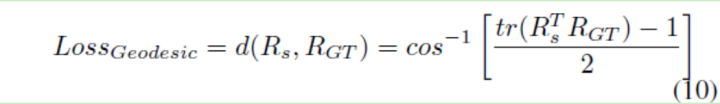加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:https://zhuanlan.zhihu.com/p/92032320
本文来自知乎专栏,仅供学习参考使用,著作权归作者所有。
如有侵权,请私信删除。
这里笔者尝试解读一篇2019年预发表的《Deep Learning in Medical Image Registration: A Survey》论文综述,在这篇综述中,原作者对当前深度学习在医学影像配准中的各个研究方向做了比较系统全面的总结概括,既有纵向的近十多年来研究趋势的总结,也是横向的各个研究方向的对比。尽管可能存在解读不够深入,文献选择不够典型等问题,但对于刚入坑的萌新来说,应该算是一篇不错的入门论文。
PS:笔者是个研究医学影像配准不到一年的渣硕,此篇博文原是个人的科研笔记,在此发布一方面是希望能抛出一些个人见解以供与同行探讨,一方面是希望能对刚刚进入这个领域的萌新有所帮助,能够通过此篇博文对当前深度学习在医学影像配准中的研究情况有个较为系统的粗略的认知。
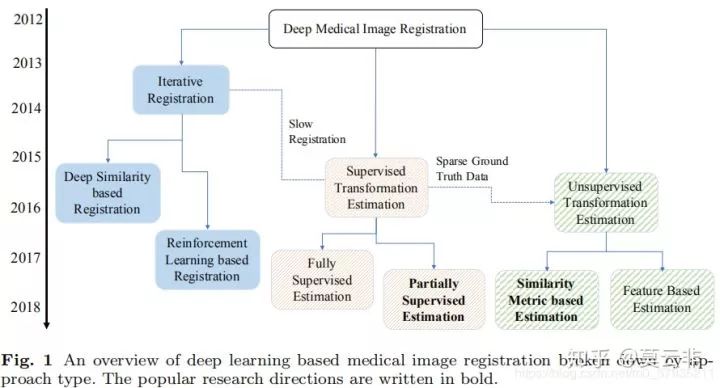
一、研究情况梗概
目前采用深度学习进行医学影像配准的方法大致可以分为三类:
深度迭代配准的方法。不断迭代优化相似性测度来实现配准。具体可以分为两种:传统配准方法的拓展,通常是采用深度学习方法提取特征描述子,再用传统方法迭代优化目标函数;另一种是采用深度强化学习。
采用监督学习或部分监督实现一步配准。监督学习的话金标准的制作是个较大的问题。因此目前部分监督是研究热点。
采用非监督学习实现一步配准。非监督一块目前基于相似性测度进行自监督学习是研究热点。但对于多模态配准问题,相似性测度的选择是一大挑战。
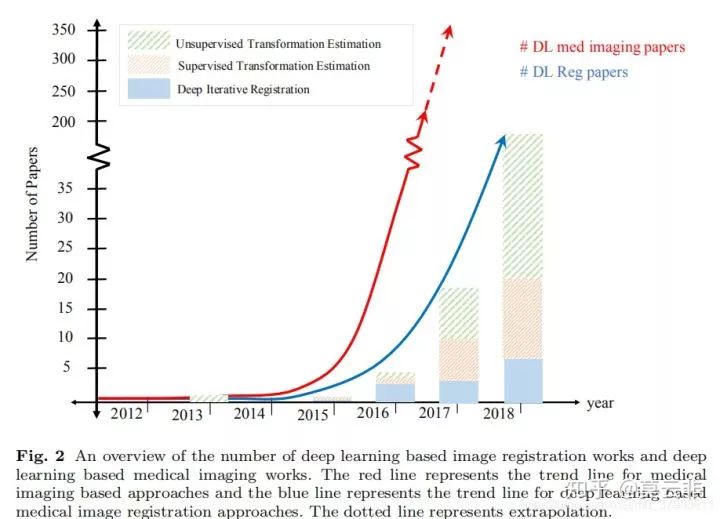
差不多2016年才渐渐出现采用深度学习进行配准的论文。早期的研究也以深度迭代学习的方法居多。由于对配准速度的需求,基于深度学习进行一步配准的方法开始出现,比如采用类似Unet的网络来学习形变场。这种方法需要真实的形变场作为金标准,而真实形变场很难得到,因此刺激了非监督学习方法的出现。该种方法面对的一大挑战是相似性测度的选择。最近的很多研究都是为了解决这一问题,比如采用基于信息论的相似性测度,比如弱监督方法,比如GAN的应用。
卷积神经网络。最常见,最普遍。
循环神经网络。目前的研究较少,文章中列举的上百篇参考文献中不超过5篇。但当前采用循环神经网络用于关键点检测的论文频繁出现,对配准可能有一定启发。
强化学习。已有的研究都是深度迭代学习的。差点跳过的坑不敢再跳了,这部分略过。
生成对抗网络。目前已有一定数量的论文出现,可能是下一步的研究热点。(2019.11.15原作者说中了,最近用GAN做配准的貌似不少)
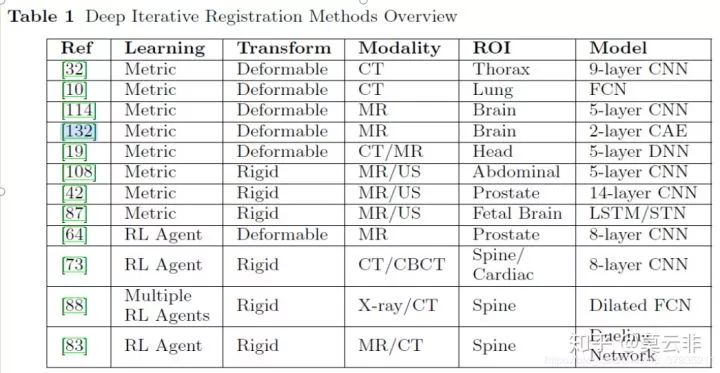
二、深度迭代学习
这是最早的将深度学习应用于医学图像配准的研究。基本的配准思想还是传统的那些,只是在传统方法中嵌入了神经网络用来提取特征,或者学习相似性测度等。与其他两种方法的最直观的区别在于这种方法每配准一对图像都要迭代优化去寻找最优解。
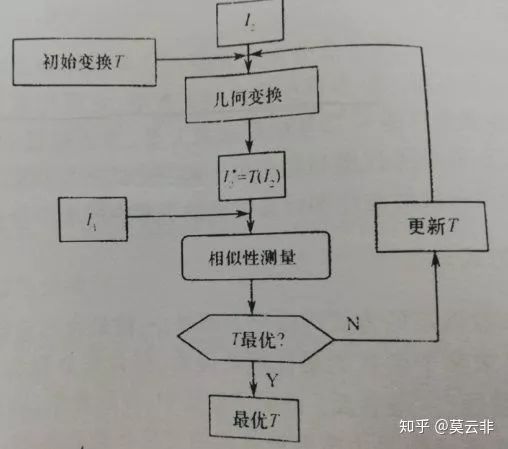
2.2. 传统的配准方法简介
(原论文没有,为了理解这部分内容笔者自行加入的部分)
I1,I2是待配准两副图像提取特征后得到的特征空间,也可以将原图所有像素作为特征空间,此时的I1,I2就是待配准的两张图像;我们选择一个合适的变换模型(比如仿射变换),将I2变换后得到I2*,选择合适的相似性测度计算I2*和I1的相似度,我们希望这个相似度越小越好,因此需要采用一种优化策略(或者说优化算法)来迭代优化目标函数相似度,找到合适的几何变换参数使得相似度最小。一些人工设计的相似性测度经常被使用,比如平方和误差(SSD),互相关函数(CC),互信息(MI),标准互相关函数(NCC),标准互信息(NMI)。
基于体素的 上图的I1,I2替换为就是原图。难点在于相似性测度的设计。
基于特征点的。具体做法是提取特征,匹配特征,通过拟合或插值算法得到形变场。这种做法往往不涉及相似性测度,但特征的选择和匹配是难点。
2.3. 相关典型论文简述
2.3.1. 用深度学习做特征学习
(最早的文献的做法([1,2]))
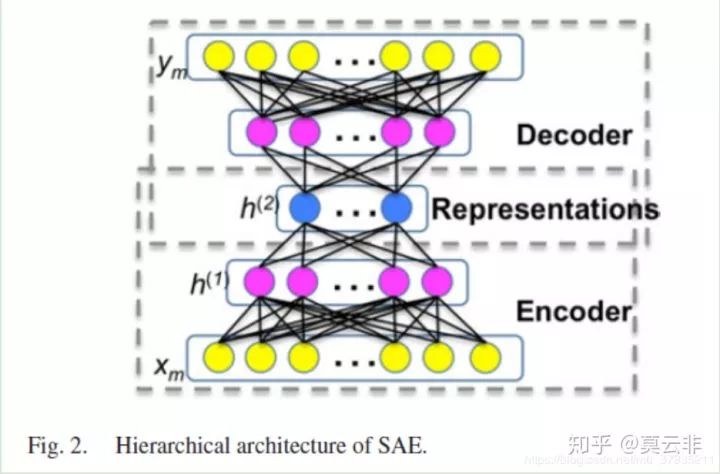
这篇论文提出了一种非监督的特征提取方法用于配准任务(也就是在传统方法的特征提取部分用深度学习来做,其他不变)。它的想法是采用stack autoencode(SAE)网络来非监督学习特征,从而得到泛化能力更强更具有特征性的特征。
这种特征学习方法可以不仅可以融入到传统的基于特征点的配准方法中,也可以融入基于灰度的配准方法中。下面看一下融入HARMMER算法(基于特征点类型)的具体做法。
上图是SAE网络,蓝色的部分就是我们想要的特征向量。我们训练该网络希望该网络的输出ym与网络输入xm尽量相似。
首先是选择大量的关键点得到patch块来训练这个SAE网络。
然后就是配准两张图像:选择关键点,提取特征向量得到特征描述子(通过SAE网络的encoder来做)并匹配关键点,插值得到密集形变场,重复直到所有点都曾被选为关键点。
总而言之,该种做法的本质依然是传统的基于迭代优化的配准方法,只是不再采用传统的特征描述子,而是使用深度学习的做法来学习每个关键点的特征描述子来指导关键点的匹配。然而,最近有研究表明,在单模态的情况,深度学习学到的特征描述子并不一定比手工设计的特征描述子效果好,通常两者的结合能取得更好的效果,因为往往前者可以是后者的一个信息补充。
刚刚提到的最早的那篇论文是用深度学习来学习特征描述子。关键点的匹配,形变模型的插值等方法依然是传统的方法。
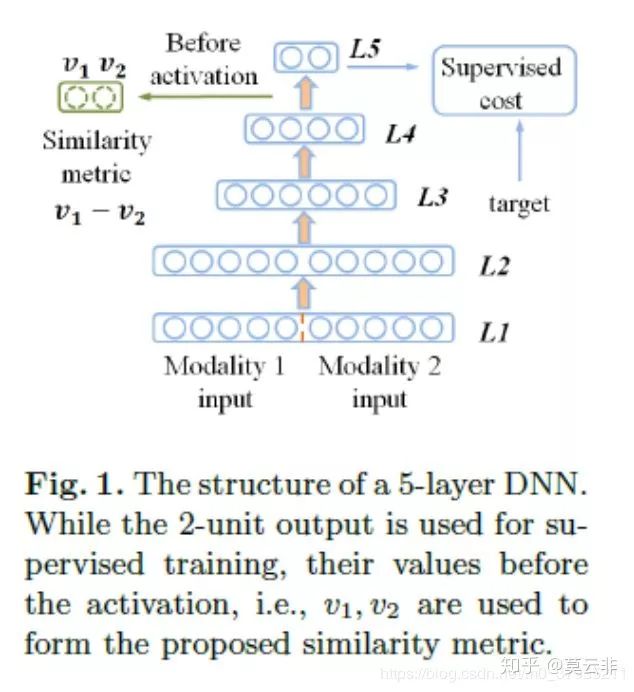
还有一个研究方向是用深度学习来学习两个patch块的相似性测度从而衡量两个patch对应的特征点是否匹配。该种方法的思路是训练一个二分类的分类器来衡量两个点的匹配程度。可以看下图,输入两个patch块拉长的向量的串联,输出01或10代表匹配或者不匹配。通过这种监督学习的方式来实现相似性测度的学习。多用于多模态图像的配准。
三、带监督的形变场估计
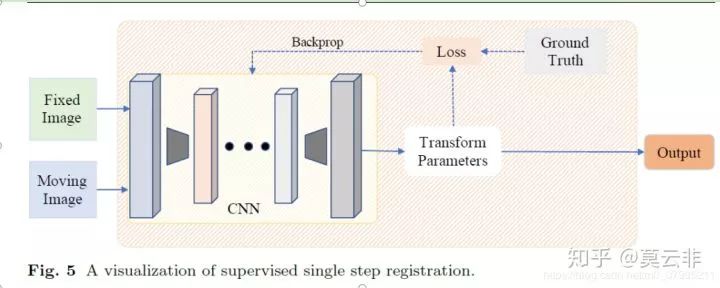
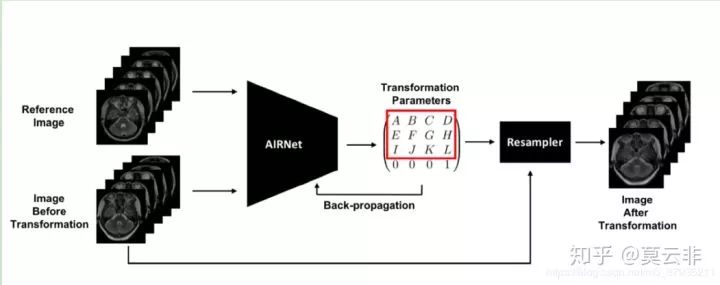
迭代学习的一大缺点就是速度很慢,无法满足实时配准的需求。因此通过神经网络直接估计形变场的方法开始出现。可以看下面这张图。
这种做法就是直接通过一个神经网络来回归变换参数(可以是变换矩阵的参数,也可以是一个形变场),相应的金标准就是真实的变换参数,可以通过手工配准得到,也可以通过其他配准方法得到。这种方法的弊端主要在于金标准不好做。
3.2.1. 刚性配准
(2016年最早的论文之一[5,6])
思路:从局部图像残差特征中去回归刚性变换矩阵的变换参数。
然后通过一个CNN回归出仿射矩阵的参数残差(公式6)
需要说明的是,想要从配准的图像中直接回归中变换参数是很艰难的,作者为了简化这一问题采用了很多策略。如局部网络残差的计算,参数空间的划分。
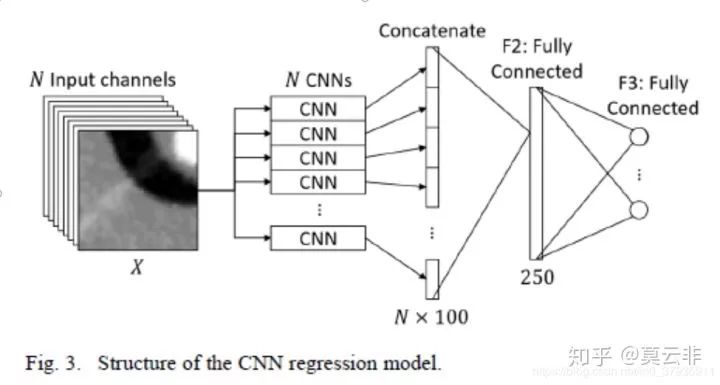
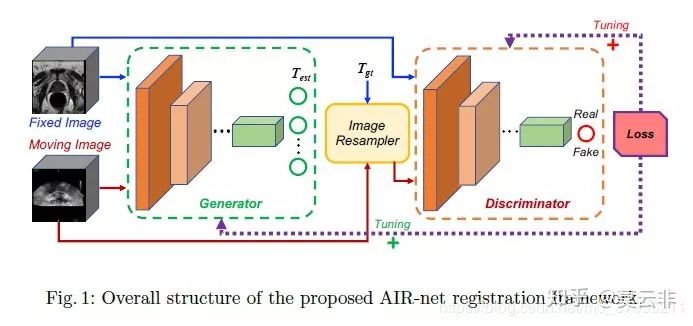
这篇论文是2018年上arxiv预发表的论文,至今尚未发表。配准方法是利用一个回归网络直接从原图中回归出仿射矩阵的12个参数(三维图像配准)。目标函数就是这12个参数与金标准的MSE。
这是目前更为常见的做法
。
由于从现有的待配准的图像对中难以得到金标准,所以作者采用了自己生成的数据作为训练数据。
我认为这篇论文比较有参考价值的有两点
。
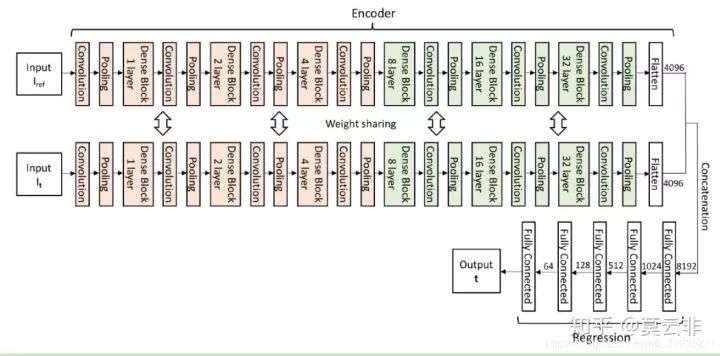
它的网络分为编码网络和回归网络两部分。编码网络采用了DenseNet的模块来搭建,并采用了权值共享的方法来获得参考图像与浮动图像匹配的特征,同时减少参数数量。我们可以看到它的编码网络网络深度还挺深的,有70层(输入图像30*320*320),作者并没有提到如何选择网络的深度,但我个人认为可能是较浅的网络无法提取出复杂的特征用于回归。另外,这个回归网络层数也较深,一层一层神经元数量逐步减少,最终回归出12个参数,而不是从8192个神经元直接回归出12个。
对于配准问题数据量不够是个很让人头痛的问题。而现在很常见的一种数据增强方法就是自己生成待配准的数据。本文就是随机生成仿射变换矩阵,根据这个由参考图形生成浮动图像,变换矩阵就是金标准。
3.2.3. 刚性配准的一篇2018TMI论文
[8]
这篇论文同样采用CNN回归出刚性配准的参数。亮点在于geodesic loss的应用。我们现在看一下它的方法,再说这个loss。
输入图片,提取特征,然后根据特征回归出变换参数。目前我看到的刚性配准的论文大多都是这个思路。
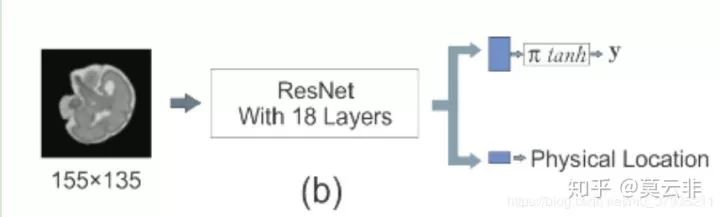
上图是二维切片做三维姿态估计的网络架构。
作者尝试了VGG16,ResNet18,DenseNet,发现ResNet18效果最好。
回归部分分为两个部分,上面的支路回归出三维旋转变换的3个参数,其中pi tanh是用来限制旋转参数范围在[-pi,pi]。下面的支路回归出一个标量,代表位置。Loss采用的MSE。
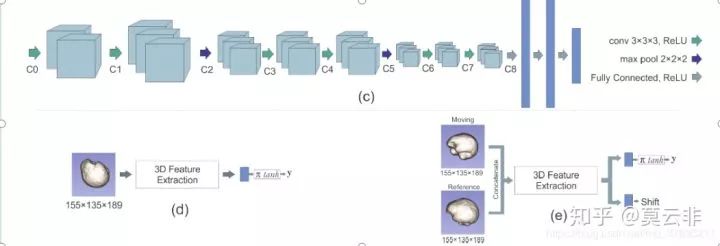
上图是三维图像块做姿态估计的网络架构。分为两步,第一步是估计出三维图像块的旋转角度(相对canonical坐标系),可视为粗配准,loss采用的常见的MSE。第二步是精细配准,将上一步得到的粗配准后的图像和参考图像输入网络,得到最终的变换参数(3个旋转参数,3个平移参数)。平移参数的loss依然是MSE,旋转参数的是geodesic loss。由于这篇论文的任务是姿态估计,并不是任意两张图像的配准,所以网络的输入一般是单幅图像,这里第二步输入了参考图像,这里的参考图像是通过梯度中心匹配算法计算出来的。
论文的核心创新点就在于geodesic loss的应用。作者说MSE是一个凸函数,能很好地收缩学习过程中的搜索空间,解决常见的陷入局部最优问题。但是MSE并不能准确地表示两个旋转矢量之间的距离,所以为了提高准确度,作者采用了测地距离,也就是单位球面上两个点之间的最短距离。
监督学习的方法问题在于配准的质量对金标准的依赖大,而金标准的质量又依赖于制作者的专业程度;此外金标准的获取也是一个难题,尽管可以通过自己生成训练数据来解决这些问题,但是如何保证生成的数据和临床数据足够相似也是一个问题。
目前这一研究方向的创新点主要在以下部分(个人总结):
输入如[89,90,143]先提取了局部特征再输入网络进行进一步的特征提取和回归。这样做能够降低网络设计和训练的难度,但不是端到端的学习,局部特征提取方法通常采用传统的算法,相对繁琐。个人认为并不是目前主流的研究方向。
网络架构 目前看到的网络架构通常都是借用的分类或者分割的网络,常见的就是FCN还有ResNet,也有很多是自己搭建的简单的网络序列,除了STN(Spatial Transformer Networks )和微分同胚系列论文,目前尚没有看到较为新颖的网络模块的设计。较多的创新还是集中在配准思路的设计上,比如把配准分为两步,训练一个网络进行粗配准,另一个网络进行精细配准。(可能是我目前阅读的论文量还比较少,见识浅薄)
目标函数 监督学习部分目标函数多是MSE。
四、非监督
非监督学习的方法一种是基于图像相似性测度的,一种是基于特征学习的(特征学习的没细看,跳过)。
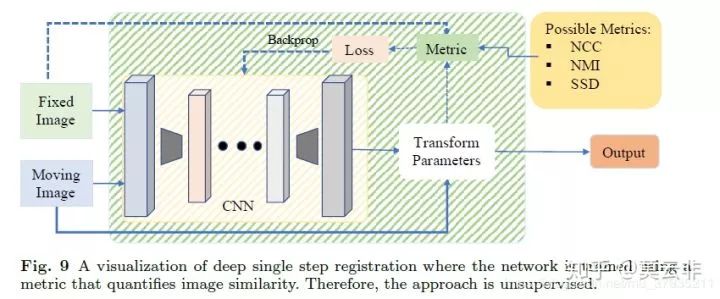
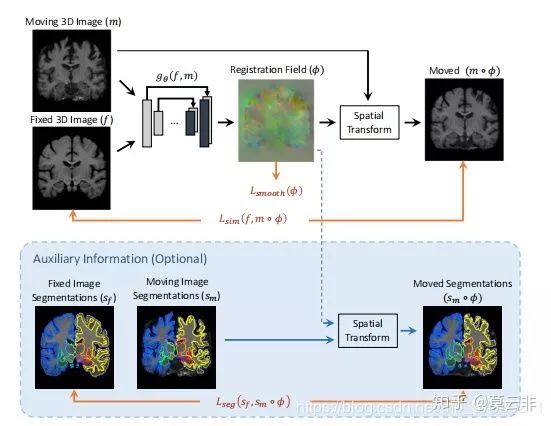
惯常的做法是通过FCN全卷积网络生成形变场,再通过STN(Spatial transformer networks)得到扭曲后的图像,目标函数为扭曲后图像与固定图像的灰度相似性测度和形变场的正则项。
目前我看到的使用最广泛的网络框架是Voxelmorph。这个框架是麻省理工的研究团队提出的,在CVPR,Micca,TMI相继发表了多篇论文。
配准思路可以看下图。和上面叙述得差不多,创新的部分一是把弱监督给结合了起来,二是融入了微分同胚机制从而自己设计了一个神经网络,开启了深度学习配准领域又一热点高端研究方向。
基于灰度相似性测度的非监督学习这块的论文很多,但方法大同小异,创新点也多在于监督信息上面比如输入更多的特征用于指导训练,比如从网络引出更多的信息添加到loss中,目前这个研究方面我认为比较大的突破可能是GAN的应用。
所以下面重点来看一下用GAN是如何来进行非监督学习的配准的。以范敬凡老师发表在MICCA2018上的论文为例[9]。
生成器输入的是待配准的图像对的patch,输出的是局部形变场以及扭曲后的图像;判别器判别的就是扭曲后图像与参考图像,我认为关键就在与参考图像的设计,这里的参考图像设计的是固定图像与浮动图像的加权求和,训练初期固定图像的权重为0.8,后期为0.9。
总结一下,该方法的思想就是用判别器来代替传统的相似性度量,根据作者的实验结果,该方法能提升一定的配准精度,但用GAN为什么能够提升配准精度我不太明白,我觉得这个思想对于多模态的配准任务可能更合适。就单模态,从理论上还很难说GAN一定比手工设计的相似性测度好吧?我记得有篇论文说过这种还是手工设计的相似性测度更好,深度学习学到的只是一种补充。或许将GAN与相似性测度结合起来能提升效果。
五、弱监督或双监督的形变场估计
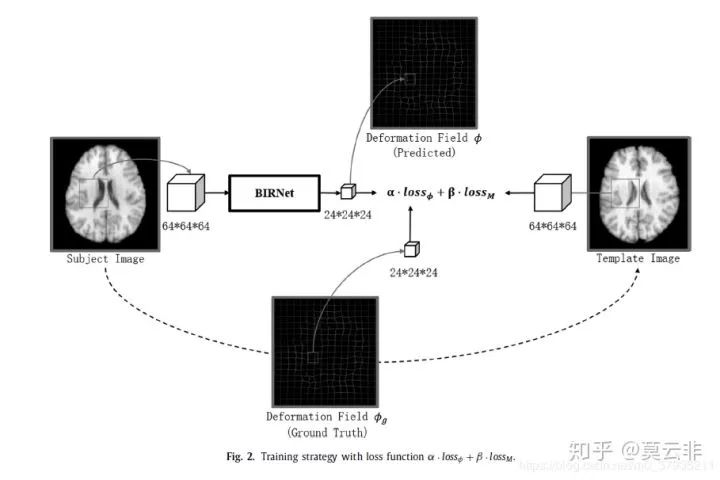
双监督:既选用扭曲后图像与参考图像的相似性测度也选用预测形变场与金标准之间的误差作为loss
[10]就是典型的例子,它的loss是两者的加权。
这篇论文的任务是对MR和TRUS图像进行刚性配准。生成器生成刚性变换的6个参数(输入是3维数据),通过重采样器由金标准和预测参数生成各自的采样后图像,判别器就判别这两幅图像。目标函数除了GAN的对抗项还有预测参数与金标准的欧式距离。这种方法本质上依然是双监督两项的结合,不过用对抗网络代替了原本扭曲后图像与固定图像的相似性测度,这里的对抗网络衡量的是根据预测参数扭曲后图像和根据金标准扭曲后图像的相似性测度。
讨论:我认为双监督的方法主要是减轻对金标准的过渡依赖,但是金标准的制作依然是个难题,此外相似性测度的选择也是一个问题,虽然可以采用GAN的结构用判别器来学习相似性测度,但GAN也有其劣势,比如不好训练。但目前用GAN做配准似乎也是一个比较热门的方向。
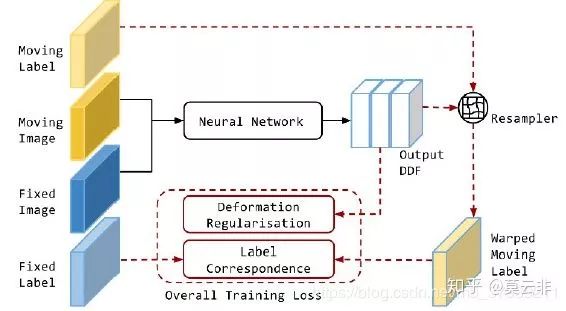
弱监督:采用了标签的相似性的测度作为目标函数,如下图。
这种方法是先事先分割出关键部位,如脏器部分,血管,关键点,导管等作为标签,训练时计算扭曲后的标签与固定图像上的标签的相似性测度(一般是Dice)作为目标函数的一部分。顺带一提,对于弹性配准,目标函数还要包含形变场的正则项。
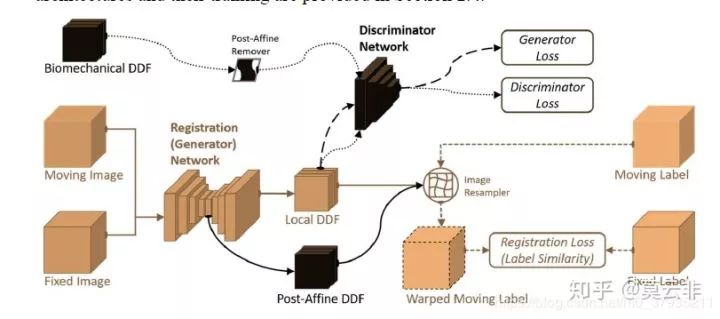
关于弱监督配准,作者胡一鹏连续发了三篇论文(单独写了一篇博文介绍,有时间再转到知乎上),2018年发表在TMI上的那篇是将弱监督与GAN结合了起来。
他的想法是通过引入判别器来对局部形变场进行更好的约束,从而代替以往的形变场的正则项。总体的框架是通过生成器生成仿射变换的形变场和局部形变场,通过传统的方法生成一个真实的局部形变,然后判别器进行判别预测的局部形变场和仿真生成的形变场。
讨论:要生成一个仿真形变场,那和监督学习相比区别在哪里呢?不要判别器,直接将生成loss换成监督学习的loss是不是一样的?
1. Wu, G., Kim, M., Wang, Q., Gao, Y., Liao, S., and Shen, D. (2013). Unsupervised
deep feature learning for deformable registration of mr brain images.
In International Conference on Medical Image Computing and Computer-Assisted
Intervention, pages 649{656. Springer.
2. Wu, G., Kim, M., Wang, Q., Munsell, B. C., and Shen, D. (2016). Scalable
high-performance image registration framework by unsupervised deep feature
representations learning. IEEE Transactions on Biomedical Engineering,
3. Cheng, X., Zhang, L., and Zheng, Y. (2016). Deep similarity learning for multimodal
medical images. In International conference on medical image computing
and computer-assisted intervention.
4. Cheng, X., Zhang, L., and Zheng, Y. (2018). Deep similarity learning for
multimodal medical images. Computer Methods in Biomechanics and Biomedical
Engineering: Imaging & Visualization, 6(3):248{252.
5. Miao, S., Wang, Z. J., and Liao, R. (2016a). A cnn regression approach for
real-time 2d/3d registration. IEEE transactions on medical imaging, 35(5):1352{
6. Miao, S., Wang, Z. J., Zheng, Y., and Liao, R. (2016b). Real-time 2d/3d
registration via cnn regression. In Biomedical Imaging (ISBI), 2016 IEEE 13th
International Symposium on, pages 1430{1434. IEEE.
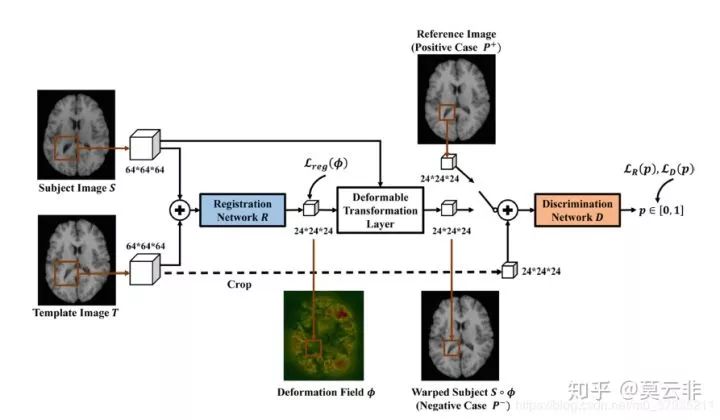
7.Chee, E. and Wu, J. (2018). Airnet: Self-supervised ane registration for 3d
medical images using neural networks. arXiv preprint arXiv:1810.02583
8.Salehi, S. S. M., Khan, S., Erdogmus, D., and Gholipour, A. (2018). Real-time
deep registration with geodesic loss. arXiv preprint arXiv:1803.05982
9.Fan, J., Cao, X., Xue, Z., Yap, P.-T., and Shen, D. (2018a). Adversarial similarity
network for evaluating image alignment in deep learning based registration.
In International Conference on Medical Image Computing and Computer-Assisted
Intervention, pages 739{746. Springer.
10.Fan, J., Cao, X., Yap, P.-T., and Shen, D. (2018b). Birnet: Brain image
registration using dual-supervised fully convolutional networks. arXiv preprint
11,Yan, P., Xu, S., Rastinehad, A. R., and Wood, B. J. (2018). Adversarial
image registration with application for mr and trus image fusion. arXiv preprint
-End-
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
觉得有用麻烦给个在看啦~ ![]()