DBA要失业了?看ML如何自动优化数据库
原文作者
Dana Van Aken,卡耐基梅隆大学,计算机科学博士生。
Andy Pavlo博士,卡耐基梅隆大学,计算机科学系数据库学的助理教授。
Geoff Gordon博士,卡耐基梅隆大学副教授,机器学习系教学副主任。
原文链接:https://aws.amazon.com/cn/blogs/ai/tuning-your-dbms-automatically-with-machine-learning/?tag=vglnk-c1507-20
译者介绍
杨志洪,DBAplus社群联合发起人,新炬网络首席布道师。Oracle ACE、OCM、《Oracle核心技术》译者。数据管理专家,拥有十余年电信、银行、保险等大型行业核心系统Oracle数据库运维支持经验,掌握ITIL运维体系,擅长端到端性能优化、复杂问题处理。现主要从事数据架构、高可用及容灾咨询服务。
转自「DBAplus社群」订阅号,译者已授权运维帮转发
译者注:看到标题的时候,确实被吓了一大跳。看的过程,心里其实一直在降低警惕。但完整看完这篇文章的时候,情绪又回落到刚看到标题的状态了。虽然DBA的工作不会那么快被AI替代,文章所说的也主要是开关(参数),但显然数据库的管理只会越来越智能,不是由厂家自己(比如Oracle,这些年从PGA自动管理,SGA自动管理到整个内存自动管理,从Perfstat到AWR到ADDM,正在一步步把DBA“傻瓜化”),就是由第三方公司或者研究机构(比如本文的卡耐基大学数据库研究团队),作为DBA来说,必须要不断尝试,站在一个更高层面来看待数据库,看待运维,看待IT,否则就会成为被机器人替代的炮灰。
数据库管理系统(DBMSs,DatabaseManagement Systems)是任何数据密集型应用最重要的组成部分。他们可以处理大规模数据和复杂的负载形态,但它们很难管理,因为它们有成百上千个配置“开关”,用来控制诸如将多少内存用作缓存、怎样将数据写到存储等等这些事情。企业或组织经常雇佣技术专家来帮忙做系统优化,但专家对许多公司来说还是非常昂贵的。
卡耐基梅隆大学数据库组的研究员和学生们研发了一款新工具,叫做OtterTune。OtterTune可以从数据库成百上千个配置开关中自动发现最佳设置。它的目标是让随便一个工程师都可以更容易去部署一套关系型数据库,即使他们在数据库管理方面没有任何专业知识也行。
OtterTune与其他的数据库配置工具不一样,因为它利用调优先前的数据库配置知识去调优新的数据库配置。这可以显著地降低调优一个新的数据库部署所需时间及相关的资源。为了做到这一点,OtterTune维持着一个资料库,其中存放了从先前调优环境中采集回来的调优数据。OtterTune使用这些调优模型来指导新应用程序的实验,推荐能够改进目标对象(比如降低延时或者提升吞吐量)的设置。
在这篇文章中,我们讨论OtterTune工具 ML pipeline(机器学习的工作流API库)的每个组件,并展示他们之间怎样互相协作去调优一个数据库配置。我们在MySQL和Postgre上评估OtterTune的调优能力,通过将OtterTune最佳配置的性能与DBA选择的配置及其他自动调优工具的配置得出的性能做比较。
OtterTune是一个开源工具,由卡耐基梅隆大学数据库研究组的研究员和学生们研发。所有的工具代码都放在GitHub上,遵从Apache License 2.0协议授权。
Otter Tune怎样工作?
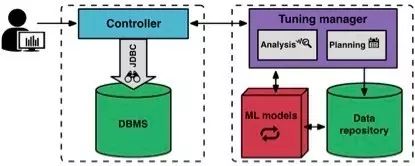
在一个新的调优场景,首先,用户告诉OtterTune要通过调优来满足哪个目标对象(比如,延迟或者吞吐量)。客户端的控制器(controller)连接到目标数据库,搜集它的Amazon EC2实例类型和当前配置。
然后控制器开始它的第一个探测周期,在这个期间内,它监控数据库,并记录目标对象。探测周期结束的时候,控制器从数据库中采集好内部指标,比如MySQL中从磁盘读取的页面和写到磁盘的页面(pages)的计数器。控制器会将目标对象和内部指标信息都传递给调优管理器(tuning manager)。
当OtterTune调优管理器收到这些指标后,把它们存放在资料库当中。OtterTune使用这些结果,计算下一个要部署的目标数据库的配置。调优管理器将这一配置信息传输给控制器,并告诉控制器,采纳这一配置后可能会获得的性能提升。用户可以决定是继续调优,还是结束这次优化工作。
注意
OtterTune为它支持的每个数据库版本维护着一个配置开关的黑名单。黑名单包括那些调整了不会产生效果的配置开关(比如,数据库中存放文件的路径名),或者这些开关会有严重的或者潜在不良后果(比如,可能会导致数据库丢失数据)。每场调优开始的时候,OtterTune都会给用户提供一个黑名单,所以他/她可以增加其他开关进去,如果他们希望OtterTune不要去调优这部分的话。
OtterTune作了一些假设限制,可能会限制了一些用户的可用性。比如,它假定用户有允许控制器更改数据库配置的管理权限。如果用户没有这个权限,那他或者她可以在其他硬件上部署一个数据库镜像,用于OtterTune调优实验。这就需要用户去重演(replay)一个工作负载跟踪,或者在生产数据库中转发查询。关于假定和限制的完整讨论,详见我们的论文(读者可以点击文末的“阅读原文”进行阅读)。
ML pipeline
下面的图中展示了通过OtterTune的ML pipeline,数据在移动过程中是如何处理的。所有探查数据都存放在OtterTune资料库中。
OtterTune首先将探测数据传给“工作负载表征”(Workload Characterization)组件。该组件识别一组较小的数据库指标度量,可以最佳地捕获性能上的差异性,以及不同工作负载的区别特征。
接着,开关识别组件(Knob Identification)生成一个开关的排名列表,以对数据库性能的影响度大小排序。OtterTune将所有这些信息提供给自动调优器(Automatic Tuner)组件。该组件在它的数据资料库中为目标数据库负载匹配(map)最相似的负载,并用这个负载数据生成最佳配置。
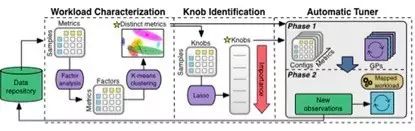
让我们把ML pipeline中的每个组件再详细说说。
工作负载表征(Workload Characterization)组件:OtterTune使用数据库内部运行时的度量指标来表征(或识别)工作负载的行为。这些度量指标提供了负载的准确表现,因为它们捕获了运行时行为的许多因素。可是,很多度量指标是冗余的,一些是相同的度量记录只是单位不同,其他的则是表现数据库不同组件,它们的值高度相关。所以裁剪冗余度量就很重要,这可以降低ML模型使用它们的时候的复杂性。为此,我们根据其相关性模型对数据库的度量指标进行了聚类。然后,我们从每个聚类中选择一个作为代表度量,就是最靠近聚类中心的那个度量。ML pipeline的后续组件直接使用这些度量。
开关识别组件(Knob Identification):数据库中可能有几百个开关,但只有一小部分会影响数据库的性能。OtterTune使用一个叫做Lasso的流行特征选择(feature-selection)技术,来确定哪些开关会很大程度上影响系统的整体性能。通过使用这一技术于资料库中的数据,OtterTune就可以列出数据库中这些开关的重要性顺序。
然后,OtterTune必须决定,做配置推荐的时候用多少个开关。使用太多必然会显著增加OtterTune的调优时间。用得太少又会妨碍OtterTune去找到最佳配置。OtterTune使用渐进化的方式自动化这一过程,在调优时它会逐渐增加开关的个数。这个方式让OtterTune在扩展到更多开关之前,探寻和优化一组最重要的开关配置。
自动调优(Automatic Tuner)组件:自动调优组件通过在每个观察周期之后执行“两步分析”(two-step analysis)来确定OtterTune应推荐的配置。
首先,系统使用工作负载表征组件中标识的度量性能数据,识别来自先前调优场景的最能匹配目标数据库负载的负载。它将当前场景的度量指标与先前场景的度量指标进行比较,以确定哪些指标与不同的开关设置类似。
然后,OtterTune会选择另一个开关设置去尝试。它适用一个统计模型,搜集数据,与资料库中最相近负载的数据一样。这个模型让OtterTune可以预测实施每个可能的配置后,数据库性能会怎样。OtterTune优化下一个配置,采用探索的方式(搜集信息以改进模型)而不是剥削的方式(试图只在目标度量上就贪婪地做好)。
实现
OtterTune用Python编写。
对工作负载表征和开关识别组件来说,运行时的性能并不特别需要考虑,因此我们用scikit-learn来实现相应的机器学习算法。这些算法以后台进程的形式运行,并使用OtterTune资料库中的新数据。
对自动优化组件来说,机器学习算法在关键路径上。他们在每一个观察周期后运行,获取新数据以便OtterTune能取得一个开关配置进行下一次尝试。因为它的性能是要特别考虑的,我们用TensorFlow来实现其算法。
搜集关于数据库硬件的数据、开关配置以及运行时的性能度量指标,我们将OLTP-Bench测评框架集成到OtterTune的控制器中。
实验设计
为了评估效果,我们使用OtterTune选择的最佳配置来比较MySQL和Postgre的性能:
默认配置:数据库安装时的配置
优化脚本:由一个开源调优工具生成的配置
DBA:人类DBA选择的配置
RDS:由亚马逊研发定制的数据库配置,部署在相同的EC2实例类型上
我们所有的实验都是在Amazon EC2 Spot Instance上完成的。每一个实验都用了2个实例:一个作为OtterTune控制器,一个作为目标数据库部署用。我们分别使用m4.large和m3.xlarge实例类型。我们将OtterTune调优管理器和资料库部署在本地服务器上,配置是20核CPU、128G内存。我们用TPC-C负载模型,这是评估OLTP系统性能的工业标准。
评估
对实验中我们用到的每一种数据库,MySQL及Postgre,我们评估延迟和性能。下面的图展示了评估结果。第一个图表展示了第99百分位数指标的延迟数量,代表完成交易所需的“最坏情况”时间长度。第二个图展示吞吐量的结果,评估的是每秒完成的平均事务数。
MySQL评估结果:
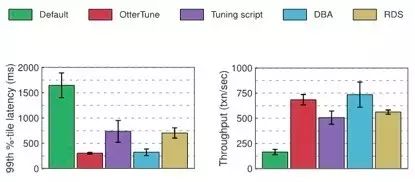
比较由OtterTune生成的最佳配置与其他工具的“优化脚本”、RDS生成的配置,OtterTune推荐的配置对MySQL数据库大约降低了60%的延迟,提升了22%到35%的吞吐量。OtterTune生成的配置几乎与DBA做的选择一样好。
只有一些MySQL的开关会显著影响TPC-C负载的性能。由OtterTune生成的配置和DBA为每个开关提供了很好的设置。RDS干的稍微要差点,因为它为一个开关提供了不是最优的设置。“优化脚本”的配置表现最差,因为它只改了一个开关。
Postgre评估结果:
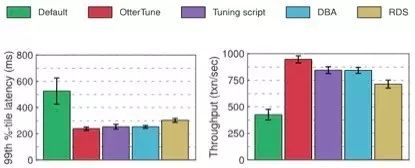
对延迟来说,OtterTUne生成的配置,与“优化脚本”、DBA、RDS差不多,相对Postgre的默认设置都获得了不少的提升。我们可以将其归因于OTLP测评工具客户端和数据库之间的网络开销。对于吞吐量,OtterTune设置相对DBA和“优化脚本”的设置得到了12%的提升,相对RDS,得到了32%的提升。
跟MySQL相似,只要少数开关显著影响Postgre的性能。OtterTune、DBA、“优化脚本”以及RDS都调整了所有这些开关,大多都提供了合理的设置。
结论
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优新的数据库部署,重用从先前调优场景获取的训练数据。因为OtterTune不需要为训练ML模型生成厨师数据集,所需调优时间大大减少。
译后记
OtterTune为关系型数据库的配置开关自动化发现最佳设置,用于调优。
不客气地说,OtterTune目前也只是支持MySQL和Postgre两种数据库,而且只是在开关设置层面,相比Oracle数据库在自动化管理方面的强大功力,OtterTune只能算是一个玩具。我突然想到,2004年的时候,我去贵州给某个运营商做Oracle数据库优化,只是把SGA从100M调大到1GB,客户的核心业务整体性能就得到了飞速提升。放到今天来说是个不可思议的事情,今天随便一个省级运营商的核心系统标配可能都是一个TB的内存,缺省安装的时候,工程师就会把SGA缺省配到700G,其他相关参数也会按所谓的最佳实践进行。
但是,没有开关的问题,不代表就没有数据库的性能问题。
时至今日,Oracle数据库的性能问题依然层出不穷(不是因为Oracle不行,其他数据库还在后面远远的跟着Oracle在前进呢),参数开关层面基本已经不太可能有遗漏。性能问题更多的层面来自于开发,开发部门数据模型设计得不合理,开发人员SQL写得不合理,往往导致了90%的性能问题。前两天朋友谈及的一个案例,某银行的信用卡业务查询,每天一次,表当然有几亿条记录,查询一次要花费小时计的时间,通过一个简单的rownum<2,查询时间降低到秒级。单纯的开发人员搞不定,普通的DBA也想不到,机器学习能做这种优化么?现在不好判断。
有远虑,不是坏事。但也无需太执着于远虑,还是要把当前的事情先做好。
如果你们的开发团队老是出一些表结构设计问题、索引问题、劣质SQL问题,不妨推荐他们先来上上D+学院先开设的精品SQL优化课程。Oracle和MySQL都有,只要一天时间,可以跟业界一线DBA大师学习怎样做SQL优化,省时、省力、利人、利己。
当然,如果你连1天完整时间都抽不出来,也不用气馁,DBAplus仍然不定期将各类优化妙文推送出来,给需要精进的你。
点击「阅读原文」直达原文
商务合作请加微信,扫描下方二维码




