对新手友好的PyTorch深度概率推断工具Brancher,掌握ML和Python基础即可上手
机器之心报道
参与:一鸣、张倩
近日,来自荷兰拉德堡德大学(Radboud University)团队的开发者在 reddit 上发布了一个 PyTorch 深度概率推断工具——Brancher,旨在使贝叶斯统计和深度学习之间的集成变得简单而直观。与其他概率推断工具相比,Brancher 对新手更加友好,只具备机器学习和 Python 基础的人也可以上手使用。
项目地址:https://brancher.org/

特点
Brancher 官网显示,这一工具具有灵活(flexible)、集成(integrated)、直观(intuitive)的特点。
灵活:易于扩展建模带有 GPU 加速的 PyTorch 后端的框架
集成:易于使用带有 Pandas 和 Seaborn 支持的当前工具
直观:易于利用数学类语法学习符号推理
与其他概率建模工具有什么区别?
项目的主要开发者 LucaAmbrogioni 表示,与 Brancher 紧密相关的两个模块是 Pyro 和 PyMC3。Brancher 的目标受众比 Pyro 更广泛,包括那些只接受过机器学习和 Python 编程基本培训的人。界面设计得尽可能接近数学。缺点是 Brancher 不如 Pyro 灵活。
Brancher 的前端与 PyMC3 非常相似。与 PyMC 的主要区别在于,Brancher 构建在深度学习库 PyTorch 的顶部。每一个在 PyTorch 中实现的深度学习工具都可以用来在 Brancher 中构建深度概率模型。此外,PyMC 主要利用采样,而 Brancher 则基于变分推理。
安装
用户需要首先安装 PyTorch,然后使用 pip 命令行:
pip install *brancher*
或从 GitHub 地址克隆代码,Github 地址:https://github.com/AI-DI/Brancher
教程
Google Colab 上有相关教程,包括
Brancher 入门
使用 Brancher 进行时间序列分析
使用 Brancher 进行贝叶斯统计分析
Brancher 入门
Brancher 是一个以用户为中心的概率微分程序包。Brancher 希望能够为初学者提供友好的服务,在保证计算运行效率和灵活性的前提下减少多余的代码。Brancher 以 PyTorch 为核心构建。
安装 Brancher 成功后,首先需要用户导入相关包:
import torch
import matplotlib.pyplot as plt
from brancher.variables import ProbabilisticModel
from brancher.standard_variables import NormalVariable, LogNormalVariable
from brancher import inference
import brancher.functions as BF
Brancher 是一个对象导向的工具包。因此内部的所有对象都是一个类,可以用来抽象化为概率计算程序。建立所有 Brancher 程序的基础组件是 RandomVariable 类。通过微分方程连接随机变量,可以建立概率模型。
例如,可以建立这样一个模型,其中一个正则随机变量的均值是由另一个正则随机变量的正弦函数值决定的。Brancher 可以让你像在学术论文里那样使用符号定义模型。
创建变量:
nu = LogNormalVariable(loc=0., scale=1., name="nu")
mu = NormalVariable(loc=0., scale=10., name="mu")
x = NormalVariable(loc=BF.sin(mu), scale=nu, name="x")
使用定义好的变量创建一个概率模型:
model = ProbabilisticModel([x, mu, nu])
打印模型的内部组成:
model.model_summary
打印结果:

正如我们所预计的那样,变量 x 是 mu 和 nu 的计算结果。但是,列表中也出现了 mu_mu 或 mu_sigma 这样没有提前明确定义的变量。这些确定变量(Deterministic Variables)代表的是概率分布参数的固定值。确定变量是 Brancher 中的特例,和随机变量相似,但值是确定的。我们不需要定义他们,只需要在计算时输入数字即可。
由于现在没有输入数据,因此 Observed 一栏为 False,现在我们输入一些样本数据,看看概率模型如何工作。
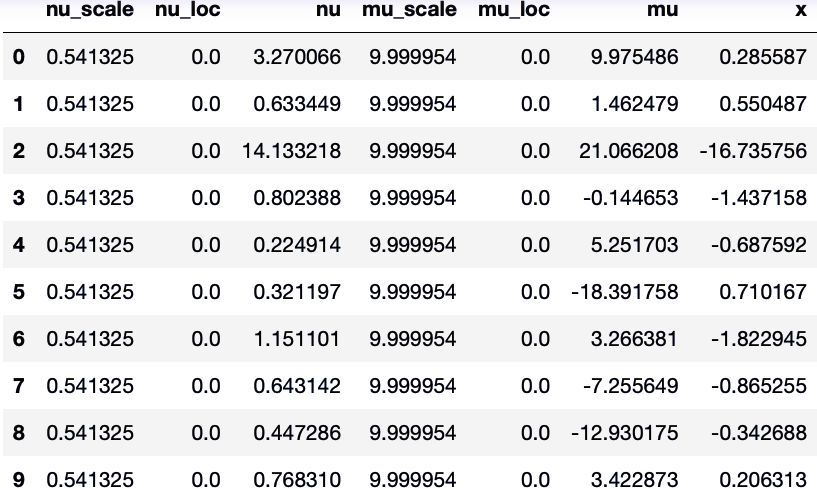
sample = model.get_sample(10)
sample
如果只需要单个变量的结果:
x_sample = x.get_sample(10)
x_sample

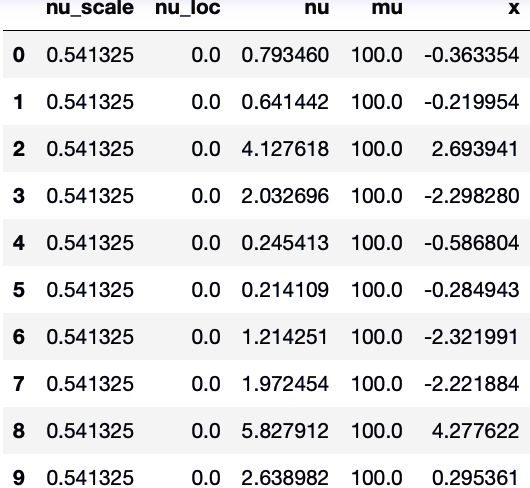
我们还可以做到通过输入某些变量的值后进行采样,如设定 mu 变量为 100 时,查看样本结果:
in_sample = model.get_sample(10, input_values={mu: 100.})
in_sample
为了对某些已知的值进行上采样,我们需要定义一些观测值,并使用变分推断的方法获得分布。我们可以首先对 mu 和 nu 变量定义一些真实值,并生产一些观测结果:
nu_real = 0.5
mu_real = -1.
data = x.get_sample(number_samples=100, input_values={mu: mu_real, nu: nu_real})
现在我们可以告诉 Brancher 变量 x 是从生成数据的值中观察到的。
x.observe(data)
model.model_summary

这时可以看到变量 x 变为 observed。
如果你想采样下游 x 的变量 mu 和 nu,你需要执行近似贝叶斯推理。在 Brancher 中,可以通过为所有想要采样的变量定义一个变分分布来实现这一点。变分模型本身是一个概率模型,其构造方法与原概率模型完全相同。
指定此分布的最简单方法是使用与原始模型中相同的分布:
Qnu = LogNormalVariable(0., 1., "nu", learnable=True)
Qmu = NormalVariable(0., 1., "mu", learnable=True)
model.set_posterior_model(ProbabilisticModel([Qmu, Qnu]))
现在我们需要使用一些随机优化来学习变分近似的参数。这种技术被称为随机变分推理,该技术非常强大,因为它可以将贝叶斯推理很好地融入到深度学习框架中(实际上 brancher 的目的是与深度神经网络一起作为构建复杂概率模型的模块)。
现在让 Brancher 知道,变量分布的参数可以使用「learnable」flag 学习。接下来学习这些参数:
inference.perform_inference(model,
number_iterations=500,
number_samples=50,
optimizer="Adam",
lr=0.01)
loss_list = model.diagnostics["loss curve"]
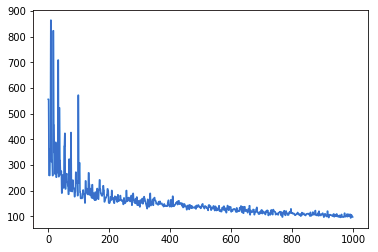
现在把损失函数画出来,以确保一切顺利。
plt.plot(loss_list)
现在从后验取一些样本:
post_sample = model.get_posterior_sample(1000)
post_sample.describe()
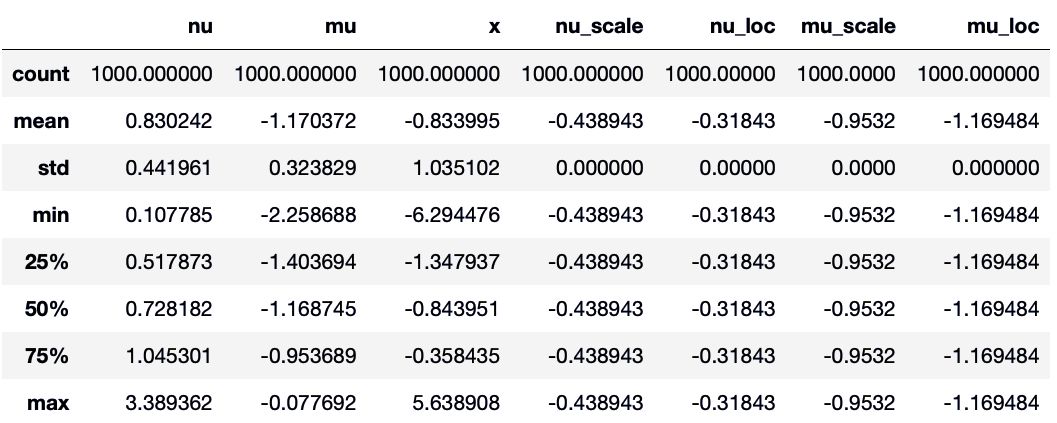
与真值一起绘制后验分布:
g = plt.hist(post_sample["mu"], 50)
plt.axvline(x=mu_real, color="k", lw=2)
[Image: image.png]
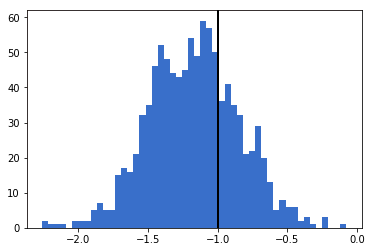
可以用 Brancher 绘制的函数可视化后验分布。这个函数依赖于 Seaborn,Seaborn 是一个非常方便的可视化库,与 panda 结合使用非常好。
from brancher.visualizations import plot_posterior
plot_posterior(model, variables=["mu", "nu", "x"])
更多教程请参考:
使用 Brancher 进行时间序列分析,地址:https://colab.research.google.com/drive/1WuVUqr9pahhO4E4ema4vjDxxH-aMvMqb
使用 Brancher 进行贝叶斯统计分析,地址:https://colab.research.google.com/drive/1L3kp7V48mRQYQDimn16OX1l0c0s20JFd
案例
作者提供了许多使用 Brancher 的案例,包括:
自动回归建模
变分自动编码器
多元回归
自动回归建模完整代码:
import matplotlib.pyplot as plt
import numpy as np
from brancher.variables import RootVariable, RandomVariable, ProbabilisticModel
from brancher.standard_variables import NormalVariable, LogNormalVariable, BetaVariable
from brancher import inference
import brancher.functions as BF
# Probabilistic model #
T = 200
nu = LogNormalVariable(0.3, 1., 'nu')
x0 = NormalVariable(0., 1., 'x0')
b = BetaVariable(0.5, 1.5, 'b')
x = [x0]
names = ["x0"]
for t in range(1, T):
names.append("x{}".format(t))
x.append(NormalVariable(b*x[t-1], nu, names[t]))
AR_model = ProbabilisticModel(x)
# Generate data #
data = AR_model._get_sample(number_samples=1)
time_series = [float(data[xt].cpu().detach().numpy()) for xt in x]
true_b = data[b].cpu().detach().numpy()
true_nu = data[nu].cpu().detach().numpy()
print("The true coefficient is: {}".format(float(true_b)))
# Observe data #
[xt.observe(data[xt][:, 0, :]) for xt in x]
# Variational distribution #
Qnu = LogNormalVariable(0.5, 1., "nu", learnable=True)
Qb = BetaVariable(0.5, 0.5, "b", learnable=True)
variational_posterior = ProbabilisticModel([Qb, Qnu])
AR_model.set_posterior_model(variational_posterior)
# Inference #
inference.perform_inference(AR_model,
number_iterations=200,
number_samples=300,
optimizer='Adam',
lr=0.05)
loss_list = AR_model.diagnostics["loss curve"]
# Statistics
posterior_samples = AR_model._get_posterior_sample(2000)
nu_posterior_samples = posterior_samples[nu].cpu().detach().numpy().flatten()
b_posterior_samples = posterior_samples[b].cpu().detach().numpy().flatten()
b_mean = np.mean(b_posterior_samples)
b_sd = np.sqrt(np.var(b_posterior_samples))
print("The estimated coefficient is: {} +- {}".format(b_mean, b_sd))
# Two subplots, unpack the axes array immediately
f, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4)
ax1.plot(time_series)
ax1.set_title("Time series")
ax2.plot(np.array(loss_list))
ax2.set_title("Convergence")
ax2.set_xlabel("Iteration")
ax3.hist(b_posterior_samples, 25)
ax3.axvline(x=true_b, lw=2, c="r")
ax3.set_title("Posterior samples (b)")
ax3.set_xlim(0,1)
ax4.hist(nu_posterior_samples, 25)
ax4.axvline(x=true_nu, lw=2, c="r")
ax4.set_title("Posterior samples (nu)")
plt.show()
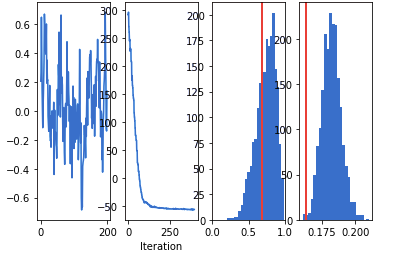
从左到右依次为「Time Series」、「Convergence」、「Posterior Samples (b)」、「Posterior Samples (n)」
更多案例请参考:
使用变分自动编码器学习识别 MNIST 手写数字:https://colab.research.google.com/drive/1EvQS1eWWYdVlhuoP-y1RXED9a2CNu3XQ
多元回归分析:https://colab.research.google.com/drive/1ZyhidyCGEH_epDRt29HzvR65V8EN0kpX

本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com