选自arXiv
作者:Anna Rogers、Isabelle Augenstein
顶会公布论文评审结果和论文接收结果时,就是大家放肆吐槽评审制度时。
然而,年年吐槽,周而复始。
为什么评审制度还没有得到改进?
问题出在哪里?
来自哥本哈根大学的研究者从多个角度分析评审制度的优缺点,并提出改进建议。
一般来说,同行评审应该是高质量、高影响力研究的过滤器,但事实并非如此:
问题在于,这两项期待从一开始就是不切实际的。
同行评审人员无法执行质量控制,因为那意味着确保论文可复现。
但对于只有几个小时的论文评审而言,这是不可能的。
这其实也是基于深度学习的 NLP 领域的一般问题。
EMNLP 2020 的可复现性清单在这个方向上迈出了第一步。
再来看论文影响力。与科学价值不同,它主要依赖于完全正交的因子:主题的小众程度、文章的宣传力度、论文是否具备较低的进入门槛。
我们可以期待同行评审拒绝有明显方法缺陷的论文,聚焦那些有利于领域发展的 idea。但是,目前的同行评审流程设置并不是为了实现这些目的,而是将所有投稿论文按评分进行排序,筛选出 top 25%。而这项任务基本上是不可能完成的。
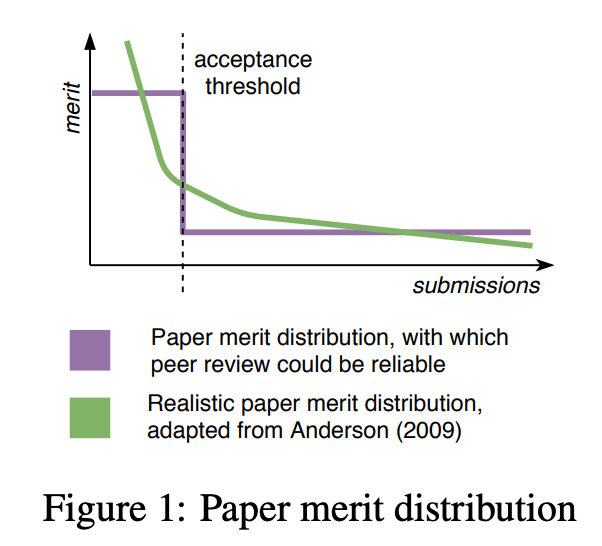
如果论文评分分布在优秀论文和糟糕论文之间有一道明确的界限,那同行评审就很简单了。但是,很显然事实并非如此。基于引用数,Anderson (2009) 假设论文评分符合 Zipf 分布,如图 1 所示。这意味着即使对于最客观的评审者,接收论文中最差的和被拒论文中最好的差异也不到 1%。
![]()
更糟糕的是,并不存在清晰的标准帮助评审人员绘制决策边界。Anderson (2009) 讨论了 SIG-COMM 2006 的一次实验,他们首先对低评分方差的论文给出接收 / 拒绝的决定,然后将高方差的论文分配给 9 位额外的评审人员。评审者不得不讨论难以决定的论文,据报道他们快被这种无法拿来对比的事情逼疯了,如这篇处在被拒边缘的论文缺乏完备的评估,另一篇应用范围较窄。不管我们思考多久,决策结果看起来都是随机的。例如:NIPS 2014 上,两位不同的 PC 对其中 10% 的提交论文进行评审,结果 57% 的论文接收决策是不一致的。
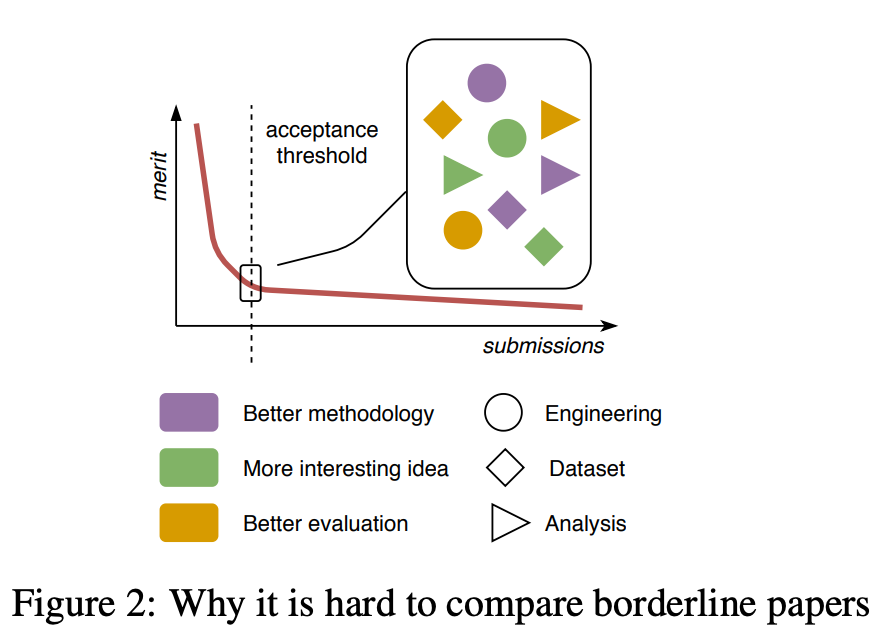
对于大型 ACL 会议而言,情况更加糟糕:我们通常用不同的优缺点对不同类型的论文进行权衡(参见图 2)。哪一篇更有科学价值?这恐怕没有「正确」答案。
![]()
面对客观上不可能的任务,评审人员做了人类在不确定情况下的普遍决策:使用启发式方法,而这引入了偏差。这么做还有一个诱因,将难以比较的事物强行对比是一个很慢、需要深思熟虑、成本较高的过程,而同行评审目前仍是免费的工作。
下文列出了 NLP 领域中一些最有问题的启发式方法:
1. 写作风格:语言错误、不标准的文风或结构很容易看出来,并被认为写作草率。
这就使得几乎所有人在与北美作者的对阵中处于劣势。
2. 实验结果未超过 SOTA:尽管工程贡献应该展示该研究相比之前方法的改进,但未必一定得是预测性能的提升,计算效率或数据效率、可解释性、认知合理性等方面的进步也是有价值的提升。
对预测性能的过度关注鼓励了预训练数据和算力的「军备竞赛」
,加剧了方法论问题。
与最新 SOTA 模型进行对比这项要求把我们变成了转轮子的老鼠,论文提交时实验就已经过时。
3. 主题狭窄:
基于流行的主题写的论文更容易发表
。例如,过去两年 NLP 界的话题霸主 Transformer,光 BERT 就是 150 多项研究进行分析和修改的目标。「热门趋势」形成了一种定势,这类论文应被推荐接收。而小众的主题(如历史文本归一化)被低估(除非它使用了 BERT)。
4. 研究所涉及的语种不包括英语:典型的 NLP 实验使用英语作为目标语言,使用其他语种的论文则被认为小众。这种观点是站不住脚的,因为只在其他小语种上测试的方法和在英语数据上测试的方法具备同等的泛化性能。这强化了英语的「默认」地位。
5. 知名的研究和来自著名实验室的工作:
如果评审人员发现一篇论文已经被研究社区接受了,他们就不会多做审阅
。例如,BERT 论文不可能经历完全匿名的同行评审。
6. 提出的解决方案看起来太简单:典型的「可接收」论文具备复杂的 DL 模型,而简单的解决方案可能看起来像作者没有做太多工作。但这种观点大错特错,
研究的目的是解决问题,而不是用复杂的方式解决问题。
7. 非主流方法:由于目前的「主流」ACL 论文使用基于深度学习的方法,其他方法似乎都不在主流之列,即使 ACL 的全称是「Association for Computational Linguistics」。这就使得跨学科方法处于劣势,例如理论论文和语言资源类文章不被优先考虑,因为它们不包含深度学习实验。
8. 资源论文:在一个如此依赖监督式机器学习的领域中,资源论文却经常因其是资源论文而被拒。
9. 新方法:这听起来很荒谬,但科学同行评审整体上偏向无可非议(而不是新颖)的工作。评审过程支持「安全」、渐进式,甚至有些无聊的工作,而把非主流的工作置于劣势地位。
10. 替换问题:「这篇论文有多好?」是一个很难回答的问题,因为科学评分的标准很模糊。人类在回答难题时通常倾向于用一个简单的问题替换掉它。该研究怀疑其中一个替换问题是「这篇论文是否存在明显的改进方式?」这就能解释长论文和短论文的接收率差距了,因为后者包含的细节和实验较少,更容易被挑出错误。
同行评审虽然有诸多问题,但仍然算是目前不错的选择,仍有很大的改进空间。
首先,同行评审成为学术简历的重要部分,雇主愿意投入时间的事情。工作量过大的人在自由时间做的评审工作不会是高质量的。
其次,我们需要减少对评审和领域主席(AC)在高度不确定情况下进行推理决策的需求。这无法完全避免,但可以通过以下方式进行改进。
更优的评审人员匹配
:评审者在面对不是自己专长领域的论文时,更有可能使用启发式方法。因此好的匹配应该考虑任务和方法。由于肯定存在不完美匹配的情况,这时配备具备互补专业知识的多位评审就成为次优选择。
更细粒度的 track
:AC 不应当对不同类型的论文进行决策。如果会议接收 survey、opinion、资源和分析论文等,则这些类型的论文应有各自的接收率和最佳论文奖项。
为不同论文类型设置专门的评审格式
:用新颖性去评判可复现性报告或用 SOTA 结果评判资源论文都是不合理的。COLING 2018 提出考虑论文贡献类型的评审格式。
论文提交前宣布会议优先关注的内容
:特定会议的主要关注点是什么,SOTA 工程结果、方法的多样性,还是新的 idea?哪些因素对论文接收与否影响比较大?清晰地说明这些问题有助于作者为自己的研究选择合适的会议,也有助于评审和领域主席在论文推荐中更加一致。
不要求评审提交整体推荐分数
:这是相似的论文在不同评审那里排名随机的理由,评审人员可能对很多问题存在不一致意见。即使有明确的策略也于事无补。解决方案在于,评审应仅提交特定项的分数(原创性、技术完善性等),而这是决定论文接收与否的基础。
现在,读者可能会和这篇论文的匿名评审一样失望,觉得没提出什么新鲜玩意儿。而这正是这个问题的难点:我们不缺概念创新,我们缺少的是实现。作为研究者,我们倾向于仅重视概念创新。
从组织角度,每一届 ACL 会议都由一组新的人组织,他们会设立自己的政策。这种多样性是件好事,但很多事情被同时改变,没有系统化的对比,甚至显著的成功创新也未必能留存。后果就是,下一年我们仍然不知道哪些政策有效、哪些无用。我们一直在不停地实验,但却从不检查结果。
从社区角度来看,我们没有对社交媒体上的同行评审讨论进行任何定量研究,而只是作为 Twitter #NLProc 社区的积极成员,在 rebuttal 和通知论文接收结果时看到同行评审话题的火爆(如图 3 所示)。同时,还有一些苦涩的抱怨和改革建议,但是却没有真正的行动(这也使得下一次会议时同样的事情循环出现)。
![]()
归根结底,同行评审是一个标注问题,我们可以尝试解决它,因为我们对实验方法论、标注者间信度和偏差了解甚多。然而,我们在以下方面失败了:
组织者:缺乏测试一个策略优于另一个的机制,无法确保成功的策略能够留存;
作者:缺乏积极监督策略变化的意愿,缺少要求报告、获取评审数据以进行独立分析的能力;
评审:缺乏将元研究看作 NLP 有效部分的意识,使得发表元研究论文很难。在某种程度上,NLP 同行评审…… 阻止了对 NLP 同行评审的研究。
论文链接:https://arxiv.org/pdf/2010.03863v1.pdf
10月19日,第一讲:音频基础与声纹识别。谷歌资深软件工程师、声纹识别与语言识别团队负责人王泉老师将介绍声纹识别技术相关基础知识,包括发展历程、听觉感知和音频处理相关基本概念与方法、声纹领域最核心的应用声纹识别等。
添加机器之心小助手(syncedai5),备注「声纹」,进群一起看直播。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com