Facebook AI-《优化大规模神经推荐的基础设施》
【导读】本文是Facebook AI博客《Optimizing infrastructure for neural recommendation at scale》的翻译。该博客介绍了一个冷门但却非常实用的研究方向——如何为大规模神经推荐系统优化基础设施。
本文翻译自Facebook AI博客《Optimizing infrastructure for neural recommendation at scale》。原文链接:
https://ai.facebook.com/blog/-optimizing-infrastructure-for-neural-recommendation-at-scale/
我们在研究什么?
我们分享一个在大规模深度神经网络(DNN)推荐中用于处理个性化结果的的基础设施。虽然DNN常被用来辅助构建互联网应用,如生成搜索结果、提供内容建议等,只有很少的相关研究关注于优化大规模推荐系统的基础设施。除了介绍这类神经推荐模型在产品端的重要性,本文还介绍了一些开源工作和相关的性能指标,以帮助研究者和工程师来评价他们构建的DNN模型。
值得注意的几点发现:
在三代Intel服务器上,系统异构性导致了大量推断延迟的变化。
推荐推断的批量和托管可以很大程度地提升生产力。
推荐模型架构的异构性使得不同的系统优化策略成为必要。
它是如何工作的?
为了分析产品级推荐模型的性能,我们先设计了推荐的量化指标。然后我们设计了一系列合成推荐模型,来描述各种Intel CPU系统的推断性能。我们的结果高亮了提升面向推荐系统的DNN(相对于传统CNN和RNN)的性能所面临的挑战。
比如,我们发现在数据中心常用的三代Intel服务器 —— Broadwell, Haswell, 和Skylake架构 —— 在处理产品级推荐模型时有着不同的推断延迟。Skylake系统使得加速计算密集型推荐更加容易,并且当多个模型位于同一系统中时,独占缓存层次结构不太容易出现延迟退化。考虑到在协同模型时吞吐量的改进,识别这些特征有助于改进数据中心如何调度推荐推断请求和优化基础设施效率。
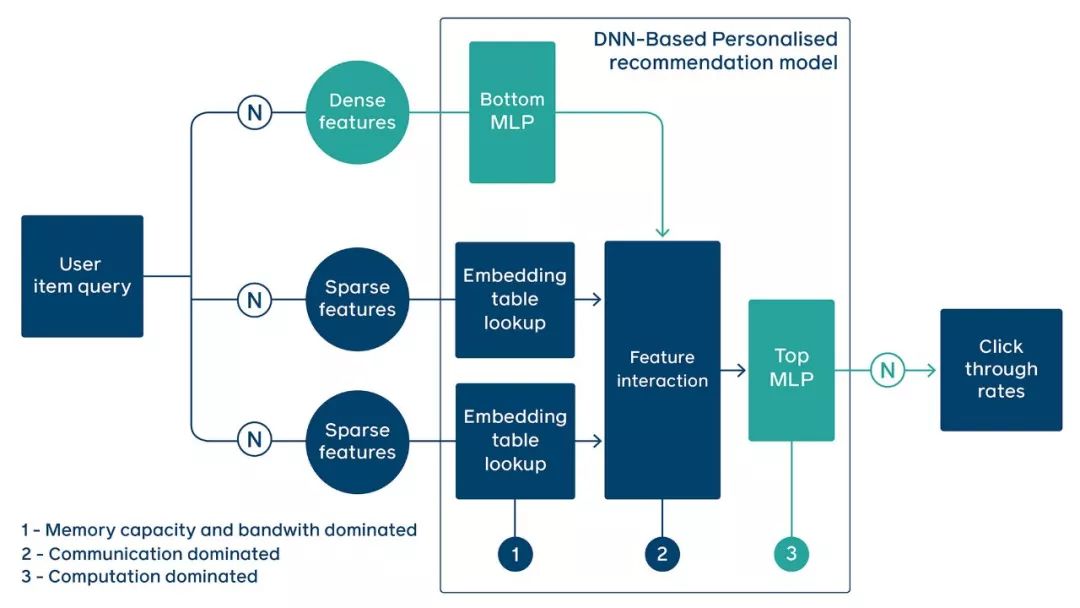
该图显示了深度学习推荐推断的执行流程:模型的输入(N)是连续(密集)和类别(稀疏)特征的集合。使用嵌入表将推荐模型特有的稀疏特征转换为密集表示(表示为蓝色)。嵌入表的数量/大小、每个表的稀疏特征(ID)查找的数量、底部FC层和顶部FC层的深度/宽度根据用例的不同而变化。
更普遍的是,我们发现基于DNN的推荐系统与传统的神经网络在以下几个重要方面有所不同:
高质量的个性化推荐需要更大的存储容量。
大规模推荐推断的执行会产生不规律的内存访问。
生产中推荐用例的多样性可能会产生多样的操作级别性能瓶颈。
产生这种资源需求特性的部分原因是稀疏和密集特征的普遍存在。例如,在对视频进行排序时,模型必须考虑到每个用户提供的稀疏输入,只与给定平台上数千甚至数百万视频中的一小部分进行交互。在加速基于DNN的推荐模型时,工程师需要考虑广泛的性能和资源需求特征,包括推荐推断硬件的设计和优化。
为什么这很重要?
提升大规模推荐系统的推断效率将有助于更快、更准确地对视频、产品等的排序结果进行个性化推荐。从这个分析中得到的见解可以用于激发更广泛的系统和体系结构优化,以实现大规模推荐。
这项工作建立在Facebook之前发布的高级深度学习推荐模型DLRM的基础上,该模型可以支持推荐系统的算法实验和基准测试。我们希望通过分享我们的研究结果和开放源代码的合成模型,进一步揭示下一代AI系统的优化机会,并帮助加速整个AI社区在神经推荐系统设计和建模方面的创新。
参考链接:
https://ai.facebook.com/blog/-optimizing-infrastructure-for-neural-recommendation-at-scale/





