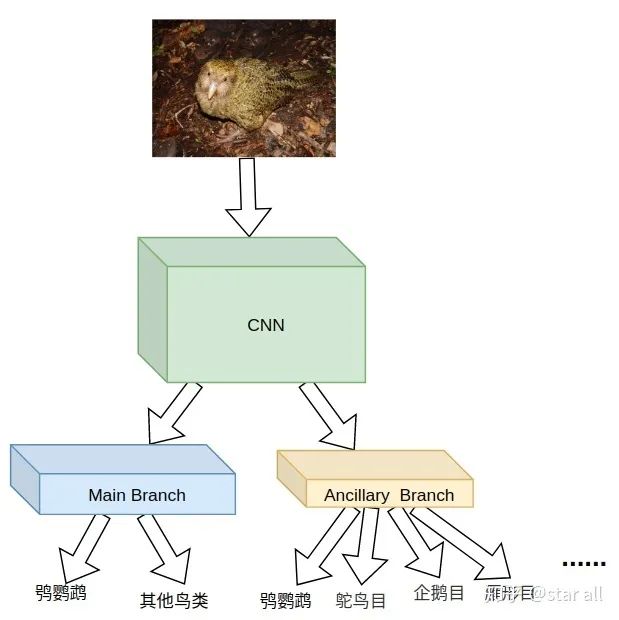
在上面的Pipeline中,辅助任务相比如主任务,把其他鸟类做更加细致的分类。这样网络就学到了区分不同其他鸟类的能力。
但是从实验效果来看这个Pipeline的精度并不高。经过分析原因,发现在主任务和辅助任务里面都有鸮鹦鹉这一类,这样当回传梯度的时候,相当于把区分鸮鹦鹉和其他鸟类的特征回传了两次梯度,而回传两次梯度明显是没用的,而且会干扰辅助任务学习不同其他鸟类的特征。
所以我们可以把辅助任务的鸮鹦鹉类去除,于是便形成了下面的pipeline:
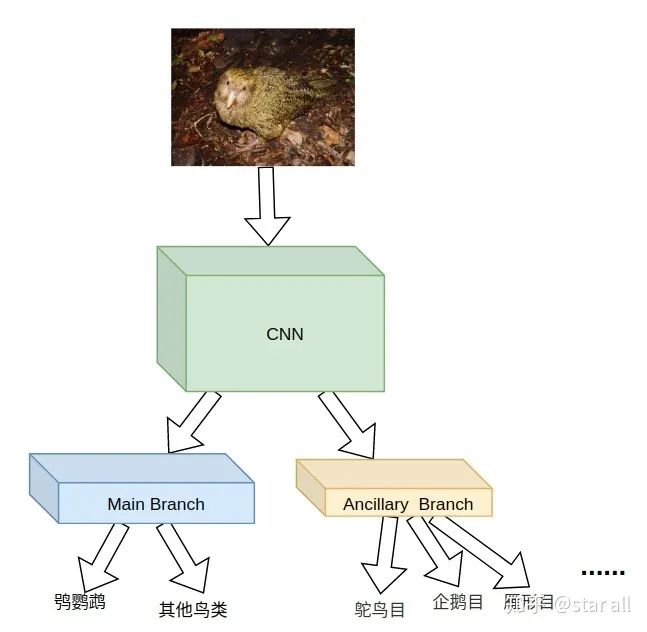
经过实验发现,这种pipeline是有利于主任务精度提升的,网络对于特征明显的其他鸟类的分类能力得到了一定程度的提升,同时对于困难类别的分类能力也有一定程度的提升。
当然,辅助任务的branch可以不只是一类,你可以通过多个类别来定义你的辅助任务的branch:
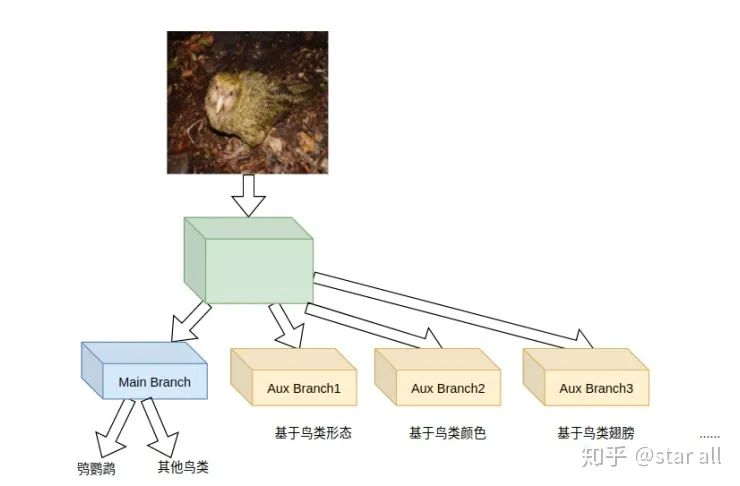
这时候你会想,上面的pipeline好是好,但是我没有那么多的label啊。是的,上面的pipeline除了主任务的label标注,它还同时需要很多的辅助任务的label标注,而标注label是深度学习任务里面最让人头疼的问题(之一)。
别怕,我下面介绍一个work,它基于meta-learning的方法,让你不再为给辅助任务标注label而烦恼,它的framework如下:
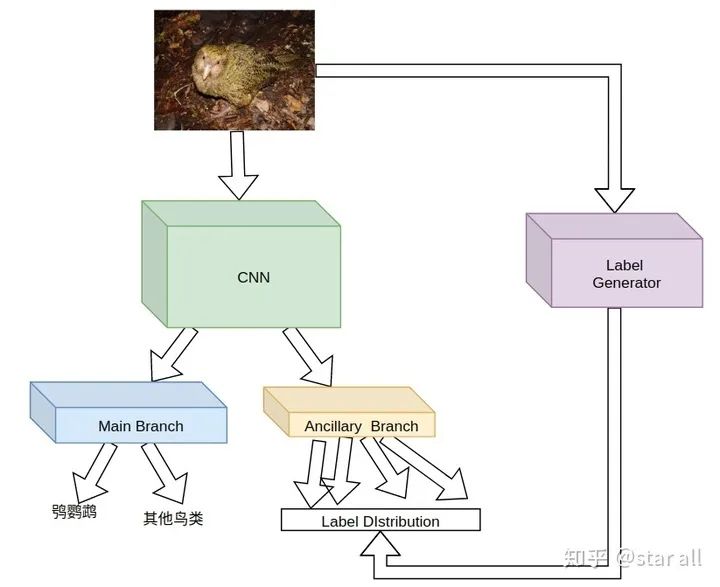
这个framework采用基于maxl[2]的方案(https://github.com/lorenmt/maxl),辅助任务的数据和label不是由人为手工划分,而是由一个label generator来产生,label generator的优化目标是让主网络在主任务的task上的loss降低,主网络的目标是在主任务和辅助任务上的loss同时降低。
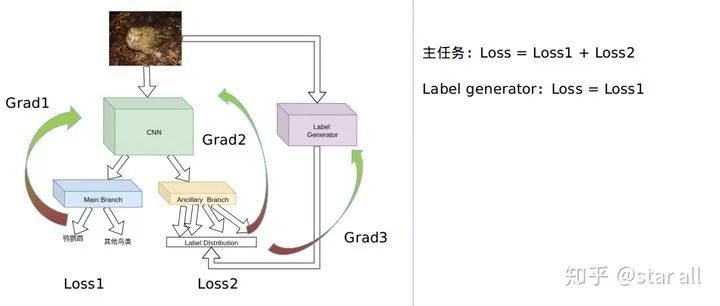
但是这个framework有个缺点,就是训练时间会上升一个数量级,同时label generator会比较难优化。感兴趣的同学可以自己尝试。但是不得不说,这篇文章有两个结论倒是很有意思:
-
假设 primary 和 auxiliary task 是在同一个 domain,那么 primary task 的 performance 会提高当且仅当 auxiliary task 的 complexity 高于 primary task。 -
假设 primary 和 auxiliary task 是在同一个 domain,那么 primary task 的最终 performance 只依赖于 complexity 最高的 auxiliary task。
结语
先总结一下所有可以有效的加入先验信息的框架:
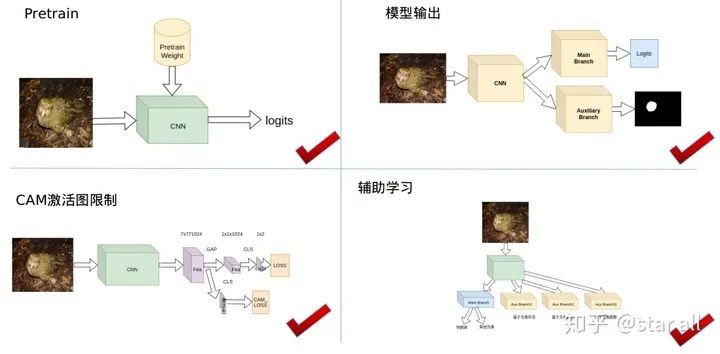
你可以通过上述框架的选择来加入自己的先验信息。
给神经网络的黑盒子里面加入一些人为设定的先验知识,这样往往能给你的task带来一定程度的提升,不过具体的task需要加入什么样的先验知识,需要如何加入先验知识还需要自己探索。
来自我自己的博客:https://zhengtq.github.io/2020/07/30/pri-knowledge-1/
参考
-
^CAM https://arxiv.org/abs/1512.04150 -
^maxl https://arxiv.org/abs/1901.08933
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



