MICCAI 2020 | 腾讯开源大规模X光预训练模型及代码
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:Deep Learning Engine
论文导读
“ 预训练模型能够加速任务模型收敛速度和提升模型性能。自然场景图像有ImageNet预训练模型,但此类数据和医学图像差异较大。因此腾讯提出了一个基于70万X光数据进行训练的模型,以作为该领域的预训练模型。模型及训练代码已开源!”
论文地址:
https://arxiv.org/abs/2007.07423
代码地址:
https://github.com/funnyzhou/C2L_MICCAI2020



摘 要
Abstract
01
—
Introduction

ImageNet预训练模型通过迁移学习应用到2D医学图像分析中已被证实是有效的。大量的实验证明,预训练模型与从头开始训练相比,模型能够快速收敛并且能获得更好的准确率。这样的结果主要归因于两个因素:高效的深度神经网络算法以及从大量自然场景图像中学得的通用特征表达。但显而易见的问题是医学图像和自然场景图像是具有显著差异的。那么能否通过某种方法训练一个基于医学数据的预训练模型?
众所周知,医学数据需要该领域专业医师进行标注。这类高质量,多数量的标注数据能够直接提升模型的性能。但医学数据往往因为涉及病人隐私等原因而受到管控和限制,无法获取到大量的带医生诊断结论的数据。那么,开发一种不带标注数据的方法在医学领域就显得尤为重要。一些利用未标注数据进行自监督学习的模型也取得了不错的性能表现,但还无法超过在ImageNet上进行预训练的模型。
通过上述分析,作者提出了一种全新的自监督预训练方法C2L(Compare to Learn)。此方法旨在利用大量的未标注的X光图像预训练一个2D深度学习模型,使得模型能够在有监督信息的条件下,通过对比不同图像特征的差异,提取通用的图像表达。与利用图像修复等代理任务方法不同的是,作者提出的方法是一种自定义特征表达相似性度量。文中重点关注图像特征级别的对比,通过混合每个批次的图像和特征,提出了结构同质性和异质性的数据配对方法。设计了一种基于动量的“老师-学生”(teacher-student architecture)对比学习网络结构。“老师”网络和“学生”网络共享同一个网络结构,但是更新方式不同,其伪代码如下。


02
—
Proposed Method
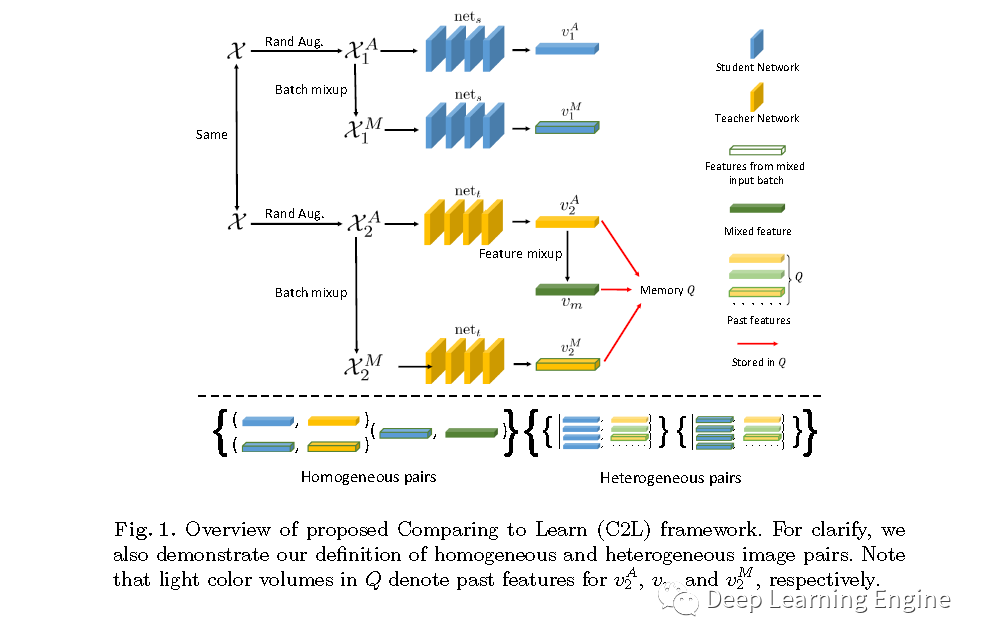
Feature Comparison, Memory Q and Loss Function:如伪代码如所示,C2L模型优化最小化同质数据对之间的距离,最大化异质数据之间的距离。
03
—
DATASETS & Results
预训练:ImageNet 预训练使用了约一百万带标注的数据。本文作者使用了
ChestXray14,MIMIC-CXR,CheXpert和MURA四种不带标签的约70万数据进行无监督预训练。只用了ChestX-ray14 进行消融实验以选择合适的超参数。
实现细节以及消融实验:由于已开源,这里就不展开细说。
首先看看Mix方法做的实验结果,发现Batch mixing 和Feature mixing提升明显。
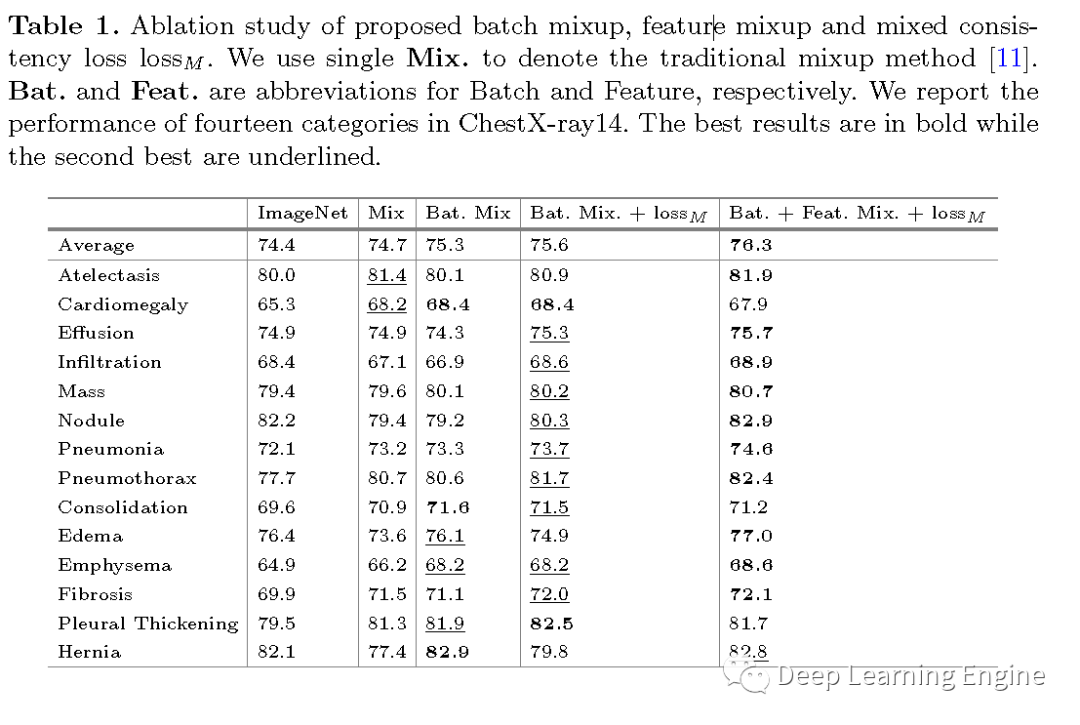
对比数据增强策略和记忆队列Q保存特征长度对性能的影响。

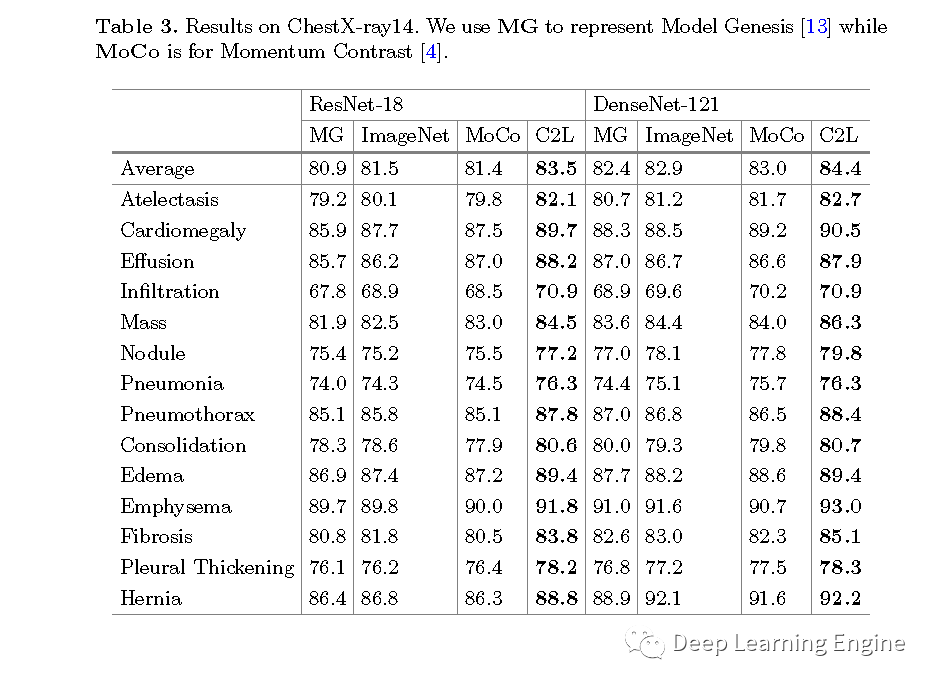
ChestX-ray14数据集上性能的对比。C2L模型性能提升显著。
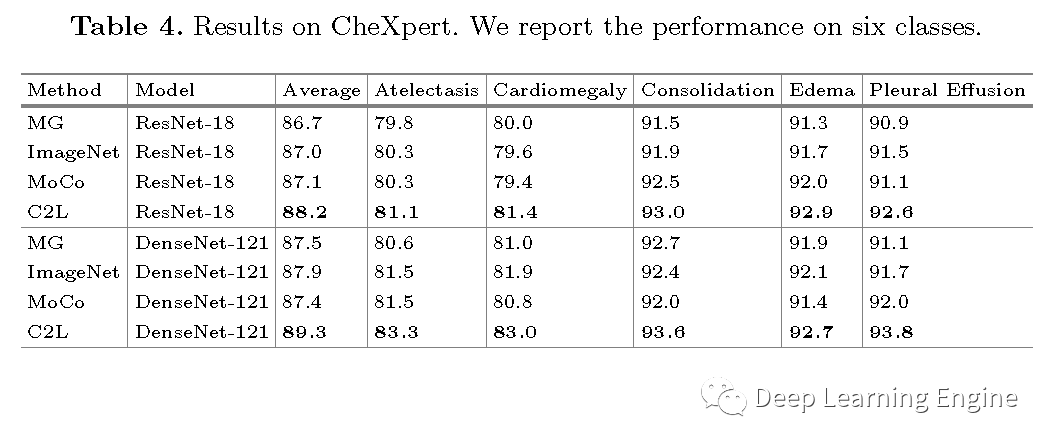
CheXpert数据集中,预训练模型及MG等性能的对比,C2L约有1%的提升。
Kaggl肺炎数据集不同阈值下mAP,C2L也有不错的表现。

04
—
Conclusion
作者提出了一种自监督学习方法C2L,利用次方法从无标签医学数据中提取这类数据的特征表达。这种方法通过利用数据间的相关性作为监督信息而无需额外人工标注数据。
05
—
结语
重磅!CVer-医疗影像交流群成立
扫码添加CVer助手,可申请加入CVer-医疗影像 微信交流群,目前已满1500人。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如医疗影像+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



