使用BERT进行跨领域情感分析
 !
!
阅读大概需要7分钟 ![]()
跟随小博主,每天进步一丢丢 ![]()



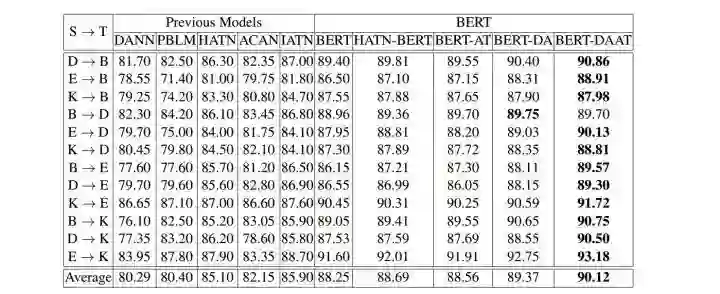
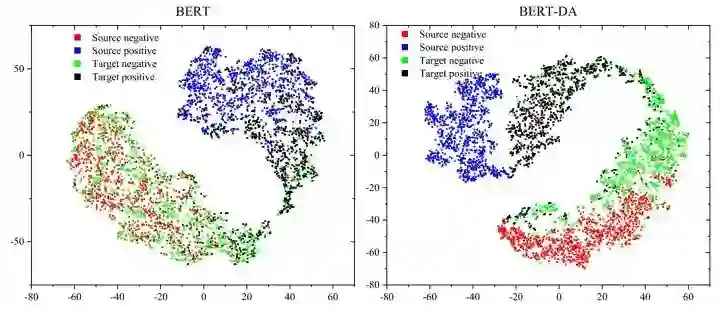
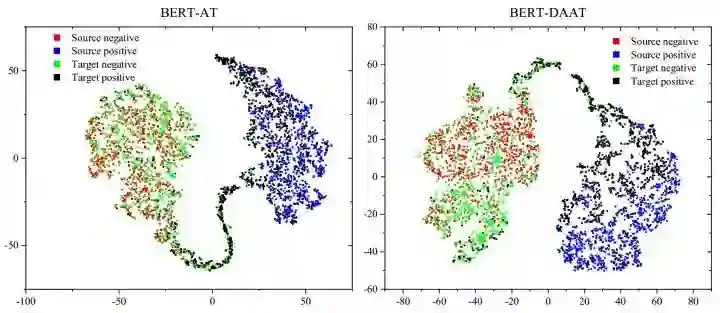
这篇文章所研究的“跨领域情感分析”,旨在通过源领域的标注数据对目标领域的无标注数据进行情感分类。源领域如餐饮领域,目标领域如电子产品领域,这两个领域之间存在一定的差异。为了克服领域间的差异,一大类工作的思路是在特征抽取阶段,抽取领域不变的特征。比如以下两个句子中,“不错”则是领域不变的特征,而“清晰”和“周到”则是领域特定的特征。
电子产品领域:这个屏幕不错,很清晰。
餐饮领域:他们的服务不错,很周到。
BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis( https://www.aclweb.org/anthology/N19-1242/ )


由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

登录查看更多
相关内容

【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
Arxiv
8+阅读 · 2019年3月22日



相关VIP内容
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
相关资讯
相关论文
Arxiv
8+阅读 · 2019年3月22日