【干货】Lossless Triplet Loss: 一种高效的Siamese网络损失函数
【导读】本文是数据科学家Marc-Olivier Arsenault撰写的一篇博文,主要讲解了在Siamese网络中使用Lossless Triplet Loss。尽管Google的FaceNet利用Triplet Loss效果显著,但作者认为,原来网络中triplet_loss函数存在一定的瑕疵:“每当你的损失小于0时,损失函数就不能提供任何信息”。为解决这种问题,作者构建一个能够捕捉到小于0的损失——Lossless Triplet Loss。在文中充分分析了不同传统Triplet Loss及其变体的不足,然后通过实验初步证明了提出的损失函数的有效性。专知内容组编辑整理。

Lossless Triplet Loss
一种高效的Siamese网络损失函数
在工作中,我们使用Siamese网络在电信数据上进行one shot学习。我们的目的是用神经网络来检测失败的电信操作 (Telecom Operators)。为此,我们将网络的状态编码成了一个N维的信息,根据这个信息,我们可以判断网络的状态以及检测失败。这种编码的方式和Word2Vec有点类似。为了得到这种编码,我们用了Siamese网络来产生可用于任何网络的one shot编码。
想要有关实验的信息,可以阅读下面的链接:
https://thelonenutblog.wordpress.com/2017/12/14/do-telecom-networks-dreams-of-siamese-memories/。
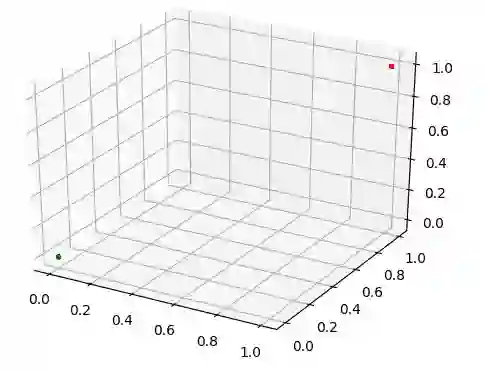
目前我们的实验进行的很书里,Siamese网络可以将不同的流量场景区分开。正如下图所示,良好的流量场景(绿色)和两种异常的流量场景(红色和橙色)的空间位置有明显的区别。
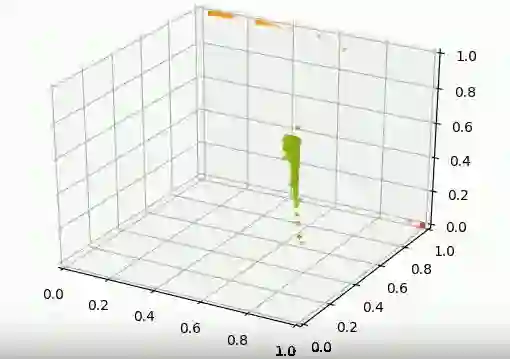
问题
上面的算法看起来没有什么问题,看起来很不错,对么?经过思考,我发现这个算法的损失函数有一个很大的瑕疵。
代码链接:https://gist.githubusercontent.com/marcolivierarsenault/3be90c1977e53224811ae0faa5476da5/raw/cd14dde3636658cc7b05963faa6889a338a2de0c/defaultSiamese.py
def triplet_loss(y_true, y_pred, alpha=0.4):
"""
Implementation of the triplet loss function
Arguments:
y_true -- true labels, required when you define a loss in Keras,
you don't need it in this function.
y_pred -- python list containing three objects:
anchor -- the encodings for the anchor data
positive -- the encodings for the positive data
(similar to anchor)
negative -- the encodings for the negative data
(different from anchor)
Returns:
loss -- real number, value of the loss
"""
anchor = y_pred[:, 0:3]
positive = y_pred[:, 3:6]
negative = y_pred[:, 6:9]
# distance between the anchor and the positive
pos_dist = K.sum(K.square(anchor - positive), axis=1)
# distance between the anchor and the negative
neg_dist = K.sum(K.square(anchor - negative), axis=1)
# compute loss
basic_loss = pos_dist - neg_dist + alpha
loss = K.maximum(basic_loss, 0.0)
return loss
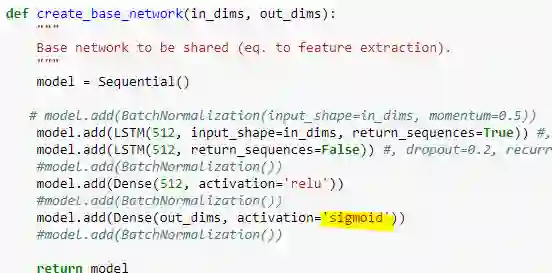
def create_base_network(in_dims, out_dims):
"""
Base network to be shared.
"""
model = Sequential()
model.add(BatchNormalization(input_shape=in_dims))
model.add(LSTM(512, return_sequences=True, dropout=0.2,
recurrent_dropout=0.2, implementation=2))
model.add(LSTM(512, return_sequences=False, dropout=0.2,
recurrent_dropout=0.2, implementation=2))
model.add(BatchNormalization())
model.add(Dense(512, activation='relu'))
model.add(BatchNormalization())
model.add(Dense(out_dims, activation='linear'))
model.add(BatchNormalization())
return model
in_dims = (N_MINS, n_feat)
out_dims = N_FACTORS
# Network definition
with tf.device(tf_device):
# Create the 3 inputs
anchor_in = Input(shape=in_dims)
pos_in = Input(shape=in_dims)
neg_in = Input(shape=in_dims)
# Share base network with the 3 inputs
base_network = create_base_network(in_dims, out_dims)
anchor_out = base_network(anchor_in)
pos_out = base_network(pos_in)
neg_out = base_network(neg_in)
merged_vector = concatenate([anchor_out, pos_out, neg_out], axis=-1)
# Define the trainable model
model = Model(inputs=[anchor_in, pos_in, neg_in], outputs=merged_vector)
model.compile(optimizer=Adam(),
loss=triplet_loss)
# Training the model
model.fit(train_data, y_dummie, batch_size=256, epochs=10)
问题在于下面这个损失函数代码:loss =K.maximum(basic_loss,0.0)。
这就是最主要的问题,每当你的损失小于0时,损失函数就不能提供任何信息。这个损失函数的作用如下图所示:
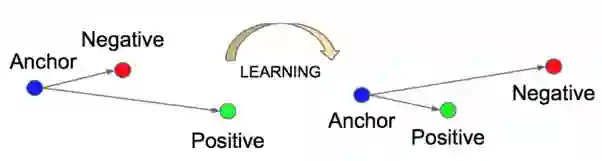
它使得与Anchor相似的点(Positive)相比于与Anchor不同的点(Negative)相对靠近Anchor。公式如下所示:
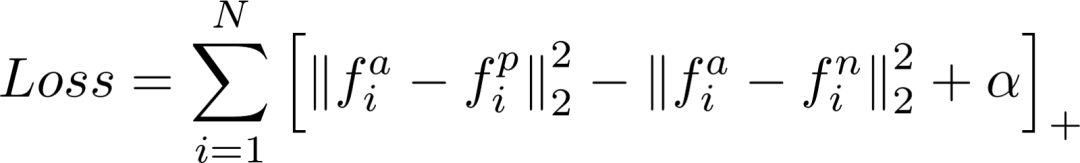
流程的细节可以在下面论文中看到:FaceNet: A Unified Embedding for Face Recognition and Clustering 。
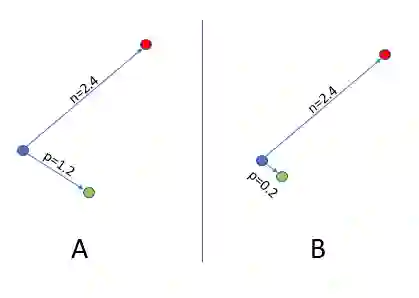
所以只要Anchor到Negative点的距离比Anchor到Positive点的距离大α,损失函数就得不到反馈信息。如下图所示:
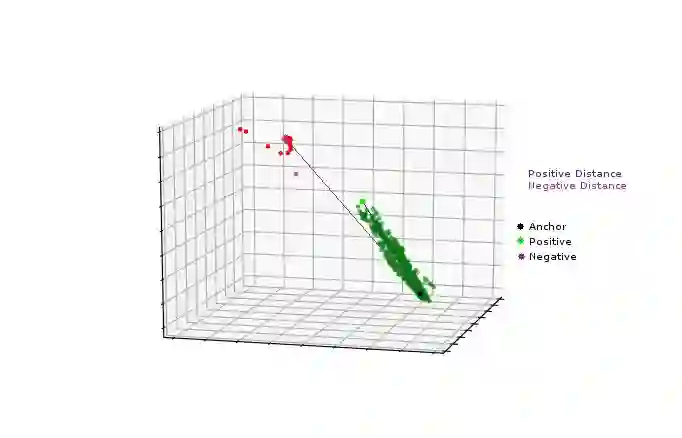
假设:α= 0.2,Negative Distance=2.4,Positive Distance=1.2。这时损失函数是:1.2–2.4 + 0.2 = -1。经过Max(-1, 0),最终我们得到一个位0的loss。当PositiveDistance为小于1的任何值时,损失函数都不会变化。这样,算法就很难再去缩减Anchor和Positive之间的距离了。
如下图所示,在两个场景A和B中,loss都是0,但是我们更希望得到B中的结果。
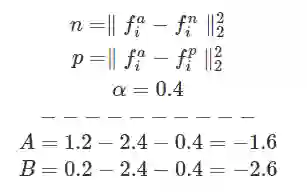
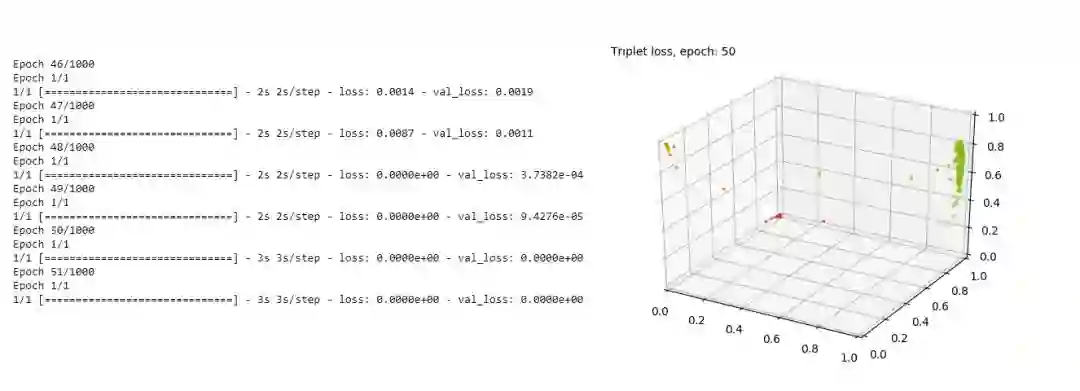
也就是说,这个损失函数的结果并不可信,比如下图是某次实验在Epoch=50左右时的结果,train和dev的损失都是0,但是明显,这个结果并不令人满意。
其它损失(Other Losses)
另一种熟悉的损失函数(由Yan LeCun和他的团队在论文Dimensionality Reduction by Learning an Invariant Mapping中提出)可以用来增大Anchor和Negative之间的距离,但也存在同样的问题。
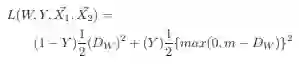
方案
根据文章的题目,你应该可以猜到我的计划了。我们需要构建一个能够捕捉到小于0的损失。经过一些几何计算,我意识到,我们需要制造一个能够包含所有编码后的N维向量的空间。第一步,我们修改了模型。将最后一层(Embedding层)的激活方式由不激活改为了由Sigmoid激活,这样每个维度都可以被限定在0和1之间。
在这样的设定下,最大的距离是N(N是编码的维度)。例如,当anchor分别是[0,0,0],Negative Point是[1,1,1]时,基于Schroff公式的距离是1²+1²+1² = 3。所以当我们考虑了维数时,我们可以推断出最大距离。下面是我提出的公式:
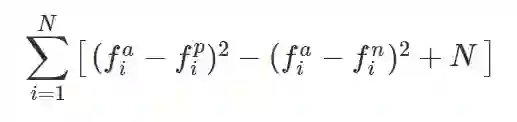
Linear loss function
这和之前的公式有点相似,但是由于加了Sigmoid激活,现在我们可以保证损失大于0。
初步结果
经过初始的测试,我们得到下面的模型:
从好的方面看,相同类别的点变得非常聚集,甚至聚集成了想通的点。从坏的方面看,两种错误的情况(橙色和红色)变得重叠了,这是因为当它们分离时,损失会变大。所以我们需要找个办法来打破损失的线性特征,也就是,是的它比数据分离造成的损失更大。
非线性
我们提出一种非线性的损失函数(N=3):
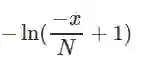
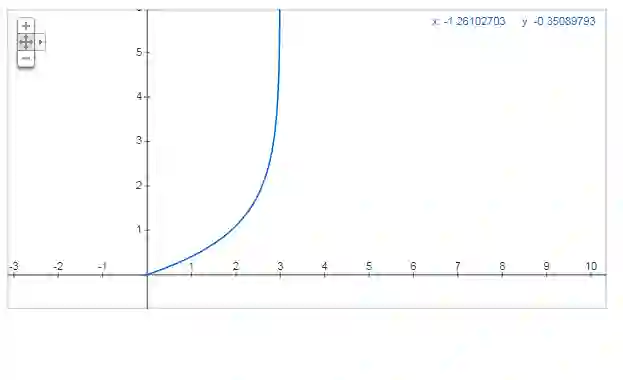
引入这种非线性,我们的损失函数变为:
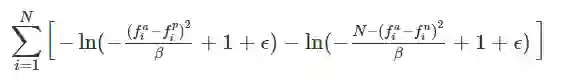
Β是一个尺度因子,我们建议将它设置为N。使用这种损失函数的结果如下:
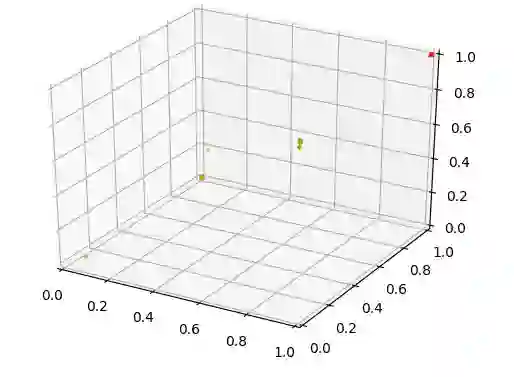
相对于标准的triplet损失,我们达到了更聚集的的点。
代码链接:
https://gist.githubusercontent.com/marcolivierarsenault/a7ef5ab45e1fbb37fbe13b37a0de0257/raw/99d623ccc467c21e2859036ec00ba926c4a796a4/lossless_triplet_loss.py。
记住,最后一层网络一定要使用Sigmoid激活。
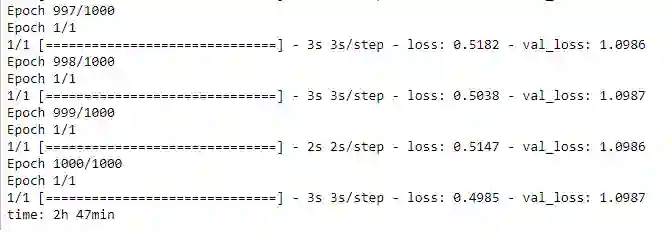
甚至在Epoch=1000时,我们的损失函数都没有像标准的triplet损失那样变为0。
不同点
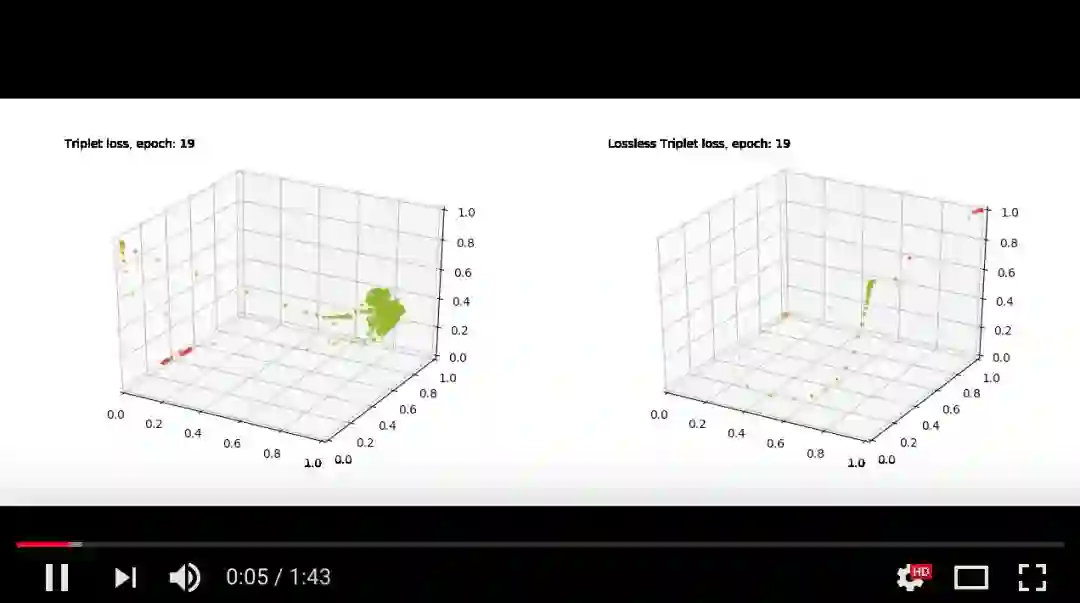
视频中,可以看到标准的triplet损失(左边)和我们的lossless triplet损失(右边)的区别。
视频链接:https://www.youtube.com/watch?v=XAH83kCJB3E
总结
lossless triplet损失看起来不错,现在我需要用更多的数据、不同的场景来测试它的健壮性。
引用
· Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. “Siamese neural networks for one-shot image recognition.” ICML Deep Learning Workshop. Vol. 2. 2015.
· Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprintarXiv:1301.3781 (2013).
· Schroff, Florian, DmitryKalenichenko, and James Philbin. “Facenet: A unified embedding for face recognition and clustering.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
· Hadsell, Raia, Sumit Chopra, and Yann LeCun. “Dimensionality reduction by learning an invariant mapping.” Computer vision and pattern recognition, 2006 IEEE computer society conference on.Vol. 2. IEEE, 2006.
· https://thelonenutblog.wordpress.com/
· https://hackernoon.com/one-shot-learning-with-siamese-networks-in-pytorch-8ddaab10340e
参考链接:
https://towardsdatascience.com/lossless-triplet-loss-7e932f990b24
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知


