不用任何数学方法,如何计算圆面积
选自medium
杀鸡用牛刀,我们用机器学习方法来算圆的面积。
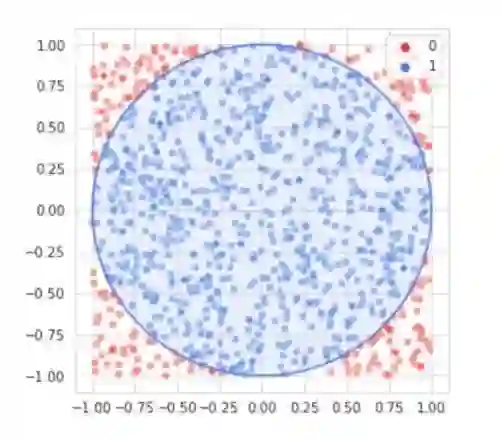
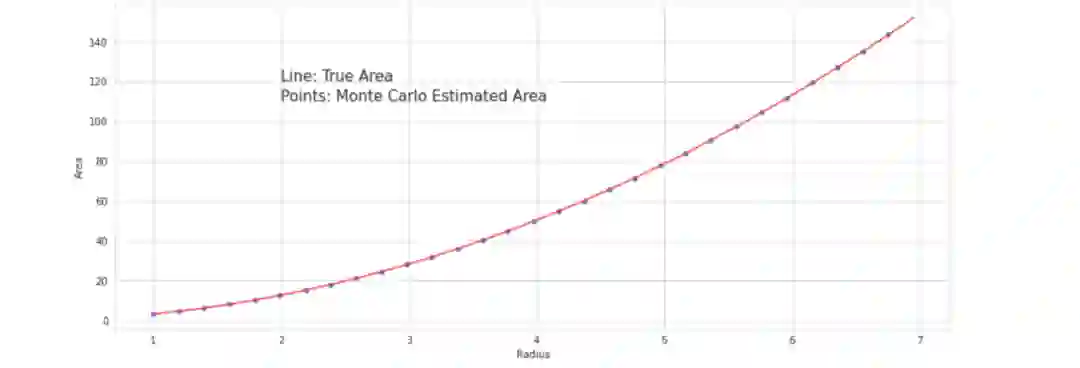
import numpy as np
from tqdm import tqdm #Just a progress bar indicator
#Number of randomized points to generate for each approximation
num_points = 250_000
#Lists to store the radius and its corresponding area approximation
radii = []
areas = []
#For each of the 500 equally spaced values between 1 and 100 inclusive:
for radius in tqdm(np.linspace(1,100,500)):
#A counter for the number of points in the circle
in_circle = 0
for i in range(num_points):
#Generate an x and y coordinate from a uniform distribution bounded by a tangent box
xcoor = np.random.uniform(-radius,radius)
ycoor = np.random.uniform(-radius,radius)
#If the point is inside the circle, add one to in_circle
if xcoor**2 + ycoor**2 < radius**2:
in_circle += 1
#Get the fraction of the points that were inside the circle
area_frac = in_circle/num_points
#Append the approximated area and the radius
areas.append(area_frac*(4*(radius**2)))
radii.append(radius)模型参数:模型进行自动调整从而找到最佳参数,在这种情况下,参数为 a。如果具有 n 个参数,则该模型被称为 n 维。我们所使用的最基本模型是一维的,而对图像进行分类的深度神经网络有可能具有数百万个维度。
损失函数:损失函数是对当下模拟情况进行评估,并希望找到可以得到最低误差度的参数集,从而使得损失函数最小化。比如某个参数值 j 的损失函数值为 3,而参数值 k 的损失函数值为 2,则理应选择参数值 k。
平均绝对误差(MAE):我们将使用损失函数/错误度量,其原因是因为它易于使用且易于理解。给定当前参数(a)和模型预测值,而平均绝对误差是指预测值与真实值之间平均相差有多大,较低的 MAE 意味着模型更适合数据。
学习率:为了优化参数,模型会在特定「方向」上逐渐调整参数。由于我们现在的模型仅优化一个参数(a),因此仅需决定在一维平面上是增大或是减小参数值(任何变化都会产生较低的损失函数)。而模型在调整过程中的移动量称为学习率。较高的学习速度意味着模型有可能短时间内就能得到一组效果较好的参数,但无法保证其准确度,而较低的学习率能够获得非常不错的参数,并且拥有较高的准确度,唯一一点是需要大量的训练时间。
把参数 coef(a)初始化为 0.1。
对于训练周期中的每次迭代:
对 coef 提出两条路径;coef+lr 和 coef-lr,其中 lr 是学习率。
对使用 coef=coef+lr 的模型和使用 coef=coef-lr 的模型评估平均绝对误差。
将 coef 设置为等于 coef+lr 和 coef-lr 中平均绝对误差值较小的那个数字。
coef = 0.1 #Initial coefficient value
learning_rate = 0.00001 #How fast the model 'learns'
iterations = 100000 #How many times we want the model to 'practice and correct'
for i in tqdm(range(iterations)): #note - tqdm is just a progressbar
#Propose two path for the coefficient:
up_coef = coef + learning_rate #Move up
down_coef = coef - learning_rate #Or move down
#Store the predictions for a model using parameters up_coef and down_coef
up_pred = []
down_pred = []
#For each radius value in the previously created list radii:
for r in radii:
#Append the model using up_coef's and down_coef's prediction (a*r^2)
up_pred.append(up_coef*(r**2))
down_pred.append(down_coef*(r**2))
#Find the MAE. Both are converted to NumPy arrays for easy operation.
up_coef_mae = np.abs(np.array([up_pred])-np.array([areas])).mean()
down_coef_mae = np.abs(np.array([down_pred])-np.array([areas])).mean()
#If moving the coefficient down yields a lower (better) MAE:
if down_coef_mae < up_coef_mae:
#Set it equal to down_coef
coef = down_coef
#Otherwise (moving the coefficient up yields a lower (better) or equal MAE:
else:
#Set it equal to up_coef
coef = up_coefprint(str(coef)[:5]) #first four digits of coefficient (decimal point counts as a character)
[Output]: '3.141'
当然,计算圆面积的公式很好记就是𝜋r²。无需使用微积分中的任何复杂的数学方法或其他证明,我们就能找到它的公式,并找到一种使用蒙特卡洛模拟和二次回归找到𝜋值的方法。使用这种思路就可以找到计算圆面积的方法——当然也可以找到任何图形的面积计算公式——椭圆、心形、二维的乌龟形状——只要参数可以说明它的轮廓。
机器之心联合 AWS 开设线上公开课,通过 6 次直播课程帮助大家熟悉 Amazon SageMaker 各项组件的使用方法,轻松玩转机器学习。
6 月 2 日 20:00,AWS解决方案架构师尹振宇将带来第 3 课,详解如何利用SageMaker Operator简化Kubernetes 上的机器学习任务管理。
点击阅读原文或识别二维码,立即预约直播。