关系重叠?实体嵌套?曝光偏差?这个模型统统都搞得定!

©PaperWeekly · 作者|王雨城
学校|中国科学院信息工程研究所硕士
研究方向|自然语言处理

背景
{
'text': '《邪少兵王》是冰火未央写的
网络小说连载于旗峰天下',
'relation_list': [
{
'subject': '邪少兵王',
'object': '冰火未央',
'predicate': '作者'
},
]
}
pipeline 的方法一般先做实体识别,再对实体对进行关系分类。这类方法忽略了实体与关系之间的联系,而且存在误差累积的问题。
|
|
文本 |
关系 |
|
单实体重叠 |
周星驰主演了《喜剧之王》和《大话西游》。 |
(周星驰,演员,喜剧之王)(周星驰,演员,大话西游) |
|
实体对重叠 |
由周星驰导演并主演的《功夫》于近期上映。 |
(周星驰,演员,功夫)(周星驰,导演,功夫) |
后来提出的一些方法已经可以解决重叠问题,如 CopyRE [1]、CopyMTL [2]、CasRel(HBT)[3]等,但它们在训练和推理阶段存在曝光偏差。即在训练阶段,使用了 golden truth 作为已知信息对训练过程进行引导,而在推理阶段只能依赖于预测结果。这导致中间步骤的输入信息来源于两个不同的分布,对性能有一定的影响。
虽然这些方法都是在一个模型中对实体和关系进行了联合抽取,但从某种意义上它们“退化”成了“pipeline”的方法,即在解码阶段需要分多步进行。这也是它们存在曝光偏差的本质原因。
本文提出了一种新的实体关系联合抽取标注方案,可在一个模型中实现真正意义上的单阶段联合抽取,不存在曝光偏差,保证训练和测试的一致性。并且同时可解决多关系重叠和多关系实体嵌套的问题。


Idea的由来
说了那么多,终于要进入正题了。我最初的 idea 是为了解决一个比较极端的情况,曝光偏差的问题其实是“顺便”解决的。在许多关系抽取的比赛数据集中,我发现部分关系的实体存在嵌套,请看以下两个例子:
|
|
文本 |
关系 |
|
关系内嵌套 |
周星驰主演了《喜剧之王》和《大话西游》。 |
(哈尔滨工业大学,位于,哈尔滨) |
|
关系间嵌套 |
由周星驰导演并主演的《功夫》于近期上映。 |
(北京市,包含,通州)(北京市政府,位于,通州) |
虽然当前已经有很多方法可以专门用于识别嵌套实体,但是把它们直接融合到关系抽取中也并不是那么容易。即使可以,多少显得有点笨重。于是,我开始思考如何能够用一个简单直接的方法识别嵌套实体,并与关系抽取任务优雅融合。
疫情期间,我每天苦思冥想,瞠目抖腿,抓耳挠腮,摇头晃脑,鬼哭狼嚎,差点以头抢地。最后,一拍大腿,嗨,不就是头和尾的区别。只要一个实体的头部 token 和尾部 token 被唯一确定,那它就可以与外部或者内部的其他实体区别开。那么如何确定头尾呢?我们要的不是多个标签,而是一个标签,因为多个标签难免要遇到配对的问题。那么,答案呼之欲出了,就是矩阵。矩阵中的一个点可以确定一对 token。一句话的所有嵌套实体都可以在一个矩阵中被一个点唯一标注,如下图所示:
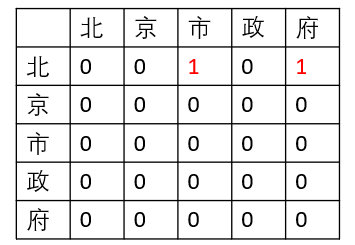
▲ 嵌套实体标注示例
纵轴为头,横轴为尾,图中的两个红色 1 标签分别标注了(北,市)和(北,府),代表“北京市”和“北京市政府”为两个实体。
实体解决了,那么关系怎么办呢?那是一个下午,落日的余光洒在地板上显得格外刺眼,我看了一眼客厅的沙发,忽然想起了那天夕阳下的思考。一拍脑袋,邻接矩阵不就是用来表示节点关系的吗?实体关系可不可以也用两个 token 的关系来表示呢?答案又呼之欲出了。对,那就是 subject 和 object 的头部 token 以及尾部 token。例如:(周星驰,演员,喜剧之王)-> (周,演员,喜),(驰,演员,王)。
有些同学可能会疑惑为什么还要标尾部 token,头部 token 对的关系不就已经足够表达关系了吗?那是因为如果不确定尾部边界,仍然无缝解决嵌套问题。如前文例子中的“北京市”和“北京市政府”就是共享头部 token 的嵌套实体。
有些小伙伴可能已经看出来了,我们不知不觉就把 subject 和 object 在同一解码阶段确定了下来。于是,曝光偏差就不存在了。

标注方案
具体的标注方案如下图所示:
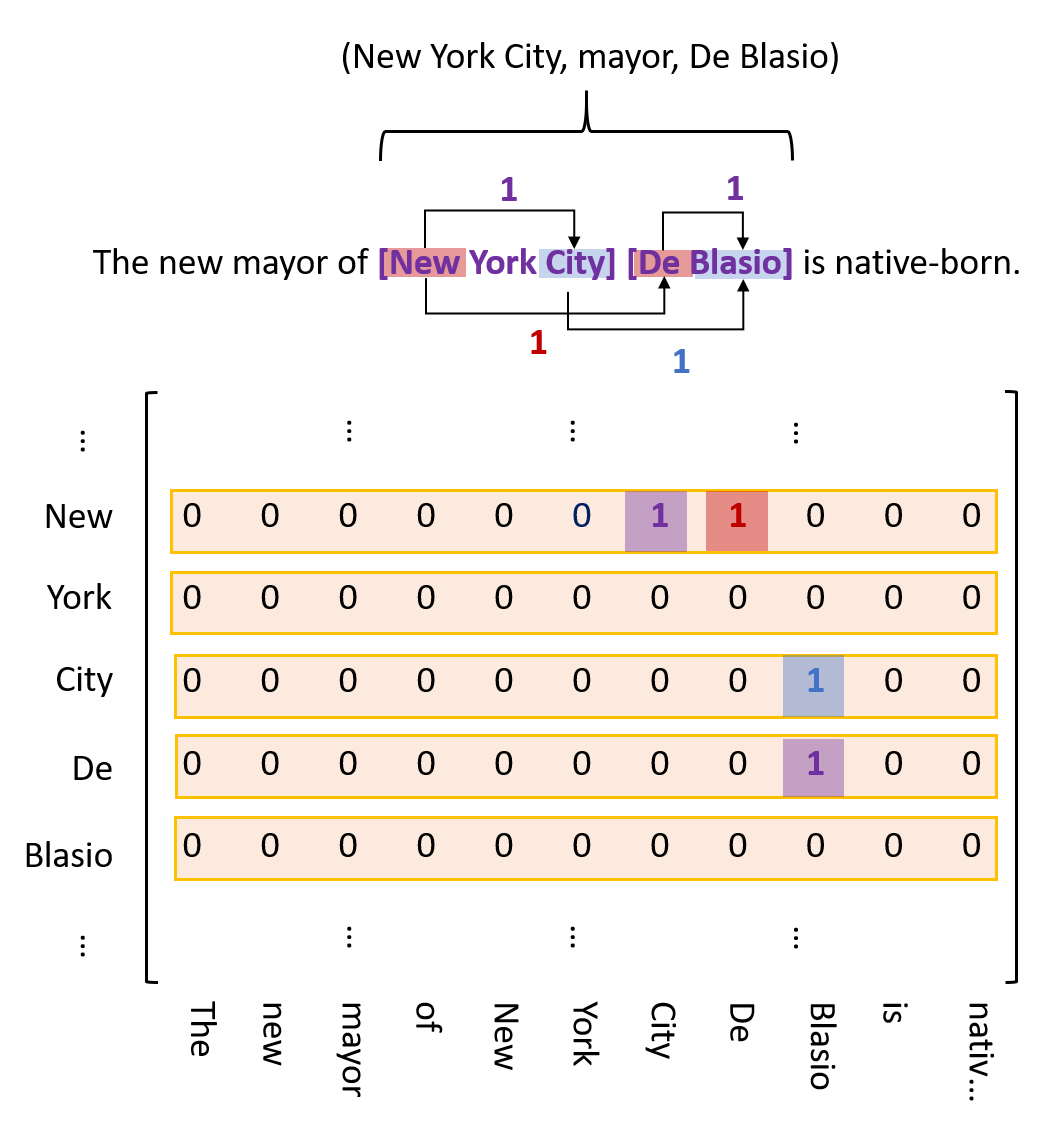
▲ 初始标注方案示例
其中紫色标签代表实体的头尾关系,红色标签代表 subject 和 object 的头部关系,蓝色标签代表 subject 和 object 的尾部关系。至于为什么用颜色区分,是因为这三种关系可能重叠,所以三种标签是存在于不同矩阵的,这里为了便于阐述,才放在一起。
因为实体尾部不可能出现在头部之前,所以紫色标签是不可能出现在下三角区的,那么这样标就有点浪费资源。能不能不要下三角区?但要注意到,红标和蓝标是会出现在下面的。所以我们把红蓝标映射到上三角区对应位置,并标记为 2,然后弃了下三角区,如下图:
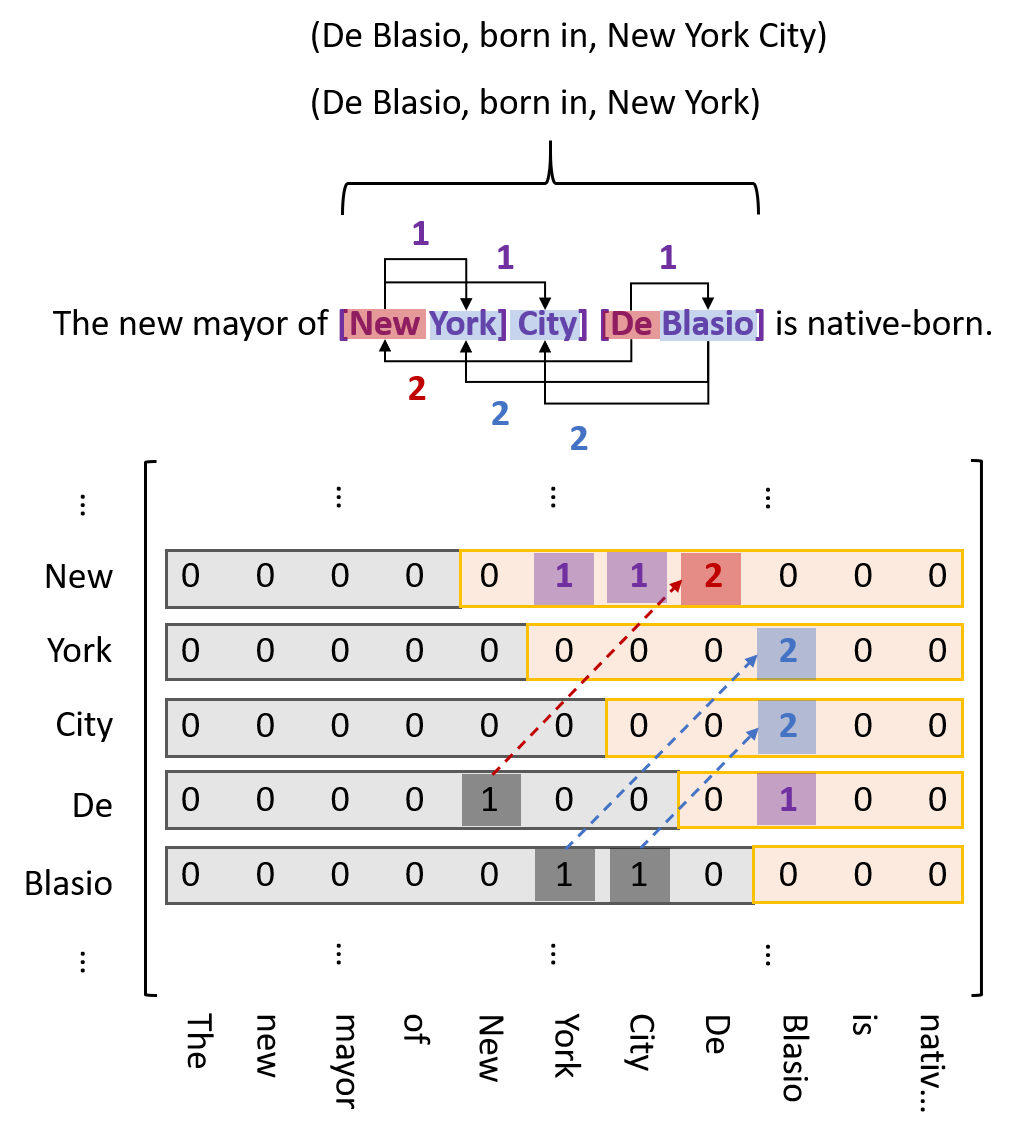
▲ 最终标注方案示例

模型
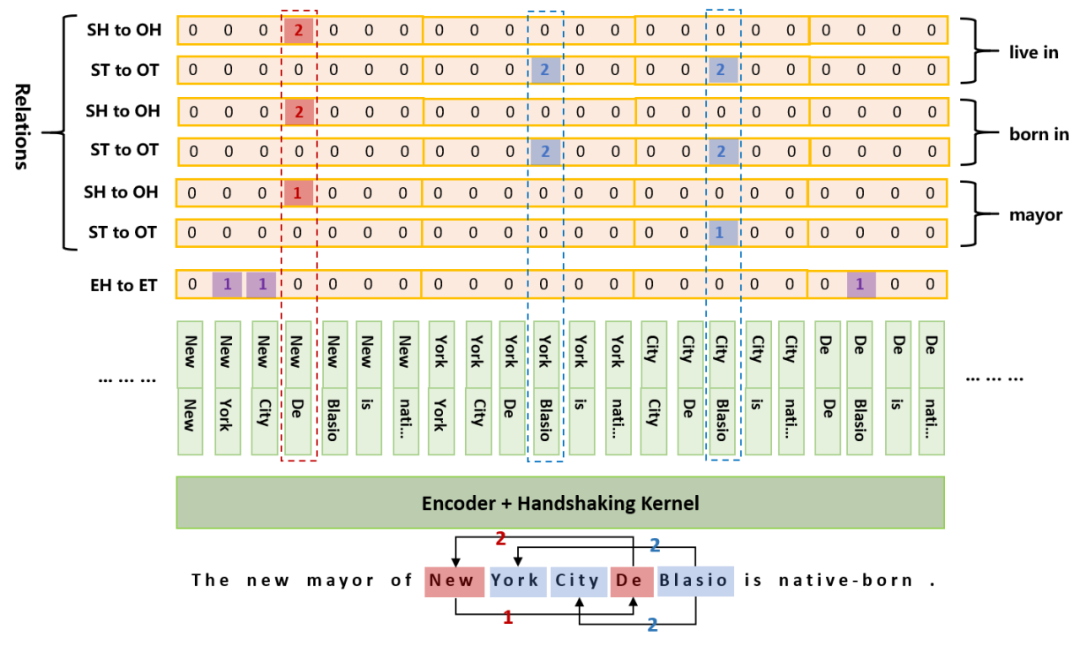
(New York, mayor, De Blasio),
(De Blasio, born in, New York),
(De Blasio, born in, New York City),
(De Blasio, live in, New York),
(De Blasio, live in, New York City)

实验结果
截止到论文被接收,该模型在 NYT 和 WebNLG 两个关系抽取任务上都达到了当时的 SOTA 性能。
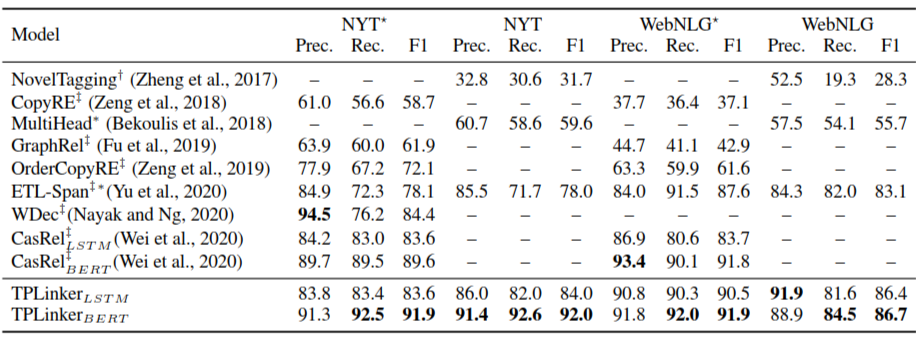
▲ exp_res1

未来的工作
这里主要提一下值得改进的地方:
-
论文中 token 对的向量表示采用的是直接拼接,这种简单的方式可能并不能展现出最佳的性能。 -
实体和关系的识别使用的都是相同的向量表达,这可能会相互干扰。[4] 最新的两篇相关论文也指出了使用不同的特征去分别解决两个任务可能对性能有提升: A Frustratingly Easy Approach [4] , Two are Better than One [5] 。 -
模型将原本长度为 N 的序列扩展成了O(N2)的序列,这无疑增加了开销,使得处理长文本变得比较昂贵。另外,矩阵的稀疏性和标签的极度不平衡对性能有一定的影响。

参考文献
[1] Extracting relational facts by an end-to-end neural model with copy mechanism: https://www.aclweb.org/anthology/P18-1047
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





