ACL 2020丨多轮对话推理数据集MuTual发布,聊天机器人常识推理能力大挑战

编者按:在构建聊天机器人时,现有对话模型的回复往往相关性较好,但经常出现常识和逻辑错误。由于现有的大部分检索式对话数据集都没有关注到对话的逻辑问题,导致评价指标也无法直接反映模型对对话逻辑的掌握程度。对此,微软亚洲研究院发布了多轮对话推理数据集 MuTual,针对性地评测模型在多轮对话中的推理能力。
一般情况下,构建聊天机器人主要有两种解决方案:
检索式的方法依赖文本匹配技术,在诸多候选回复中,选择匹配分数最高的作为回复;
生成式的方法使用 Seq2Seq 模型,编码器读取对话历史,解码器直接生成相应回复。
前者凭借回复相关性高,流利度高等优势,在工业界取得了更多的应用。
以 BERT 为代表的预训练模型为自然语言处理领域带来了新的春天,在聊天机器人上也不例外。在检索式多轮对话任务中,基于 BERT 的模型在 Ubuntu Dialogue Corpus 上达到了惊人的85.8%的 R_10@1,93.1%的 R_10@2 和高达98.5%的 R_10@5,已经基本接近了人类的表现。
但实际应用中,当前的对话模型选择出的回复往往相关性较好,但是经常出现常识和逻辑错误等问题。由于现有的大部分检索式对话数据集都没有关注这种对话逻辑问题,导致评价指标也无法直接反映模型对对话逻辑的掌握程度。针对此问题,微软研究院提出了多轮对话推理数据集 MuTual。
相比现有的其他检索式聊天数据集,MuTual 要求对话模型具备常识推理能力;相比阅读理解式的推理数据集,MuTual 的输入输出则完全符合标准检索式聊天机器人的流程。因此,MuTual 也是目前最具挑战性的对话式数据集。测试过多个基线模型后,RoBERTa-base 表现仅为70分左右。目前已有多个知名院校和企业研究部门进行了提交,最优模型可以达到87分左右,仍与人类表现有一定差距。
论文地址:http://arxiv.org/abs/2004.04494
GitHub地址:https://github.com/Nealcly/MuTual
Learderboard地址:https://nealcly.github.io/MuTual-leaderboard

现有的检索式对话数据集,诸如 Ubuntu、Douban,对于给定的多轮对话,需要模型在若干候选回复中,选出最合适的句子作为对话的回复。然而这些数据集主要关注模型能否选出相关性较好的回复,并不直接考察模型的推理能力。随着 BERT 等预训练模型的涌现,模型在此类数据集上已经达到了很好的效果。
已有的针对推理的数据集(DROP、CommonsenseQA、ARC、Cosmos等)大多被设计为阅读理解格式。它们需要模型在阅读文章后回答额外问题。由于任务不同,这些现有的推理数据集并不能直接帮助指导训练聊天机器人。下表为对话和基于推理的阅读理解的常用数据集:
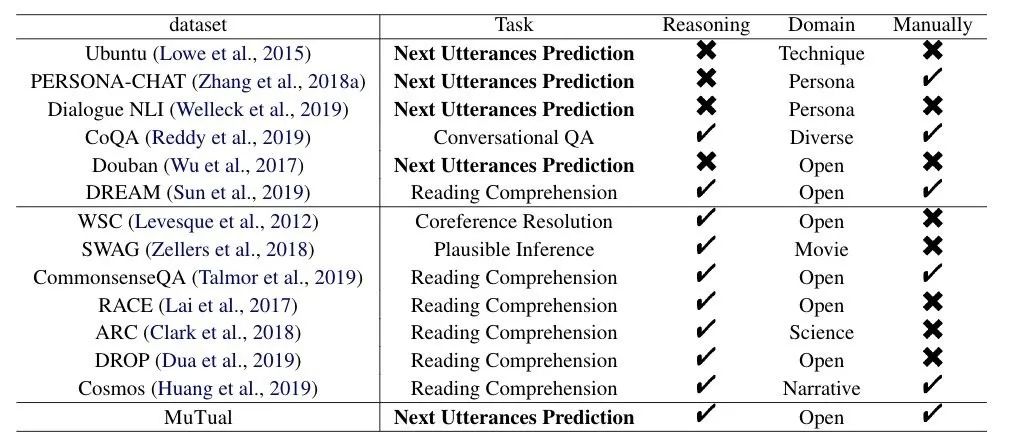
表1:对话和基于推理的阅读理解的常用数据集
因此,基于目前对话数据集的不足,我们提出了一个直接针对 Response Selection 的推理数据集 MuTual。
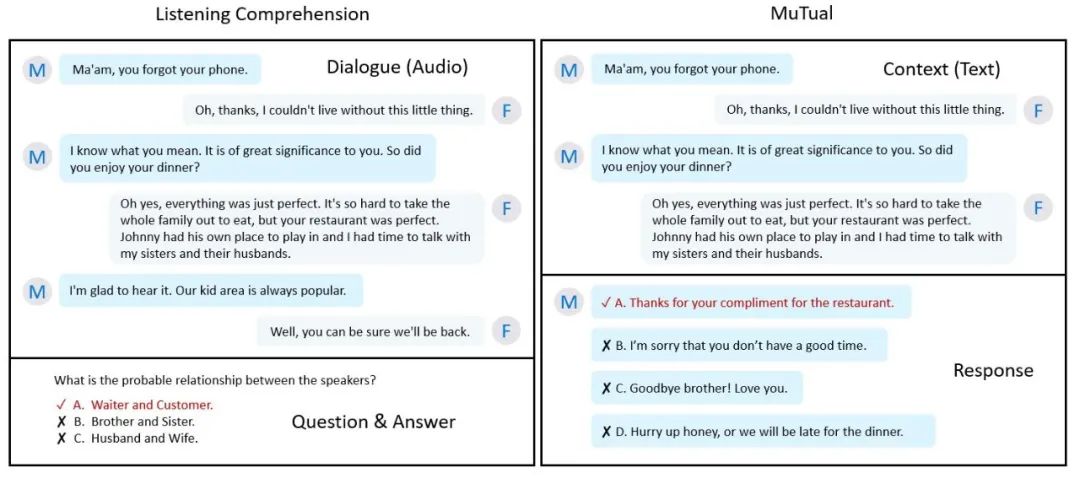
图1:基于听力题改编的 MuTual 数据集样例
MuTual 基于中国高考英语听力题改编。听力考试要求学生根据一段双人多轮对话,回答额外提出的问题(图1左),并通过学生能否正确答对问题衡量学生是否理解了对话内容。为了更自然的模拟开放领域对话,我们进一步将听力题中额外的问题转化为对话中的回复(图1右)。
标注者截选原对话中具备回答问题信息的片段,根据正确选项构造正确的回复(图1右回复 A),根据两个错误选项构造两个错误的回复(回复 C 和回复 D)。
为了进一步提升难度,引入额外的推理信息,标注者还需根据正确选项构建一个负面的回复(回复 B)。另外,标注者需要保证在无上文信息情况下,所有候选回复在逻辑上皆合理。这样可以让数据集聚焦于检测模型在多轮对话中的推理能力,而非判断单个句子是否具有逻辑性。
作者还在标注过程中控制正确和错误的回复与上文的词汇重叠率相似,防止模型可以通过简单的根据文本匹配选出候选回复。MuTual 数据集主要包含聊天机器人需要的六种推理能力:态度推理(13%)、数值推理(7%)、意图预测(31%)、多事实推理(24%)和常识等其他推理类型(9%)。

图2:MuTual 数据集样例。所有的回复都与上下文相关,但其中只有一个是逻辑正确的。一些错误的回复在极端情况下可能是合理的,但正确的回复是最合适的。
在真实应用场景中,检索式对话模型无法检索所有可能的回复,如果没有检索到合适的回复,系统应具有给予安全回复(safe response)的能力。为了模拟这一场景,我们提出了 MuTual plus。对于每个实例,MuTual plus 随机替换掉 MuTual 中一个候选回复。如果正确回复被替换,安全回复即为新的正确回复。如果错误回复被替换,原正确回复仍为四个回复中最合适的。
数据集以 Recall@1(正确检索结果出现在检索结果第一位),Recall@2(正确检索结果出现在检索结果前两位),MRR(Mean Reciprocal Rank, 正确检索结果在检索结果中的排名的倒数)作为评价指标。
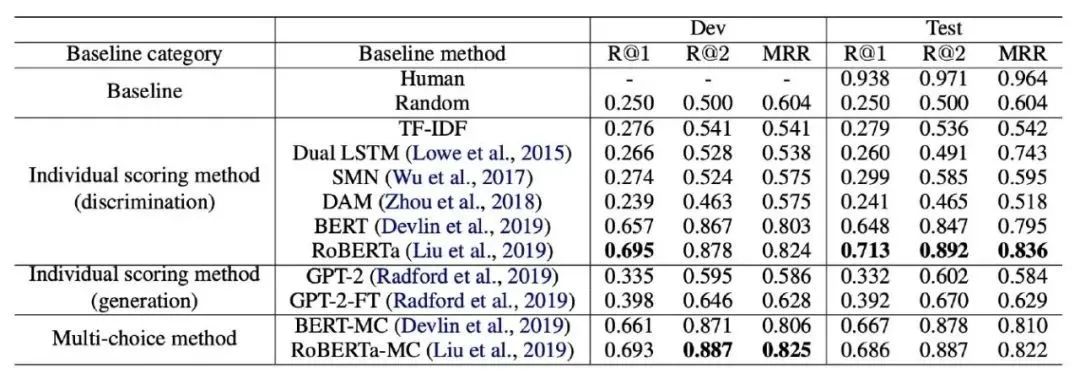
表2:不同方法在 MuTual 数据集上的表现对比。
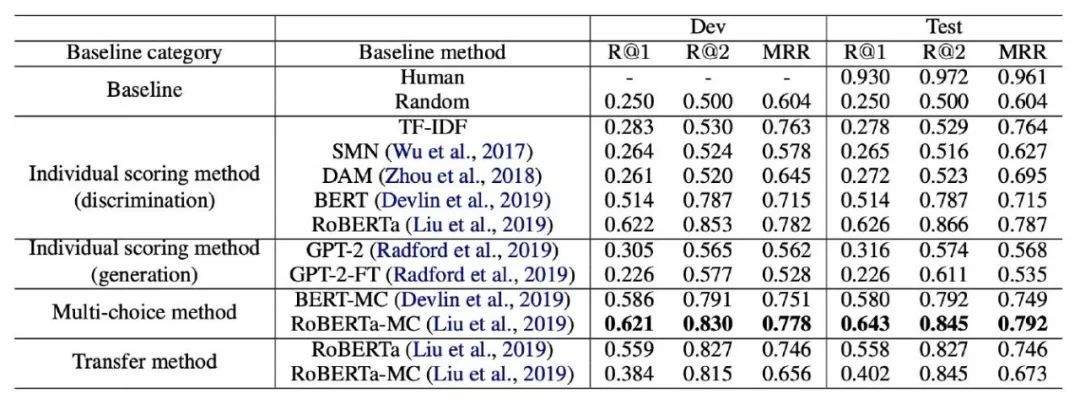
表3:不同方法在 MuTual plus 数据集上的表现对比。
根据表2,3的结果可以看到,之前的检索式对话模型在 MuTual 上,表现只比随机猜的情况好一点。不过预训练模型也不能取得很好的效果,甚至 RoBERTa 也只能达到71%的 Recall@1。然而未经培训的非母语者可以轻松达到94%。
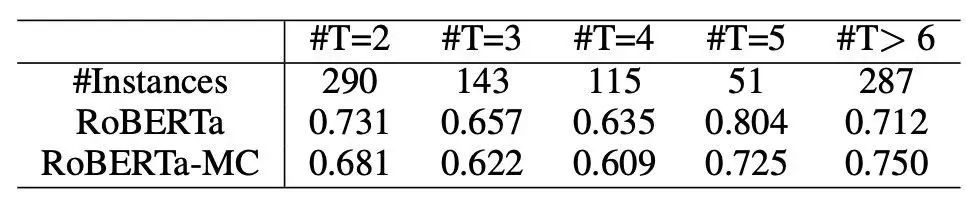
表4:模型在不同上下文轮数数据的 R@1 对比。#T 表示上下文轮数。#Instances 表示实例的数量。
进一步研究发现,与其他多轮对话数据集不同的是,在 MuTual 中,模型表现不会随着对话轮数增加而变差,RoBERTa 在两轮和六轮以上的数据上 R@1 相似。这表示推理能力并不依赖复杂的对话历史。

图3:模型的错误分析
在推理类型方面,模型在数值推理和意图推测中表现的较差。上图第一个例子中,时差运算只需简单的减法(5:00pm - 6h = 11:00am),第二个例子需要推理出对话出现在租房场景中,然而对现有的深度学习模型来说依然十分困难。
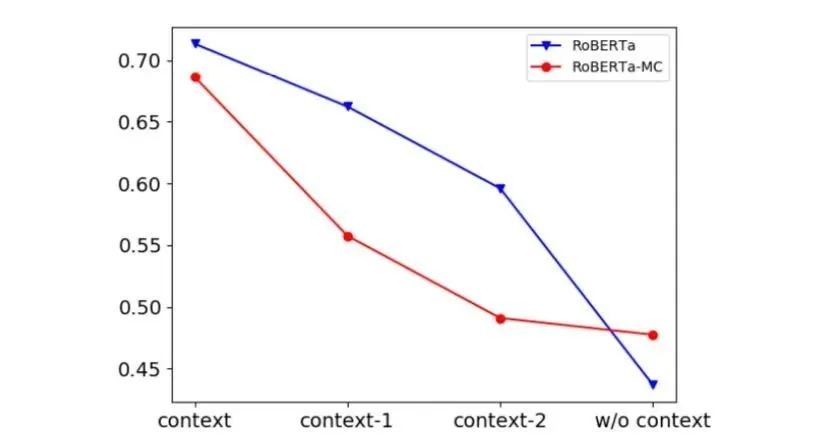
图4:删减上下文信息。w/o context 意味着所有的上下文信息都被删除,模型仅根据四个候选项预测正确的选择。context-n 表示最早的 n 轮对话被删除。
上图展示了前 n 轮对话被删除情况下模型表现显著下滑,证明了解决 MuTual 中的问题需要依赖多轮推理而不是单轮推理。
尽管以 BERT 为代表的预训练模型很大程度上解决了检索式对话的回复相关性问题,但是依然难以解决真实对话场景中的常识和逻辑问题,导致聊天机器人的真实用户体验依然不尽人意。现有的检索式对话数据集都没有直接对该问题进行建模,因此我们提出了 MuTual 数据集,用于针对性地评测模型在多轮对话中的推理能力,欢迎大家下载使用。(本文作者:崔乐阳、吴俣)
你也许还想看:





