经历了长达数月的芯片短缺导致的出货延迟、技术试验以及反复调试之后,EleutherAI 在今天官宣了最新的 200 亿参数开源语言模型「GPT-NeoX-20B」。
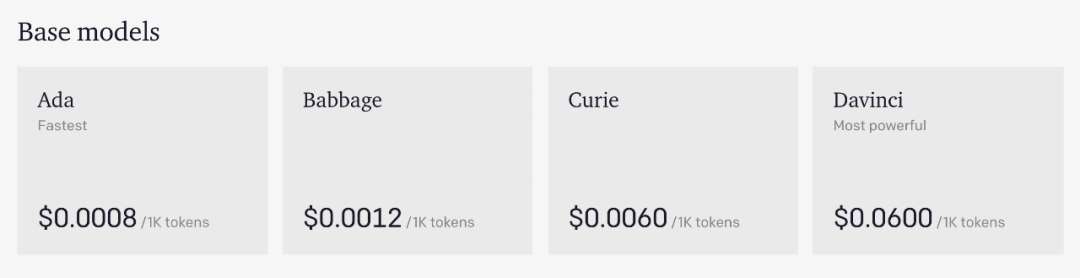
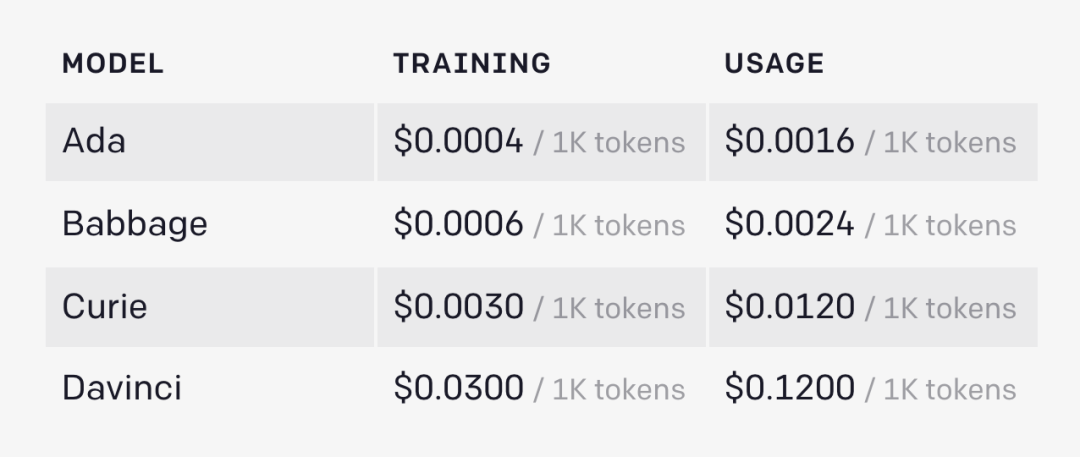
自从 2020 年 5 月 OpenAI 高调推出 1750 亿参数「GPT-3」,人工智能领域就掀起了一阵大模型的巨浪。由于微软拥有对 GPT-3 源代码的独家访问权,不同于 GPT-2 和 GPT-1,OpenAI 并没有开源 GPT-3,而是通过商业 API 来提供该模型的能力及训练数据集。这些服务很快开始收费,且价格不菲:
![]()
![]()
按照这样的收费标准,很多普通用户是玩不起的。所以,目前 OpenAI API 更适用于大规模企业用户。
这种「矛盾」恰恰推动了 EleutherAI 的诞生,促使其开发「野生版」 GPT-3。
EleutherAI 成立于 2020 年 7 月,是一个由机器学习研究人员组成的小组,宗旨是努力构建和开源大型语言模型。此前,他们开发了 GPT-Neo,这是 GPT-3 的复现与开源中最优秀的项目之一。去年 3 月,EleutherAI 在 GPT-Neo 项目主页放出了复现版 GPT-3 的模型参数(1.3B 和 2.7B 级别),并将其更新在了 Colab notebook 上。不过,GPT-Neo 开源模型里较大的版本也只达到了 GPT-3 商用版里最小模型的参数量。去年 6 月,EleutherAI 又开源了 60 亿参数的自然语言处理 AI 模型 GPT-J。
现在,更大规模、更优表现的 GPT-NeoX-20B 已经面世。研究者称,GPT-NeoX-20B 是目前最大的可公开访问的预训练通用自回归语言模型,并在多项任务上取得了优于 OpenAI Curie 的不俗表现。
![]()
对于 EleutherAI 来说,GPT-NeoX-20B 只能算是一项阶段性成果,他们的最终目标是将参数规模扩展到 1700 亿左右,就像 GPT-3 一样。
实际上,在打造类 GPT 系统的道路上,研究者首先发现了训练大模型时的数据挑战。
由于 OpenAI 对训练过的数据细节很吝啬(而且肯定不会发布副本),因此 EleutherAI 自己创建了一个用于语言建模的 800GB 多元文本数据集。
2021 年元旦,EleutherAI 发布了 The Pile,这是一个 825GB 的用于训练的多样化文本数据集。The Pile 由 22 个不同的高质量子集构成,包括现有的和新建的,其中许多来源于学术领域或各专业领域。
![]()
论文链接:https://arxiv.org/abs/2101.00027
下载地址:https://pile.eleuther.ai/
这个数据集也是开源的,前不久,研究者另外发布了一份关于 The Pile 的数据手册:https://arxiv.org/pdf/2201.07311.pdf
The Pile 数据集为 GPT-NeoX-20B 的搭建铺平了一半的道路,另一半挑战则来自于硬件。此前,在 GPT-Neo 和 GPT-J 的训练过程中,EleutherAI 都是通过 TPU Research Cloud (TRC) 访问抢占式 TPU,但想在合理的时间内用 TRC TPU 训练超过数百亿参数的模型是不现实的。
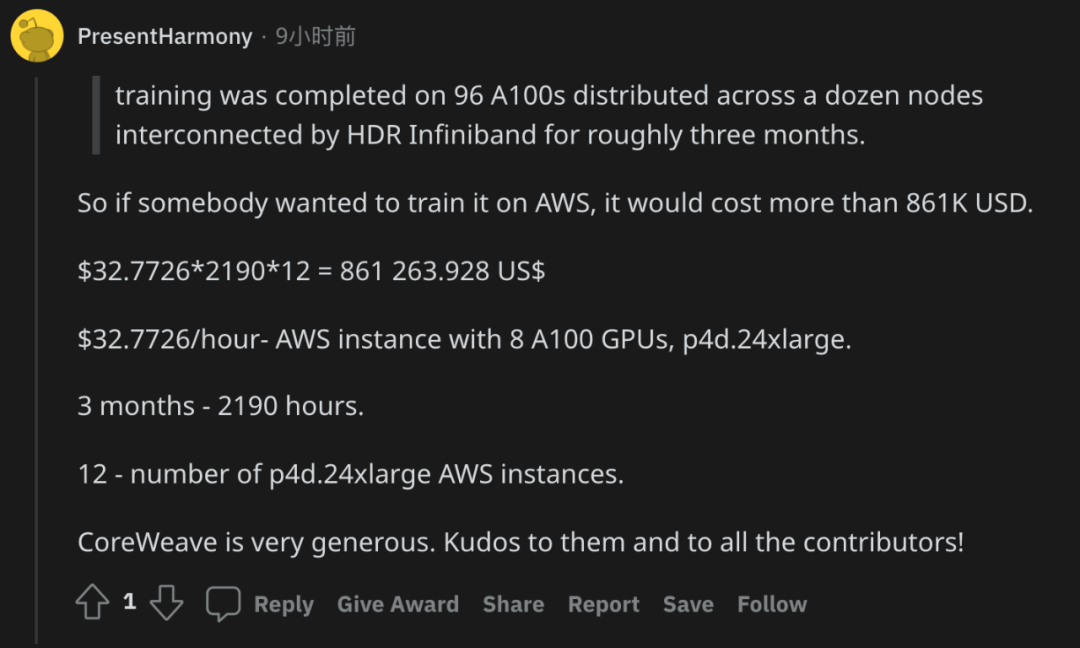
2021 年 1 月,EleutherAI 宣布与 CoreWeave 达成合作,CoreWeave 承诺为 GPT-NeoX-20B 模型训练提供 GPU 资源。研究者透露,他们在 96 个 A100 上完成了 GPT-NeoX-20B 的训练,这些 A100 分布在由 HDR Infiniband 互连的十几个节点上,训练时间持续了大约三个月。
![]()
有人根据 AWS 的收费标准粗略地计算了一下训练过程所需要的成本,大概有 86 万美元:
![]()
在后续即将发布的详细文档中,研究者还将对 GPT-NeoX-20B 的训练细节进行更多介绍。
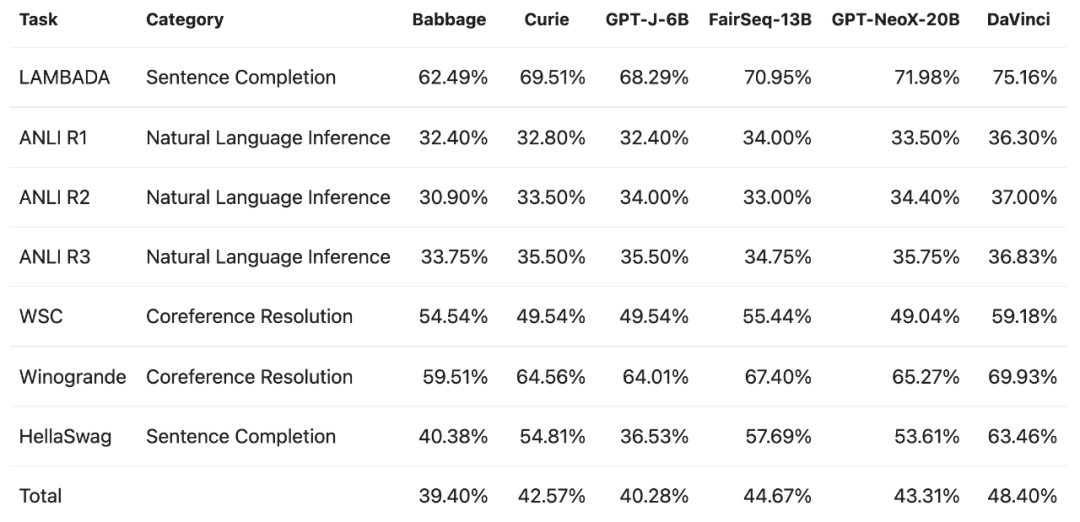
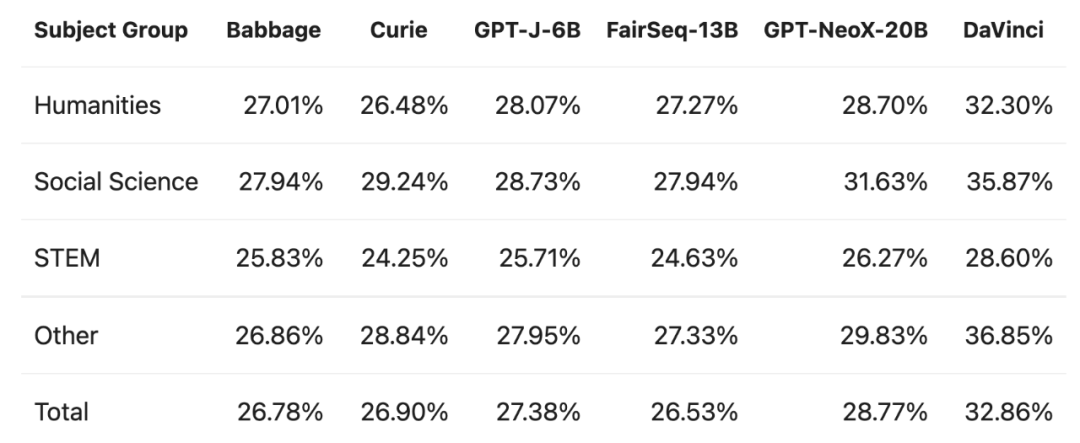
研究者首先在 LAMBADA 等多项标准任务上对比了 GPT-NeoX-20B 与 Babbage、Curie、DaVinci 这些 OpenAI 商业 API 以及 GPT-J-6B 等模型的表现。
从性能表现上来看,GPT-NeoX-20B 总体优于 Babbage、Curie、GPT-J-6B,但和 DaVinci 相比还存在一定差距。
![]()
![]()
根据 HendrycksTest 评估,各模型对不同学科组事实知识的准确性测量对比。
还有很重要的一点是:GPT-NeoX-20B 如何开源并提供给广大开发者使用?
有人表示,自己曾在一年前申请了 GPT-3 的访问权限,但从未收到回复。在 GPT-NeoX-20B 项目中,这样的情况显然不会发生。
![]()
从 2 月 9 日开始,GPT-NeoX-20B 完整的模型权重可以在 The Eye 的 Apache 2.0 许可下免费下载。此外,用户也可以在 https://goose.ai (https://goose.ai/) 上试用该模型。
https://blog.eleuther.ai/announcing-20b/
https://www.reddit.com/r/MachineLearning/comments/sit4ro/n_eleutherai_announces_a_20_billion_parameter
公众号后台回复“transformer”获取最新Transformer综述论文下载~
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
![]()