[CIKM 2017] DeepRank: 模拟人类标注过程,构建排序深度模型
2017年11月8日,在新加坡举行的ACM CIKM 2017 会议上,中科院计算所网络数据科学与技术重点实验室程学旗老师团队的博士生庞亮(导师:李国杰院士和兰艳艳副研究员)发表了题为“DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval”(作者:庞亮,兰艳艳,郭嘉丰,徐君,许静芳,程学旗)的论文并作了大会报告。本届CIKM会议共收到稿件1450篇(其中长文投稿855篇),长文录用171篇(录用率20%)。

现今网络环境中存在着海量的文档数据,用户通过查询项对大量文档进行相关性排序从而获取相关的文档信息。现有基于特征融合的Learning to Rank算法,很大程度依赖于人工特征,而人工特征的设计不仅仅耗时,而且很难在数据变化的时候自适应调节。仅从文档的文本内容出发的深度学习文本匹配模型,由于缺乏对检索场景特性的建模,效果一直不如现有的Learning to Rank 模型。基于以上观察,我们提出了端到端的相关性排序深度学习模型DeepRank。DeepRank网络结构的设计重点考虑了查询词重要度、文档语义匹配信息、匹配信号空间关系、文档多样性等,符合检索场景的特征。
DeepRank模型启发自人工标注相关文档的过程。给定查询项(Query)和文档(Document),人们判断相关性的过程通常分为三个步骤:1.在冗长的文档中定位并摘取和查询项相关的文档片段;2.针对每一个文档片段进行相关性评估;3.将所有的局部相关性聚合得到全局的相关性,从而得到查询项和文档的相关度。

图1人类对相关文档评估的过程
基于这样一个过程,我们设计的DeepRank模型主要也分为三个模块,相关区域检测策略、局部相关性度量网络和全局相关性聚合网络。根据人工标注过程的理解与眼球跟踪实验的结论,我们发现人们在判断文档相关性的时候重点会关注关键词匹配为中心的一个窗口内的文本,所以我们定义相关区域为以查询项关键词为中心的一个文本片段。得到的文本片段数量相对于整个文档而言已经大大精简,不仅减少了计算量,也很好的过滤了长文档中的噪声影响。在这些得到的文档片段之上,我们采用深度文本匹配的模型(MatchPyramid和MatchSRNN),建模查询项和文档片段之间的相关性,我们成为局部相关性度量。为了得到全局相关性的分数,需要经过两个步骤的局部相关性的聚合。第一是在查询项关键词级别的聚合,聚合采用时序相关的循环神经网络,旨在建模不同片段出现的先后顺序和重要程度的累计。第二是在全局的相关度聚合,聚合采用门控神经网络,旨在确定各个查询项关键词的重要度。
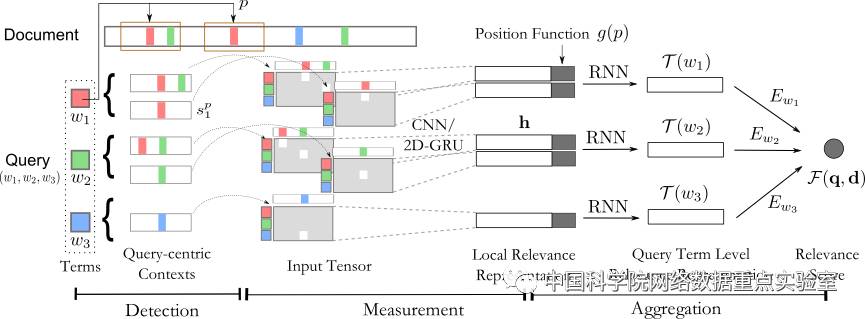
图2 DeepRank模型图
我们工作的意义在于,首次提出了基于深度学习的模型DeepRank,仅仅利用原始的文本信息就能达到并超过使用大量人工定义特征的Learning to Rank模型;启发自人类标注过程,能够更自然地捕获相关性排序任务的特性。
详细请参考具体的论文:
Liang Pang, Yanyan Lan, Jiafeng Guo, Jun Xu, Jingfang Xu, Xueqi Cheng. DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval. In Proceedings of ACM CIKM’17 Conference, Pan Pacific Singapore, Nov 2017.





