不能错过!简单易懂的哈希表总结


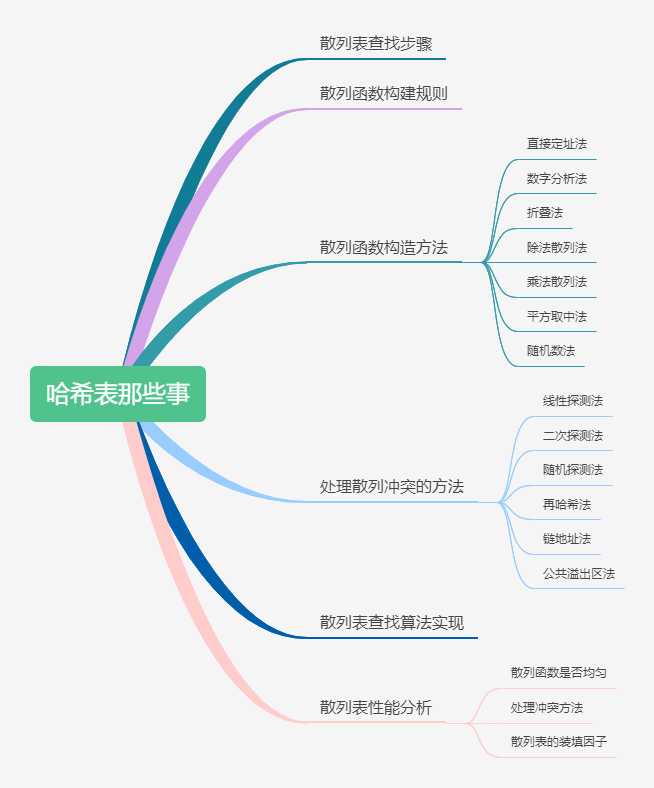
由于菜品太多,每当结账时,老板娘总是按照菜单一个一个找价格(遍历查找),每次都要找半天,所以结账的地方总是排起长队,顾客们表示用户体验很差。袁厨一想这不是办法啊,太浪费大家时间了,所以袁厨就先把菜单按照首字母排序(二分查找),然后查找的时候根据首字母查找,这样结账的时候就能大大提高检索效率啦!但是呢?工作日顾客不多,老板娘完全应付的过来,但是每逢节假日,还是会排起长队。那么有没有什么更好的办法呢?对呀!我们把所有的价格都背下来不就可以了吗?每个菜的价格我们都了如指掌,结账的时候我们只需把每道菜的价格相加即可。所以袁厨和老板娘加班加点的进行背诵。

散列表查找步骤
-
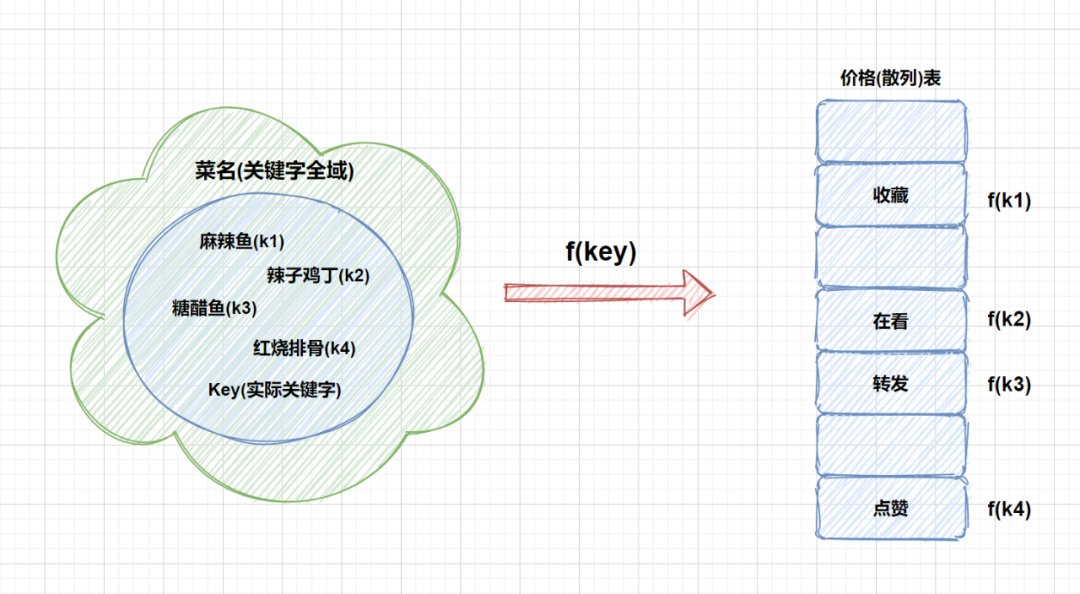
通过散列函数计算记录的散列地址,并按此散列地址存储该记录。就好比麻辣鱼,我们就让它在川菜区,糖醋鱼,我们就让它在鲁菜区。但是我们需要注意的是,无论什么记录我们都需要用同一个散列函数计算地址,然后再存储。 当我们查找时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录。因为我们存和取的时候用的都是一个散列函数,因此结果肯定相同。
-
必须是一致的。 假设你输入辣子鸡丁时得到的是在看,那么每次输入辣子鸡丁时,得到的也必须为在看。如果不是这样,散列表将毫无用处。 -
计算简单。 假设我们设计了一个算法,可以保证所有关键字都不会冲突,但是这个算法计算复杂,会耗费很多时间,这样的话就大大降低了查找效率,反而得不偿失。所以咱们散列函数的计算时间不应该超过其他查找技术与关键字的比较时间,不然的话我们干嘛不使用其他查找技术呢? -
散列地址分布均匀我们刚才说了冲突的带来的问题,所以我们最好的办法就是让散列地址尽量均匀分布在存储空间中,这样即保证空间的有效利用,又减少了处理冲突而消耗的时间。

散列函数构造方法
2.1 直接定址法

2.2 数字分析法
2.3 折叠法
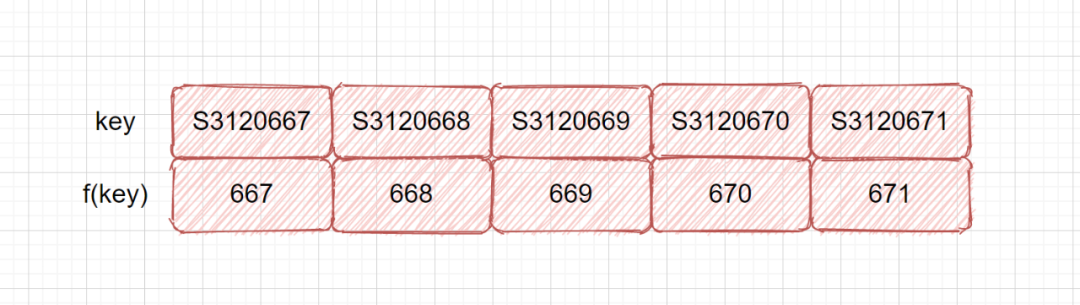
2.4 除法散列法
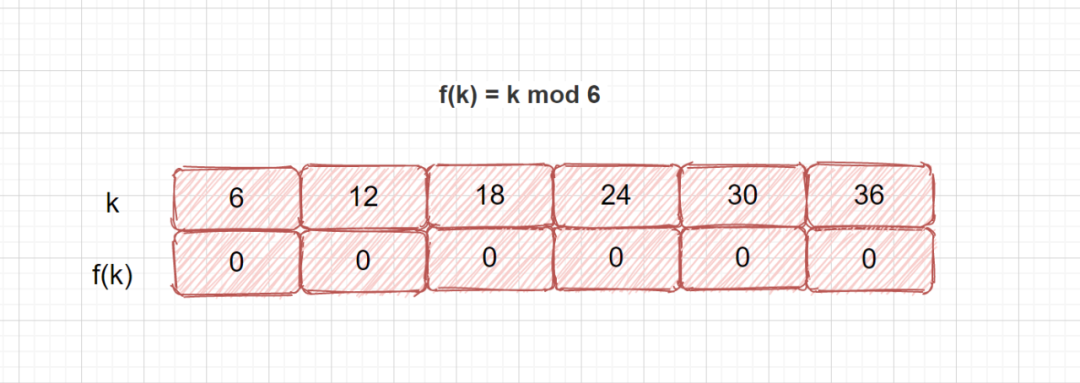
-
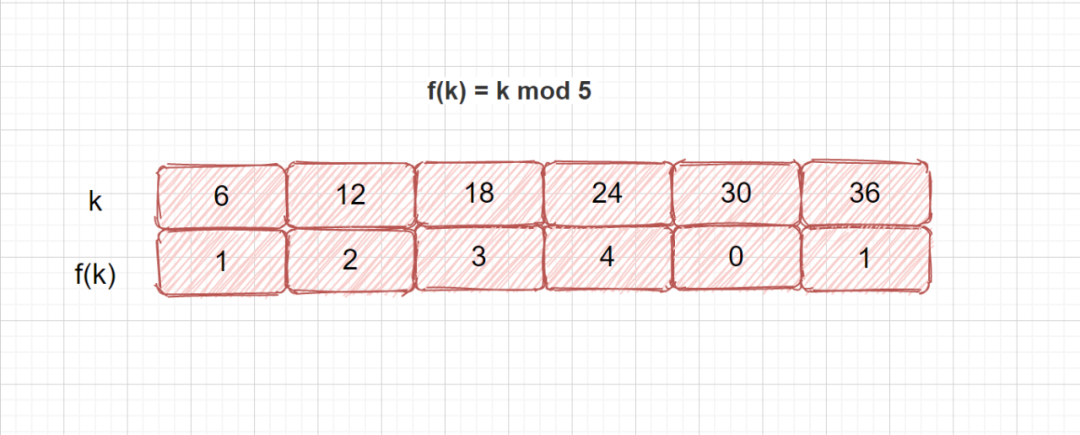
m 不应为 2 的幂,因为如果 m = 2^p ,则 f(k) 就是 k 的 p 个最低位数字。例 12 % 8 = 4 ,12 的二进制表示位 1100,后三位为 100。 -
若散列表长为 m ,通常 p 为 小于或等于表长(最好接近m)的最小质数或不包含小于 20 质因子的合数。
合数:合数是指在大于 1 的整数中除了能被 1 和本身整除外,还能被其他数(0 除外)整除的数。 质因子:质因子(或质因数)在数论里是指能整除给定正整数的质数。

2.5 乘法散列法
-
用关键字 k 乘上常数 A(0 < A < 1),并提取 k A 的小数部分 -
用 m 乘以这个值,再向下取整
2.6 平方取中法
2.7 随机数法

处理散列冲突的方法
3.1 开放地址法
袁记菜馆内,铃铃铃,铃铃铃 电话铃响了 大鹏:老袁,给我订个包间,我今天要去带几个客户去你那谈生意。 袁厨:大鹏啊,你常用的那个包间被人订走啦。 大鹏:老袁你这不仗义呀,咋没给我留住呀,那你给我找个空房间吧。 袁厨:好滴老哥
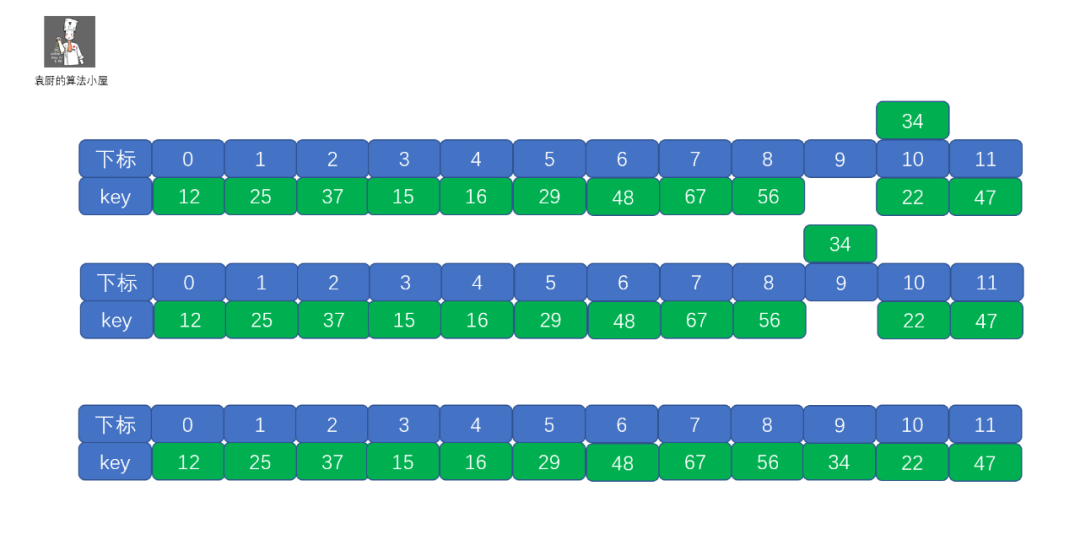
线性探测法


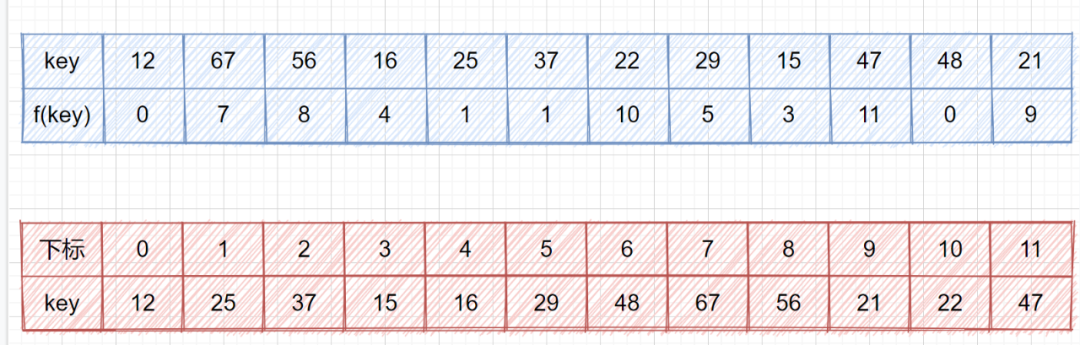
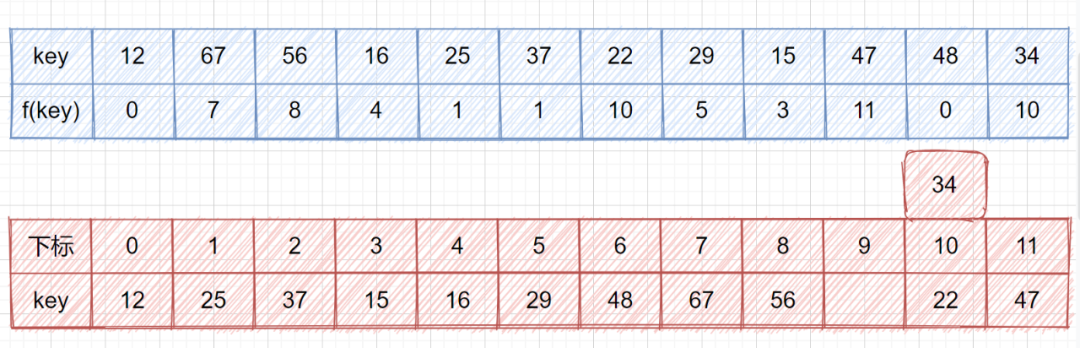
二次探测法
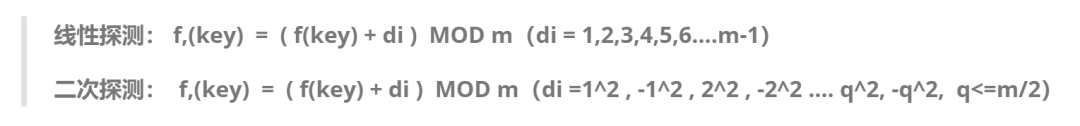
随机探测法
必须是一致的,假设你输入辣子鸡丁时得到的是在看,那么每次输入辣子鸡丁时,得到的也必须为在看。如果不是这样,散列表将毫无用处。
那么问题来了,我们使用随机数作为他的偏移量,那么我们查找的时候岂不是查不到了?因为我们 di 是随机生成的呀,这里的随机其实是伪随机数。伪随机数含义为,我们设置随机种子相同,则不断调用随机函数可以生成不会重复的数列,我们在查找时,用同样的随机种子,它每次得到的数列是相同的,那么相同的 di 就能得到相同的散列地址。
随机种子(Random Seed)是计算机专业术语,一种以随机数作为对象的以真随机数(种子)为初始条件的随机数。一般计算机的随机数都是伪随机数,以一个真随机数(种子)作为初始条件,然后用一定的算法不停迭代产生随机数
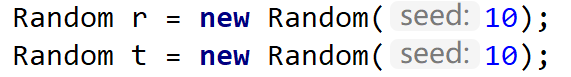
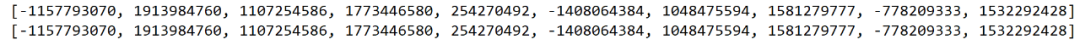
再哈希法
链地址法
袁记菜馆内,铃铃铃,铃铃铃电话铃又响了,那个大鹏又来订房间了。 大鹏:老袁啊,我一会去你那吃个饭,还是上回那个包间 袁厨:大鹏你下回能不能早点说啊,又被人订走了,这回是老王订的 大鹏:老王这个老东西啊,反正也是熟人,你再给我整个桌子,我拼在他后面吧
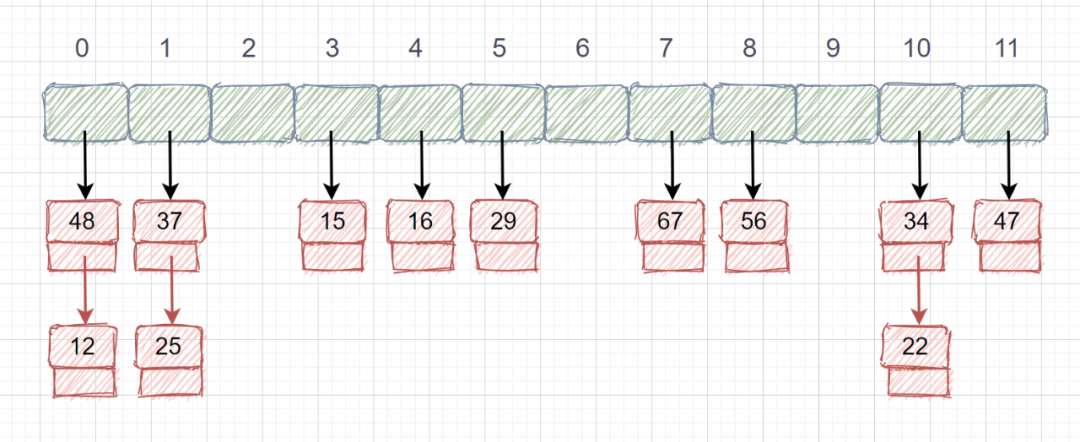
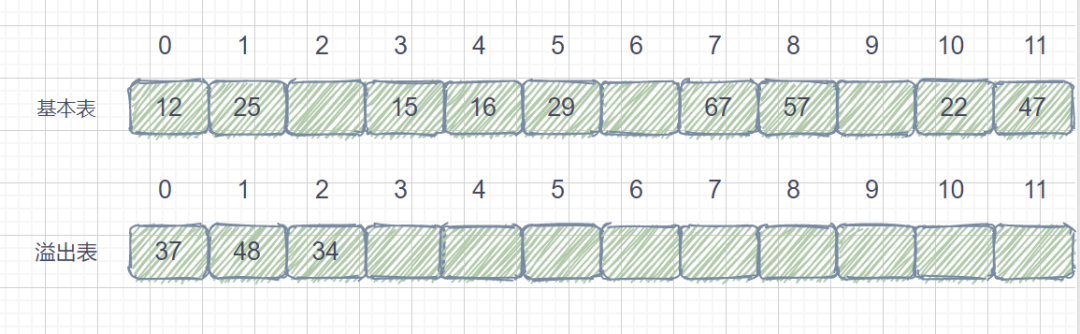
公共溢出区法
袁记菜馆内….. 袁厨:呦,这是什么风把你给刮来了,咋没开你的大奔啊。 大鹏:哎呀妈呀,别那么多废话了,我快饿死了,你快给我找个位置,我要吃点饭。 袁厨:你来的,太不巧了,咱们的店已经满了,你先去旁边的小屋看会电视,等有空了我再叫你。小屋里面还有几个和你一样来晚的,你们一起看吧。 大鹏:电视?看电视?

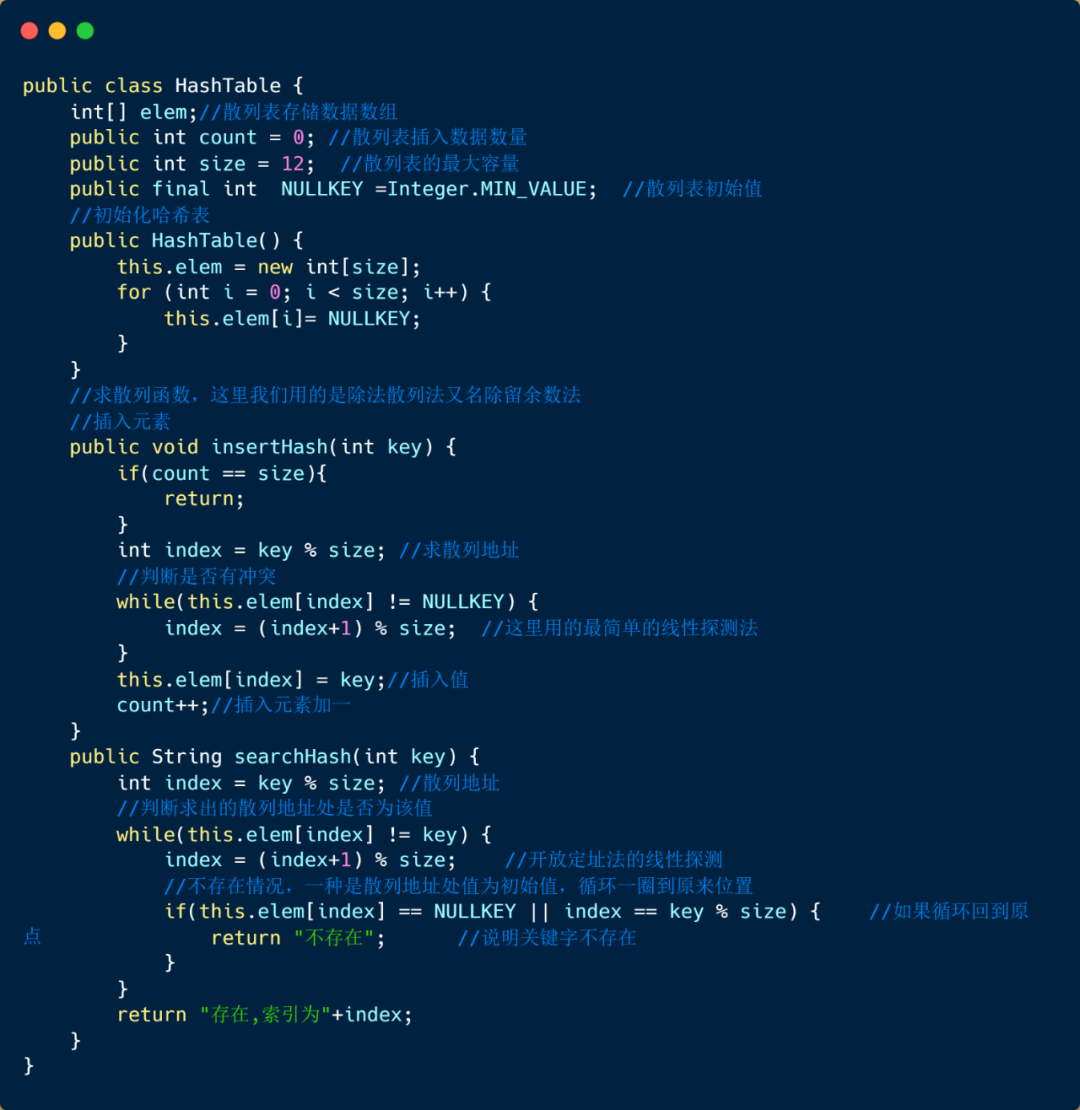
散列表查找算法(线性探测法)

-
通过哈希函数(除法散列法),将key转化为数组下标; -
如果该下标中没有元素,则插入,否则说明有冲突,则利用线性探测法处理冲突。详细步骤见注释

通过哈希函数(同插入时一样),将key转化成数组下标
通过数组下标找到key值,如果key一致,则查找成功,否则利用线性探测法继续查找。


散列表性能分析
装填因子 α = 填入表中的记录数 / 散列表长度


更多精彩推荐
☞ 华大基因辟谣“基因编辑58个婴儿”;苹果发布头戴式耳机AirPods Max;Debian 10.7发布|极客头条
☞索要 2.3 亿元赎金!富士康遭遇黑客攻击☞与 Brian Kernighan 一起回忆 Unix 的诞生!
☞ 挑战 Linux 之父认为的“不可能”:向 M1 Mac 移植 Linux
☞TIOBE 12 月编程语言:Python 有望第四次成为年度语言!☞ 升级版APDrawing,人脸照秒变线条肖像画,细节呈现惊人
![]()
点分享
![]()
点点赞
![]()
点在看



登录查看更多
相关内容

专知会员服务
24+阅读 · 2019年11月20日





相关VIP内容
专知会员服务
24+阅读 · 2019年11月20日
相关资讯