2 万字全面测评深度学习框架 PaddlePaddle、TensorFlow 和 Keras | 程序员硬核评测

【CSDN 编者按】人工智能想入门深度学习?却苦恼网上的入门教程太零碎,不知道用什么框架好?本文作者用两万字手分别从百度的PaddlePaddle深度学习框架、Google的TensorFlow深度学习框架和快速实现原型的Keras框架,手把手教你学习!

作者 | 张强
责编 | 伍杏玲
今天要给大家分享一个人工智能之深度学习领域的MNIST手写数字识别入门级教程,等等?
这跟那些网上一搜一大把的MNIST入门级教程有什么区别吗?
我想说的是,还真有很大的区别!
首先这是一个针对初学者入门级的训练MNIST模型教程,因为一般我们在网上搜索的教程都是零散的,没有比较整套的代码和说明教程。
我们本篇就将MNIST教程的简单及完整的代码用百度的PaddlePaddle深度学习框架、Google的TensorFlow深度学习框架和快速实现原型的Keras框架编写而成。
特写的优点:
从MNIST原始图像数据到最后使用训练的模型进行识别
三种深度学习框架使用统一的编程方式和流程实现
不仅仅是文字型介绍它们的区别,而是直接通过代码来看
模型训练完,如何去保存模型以及以后的使用
不需要一分钱即可在国内通过打开一个URL地址,就可以训练模型,免费的CPU服务器永久时长,免费的GPU V100 16GB服务器使用
看完本篇,你也不必纠结是使用PaddlePaddle、TensorFlow还是Keras
目录
我们来看下具体的六个步骤,每个步骤都将用三种方式实现:
一.运行环境
二.下载/加载数据集
三.随机预览图像
四.创建模型
五.训练/保存模型
六.测试模型
官网
PaddlePaddle: http://paddlepaddle.org/ 是一个由百度出品的基于产业实践的开源深度学习框架平台
TensorFlow:https://www.tensorflow.org/ 是一个由Google出品的端到端的开源机器学习框架平台
Keras:https://keras.io/ 是一个对TensorFlow,CNTK,Theano的高度封装的高级神经网络的API开源框架
今天本篇的教程就是围绕着这三个开源ML/DL Framework来讲的,不管是哪一种框架都可以实现你想要的模型,MNIST就是这样的一个简单的开始。
这三种开源框架都可以创建模型、训练模型、模型推理、上线部署等等一大堆功能。以下的内容每一段都是按照PaddlePaddle代码、TensorFlow代码和Keras代码的顺序而讲。
运行环境
1、PaddlePaddle代码
import numpy as np
print(np.__version__)
1.15.4
import matplotlib
print(matplotlib.__version__)
2.2.3
import paddle
print(paddle.__version__)
1.4.0
PaddlePaddle的安装可以通过:
pip install paddlepaddle
2、TensorFlow代码
import numpy as np
print(np.__version__)
1.15.4
import matplotlib
print(matplotlib.__version__)
2.2.3
import tensorflow as tf
print(tf.__version__)
1.13.1
TensorFlow的安装可以通过:
pip install tensorflow
3、Keras代码
import matplotlib
print(matplotlib.__version__)
2.2.3
import numpy
print(numpy.__version__)
1.15.4
import tensorflow
print(tensorflow.__version__)
1.13.1
import keras
print(keras.__version__)
2.2.4
Keras的安装可以通过:
pip install keras
因为我们用的是TensorFlow后端,所以安装完keras后需要再安装TensorFlow。
下载/加载数据集
1、PaddlePaddle代码
import paddle
train = paddle.dataset.mnist.train()
test = paddle.dataset.mnist.test()
调用这个train()函数就会主动去下载MNIST的训练集图像,test()函数就是下载测试集图像。如果已经下载过了,它就会从硬盘缓存中读取图像数据
通过查看变量train,得知它返回的是一个生成器,数据类型是reader:
train()
输出
<generator object reader_creator.<locals>.reader at 0x7f4d70c77e60>
然后再看下训练集和测试集共有多少张图像:
train_imgs = [img for img in train()]
test_imgs = [img for img in test()]
print("train_length={}, test_length={}".format(len(train_imgs), len(test_imgs)))
输出
train_length=60000, test_length=10000
60000张训练集图像,10000张测试集图像。
2、TensorFlow代码
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("data/data65/", one_hot=True)
read_data_sets()函数表示去下载数据集或者从指定文件夹下加载数据集,也就是说,MNIST数据集不存在就下载,存在就直接加载。
然后读取训练集、验证集和测试集图像数据:
x_train, y_train = mnist.train.images, mnist.train.labels
x_valid, y_valid = mnist.validation.images, mnist.validation.labels
x_test, y_test = mnist.test.images, mnist.test.labels
print("训练集图像大小:{}, 标签大小:{}".format(x_train.shape, y_train.shape))
print("验证集图像大小:{},标签大小:{}".format(x_valid.shape, y_valid.shape))
print("测试集图像大小:{},标签大小:{}".format(x_test.shape, y_test.shape))
输出是:
训练集图像大小:(55000, 784), 标签大小:(55000, 10)
验证集图像大小:(5000, 784),标签大小:(5000, 10)
测试集图像大小:(10000, 784),标签大小:(10000, 10)
55000张训练集图像,5000张验证集图像,10000张测试集图像。
3、Keras代码
import keras
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
load_data()函数就是加载MNIST图像数据集,如果本地缓存不存在数据集,就主动去在线下载;存在的话,就直接加载。
然后查看训练集和测试集图像数据的个数:
print("X_train.shape={}, y_train.shape={}".format(X_train.shape, y_train.shape))
print("X_test.shape={}, y_test.shape={}".format(X_test.shape, y_test.shape))
输出:
X_train.shape=(60000, 28, 28), y_train.shape=(60000,)
X_test.shape=(10000, 28, 28), y_test.shape=(10000,)
60000张训练集图像,10000张测试集图像。
4、小结:
通过PaddlePaddle、TensorFlow和Keras加载的MNIST图像数据集基本是6万张训练集和1万张测试集,只有TensorFlow会把6万张的训练集分出去5000张给验证集。
数据集的加载方式都是通过一开始是在线下载,当第二次加载图像时就可以从本地的硬盘缓存中查找图像数据集了。
MNIST图像数据集的官网是:http://yann.lecun.com/exdb/mnist/
它的标准图像张数就是60000张用来训练,和10000张用来测试。
随机预览图像
1、PaddlePaddle代码
首先随机从训练集图像中选择5张图像:
import random
# 随机从数组中选择5张图像
random_5_imgs = random.sample(train_imgs, 5)
# PaddlePaddle读取出来的数据是由一个个元组作为数组元素
# 每个元组的第一位为图像的向量,第二位是该向量对应的标签
vector = random_5_imgs[0][0]
label = random_5_imgs[0][1]
print("vector.shape={}, label={}".format(vector.shape, label))
vectors = []
labels = []
for vector, label in random_5_imgs:
# 将每张图像向量转换成图像矩阵
vectors.append(vector.reshape((28,28)))
labels.append(label)
print("第一张图像的.shape是{}".format(vectors[0].shape))
输出:
vector.shape=(784,), label=6
第一张图像的.shape是(28, 28)
然后使用matplotlib绘图输出:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
# 创建一个10x5大小的绘图对象
fig = plt.figure(figsize=(10, 5))
# 遍历5次,因为我们只随机选择了5张图像,
# 所以这里显示的图像取决于每次随机的图像而变化
# 每次的图像显示的肯定不一样
for i in range(5):
ax = fig.add_subplot(1, 5, i+1, xticks=[], yticks=[])
ax.imshow(np.reshape(vectors[i:i+1], (28, 28)), cmap='gray')
print("图像对应的标签是{}。".format(labels))
输出:

2、TensorFlow代码
我们就从训练集图像中选择5张图像,这里选择的图像索引位置从10到15:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
# 创建一个10x5大小的绘图对象
fig = plt.figure(figsize=(10, 5))
# 遍历5次,因为我们只随机选择了5张图像,
# 所以这里显示的图像取决于每次随机的图像而变化
# 每次的图像显示的肯定不一样
for i in range(5):
ax = fig.add_subplot(1, 5, i+1, xticks=[], yticks=[])
ax.imshow(np.reshape(vectors[i:i+1], (28, 28)), cmap='gray')
print("图像对应的标签是{}。".format(labels))
输出:

3、Keras代码
我们就从训练集图像中选择5张图像,这里选择的图像索引位置从0到4:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
fig = plt.figure(figsize=(10, 10))
for i in range(5):
ax = fig.add_subplot(1, 5, i+1)
ax.imshow(np.reshape(X_train[i:i+1], (28, 28)), cmap='gray')
输出:
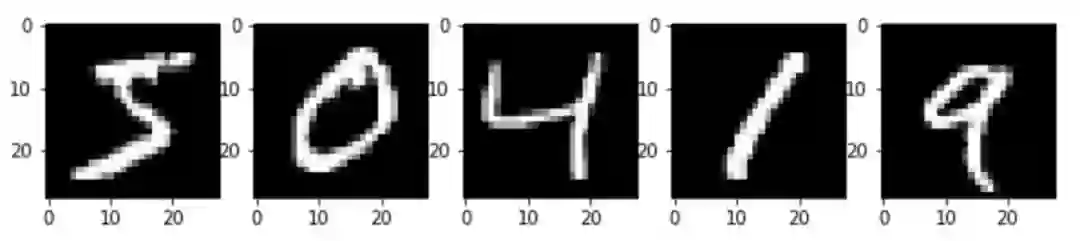
创建模型
1、PaddlePaddle代码
import paddle.fluid as fluid
import numpy as np
# 表示0到9的共10个数字,就是10个类别
num_classes = 10
# 我们使用CPU来训练模型
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# 输入的原始图像数据,大小为28*28*1
X = fluid.layers.data(name="img", shape=[1, 28, 28], dtype=np.float32)
# 输入的原始图像数据的标签
y = fluid.layers.data(name="label", shape=[1], dtype=np.int64)
# 创建输出层,以softmax为激活函数的全连接层,输出层的大小必须为数字的个数10
# fc表示全连接层(fully connected layer)
predict = fluid.layers.fc(input=X, size=num_classes, act="softmax")
# 使用类交叉熵函数计算predict和y之间的损失函数
cost = fluid.layers.cross_entropy(input=predict, label=y)
# 计算平均损失
avg_loss = fluid.layers.mean(cost)
# 计算分类准确率
acc = fluid.layers.accuracy(input=predict, label=y)
# 告知网络传入的数据分为两部分,第一部分是img值X,第二部分是label值y
feeder = fluid.DataFeeder(feed_list=[X, y], place=place)
# 选择Adam优化器,使损失最小化
optimizer = fluid.optimizer.Adam(learning_rate=0.001).minimize(avg_loss)
2、TensorFlow代码
# 超参数准备
img_size = 28 * 28
num_classes = 10
learning_rate = 0.1
# 创建模型
# x表示输入,创建输入占位符,该占位符会在训练时,会对每次迭代的数据进行填充上
x = tf.placeholder(tf.float32, [None, img_size])
# W表示weight,创建权重,初始化时都是为0,它的大小是(图像的向量大小,图像的总类别)
W = tf.Variable(tf.zeros([img_size, num_classes]))
# b表示bias,创建偏移项
b = tf.Variable(tf.zeros([num_classes]))
# y表示计算输出结果,softmax表示激活函数是多类别分类的输出
# 感知器的计算公式就是:(x * W) + b
y = tf.nn.softmax(tf.matmul(x, W) + b)
# 定义输出预测占位符y_
y_ = tf.placeholder(tf.float32, [None, 10])
# 通过激活函数softmax的交叉熵来定义损失函数
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
# 定义梯度下降优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
# 比较正确的预测结果
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
# 计算预测准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
3、Keras代码
因为Keras将MNIST图像数据集加载到内存时是原生的图像数据,没有经过任何预处理,而PaddlePaddle和TensorFlow在加载时就做了处理。
所以这里我们需要将Keras加载的数据做预处理。
分割测试集为一半是验证集,另一半是测试集:
valid_len = int(X_test.shape[0] / 2)
X_valid = X_test[:valid_len]
y_valid = y_test[:valid_len]
X_test = X_test[valid_len:]
y_test = y_test[valid_len:]
print("X_train.shape={}, y_train.shape={}".format(X_train.shape, y_train.shape))
print("X_valid.shape={}, y_valid.shape={}".format(X_valid.shape, y_valid.shape))
print("X_test.shape={}, y_test.shape={}".format(X_test.shape, y_test.shape))
输出:
X_train.shape=(60000, 28, 28), y_train.shape=(60000,)
X_valid.shape=(5000, 28, 28), y_valid.shape=(5000,)
X_test.shape=(5000, 28, 28), y_test.shape=(5000,)
图像数据预处理:
import numpy as np
img_size = 28 * 28
num_classes = 10
# 将训练集、验证集和测试集数据进行图像向量转换
X_train = X_train.reshape(X_train.shape[0], img_size)
X_valid = X_valid.reshape(X_valid.shape[0], img_size)
X_test = X_test.reshape(X_test.shape[0], img_size)
# 将训练集、验证集和测试集数据都转换成float32类型
X_train = X_train.astype(np.float32)
X_valid = X_valid.astype(np.float32)
X_test = X_test.astype(np.float32)
# 将训练集、验证集和测试集数据都转换成0到1之间的数值,就是归一化处理
X_train /= 255
X_valid /= 255
X_test /= 255
# 通过to_categorical()函数将训练集标签、验证集标签和测试集标签独热编码(one-hot encoding)
y_train = keras.utils.to_categorical(y_train, num_classes)
y_valid = keras.utils.to_categorical(y_valid, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
创建Keras的多层感知器模型:
from keras import Sequential
from keras.layers import Dense, Dropout
# 创建Sequential模型
model = Sequential()
# 创建输入层,有512个深度,必须要传的参数是input_shape,它表示输入的图像的大小
model.add(Dense(512, activation='relu', input_shape=(img_size,)))
model.add(Dropout(0.2))
# 创建一个隐藏层,也有512个深度
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
# 添加输出层,因为有10个类别的概率输出,所以使用softmax
model.add(Dense(num_classes, activation='softmax'))
# 模型架构预览
model.summary()
输出:
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 512) 401920
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 5130
=================================================================
Total params: 669,706
Trainable params: 669,706
Non-trainable params: 0
_________________________________________________________________

训练/保存模型
1、PaddlePaddle代码
首先创建执行器、主程序和测试程序:
# 创建执行器
executor = fluid.Executor(place)
executor.run(fluid.default_startup_program())
# 设置 main_program 和 test_program
main_program = fluid.default_main_program()
test_program = fluid.default_main_program().clone(for_test=True)
然后创建一个在训练模型时定期评估模型的函数test_loss_acc():
def test_loss_acc(test_program, test_reader, test_feeder):
"""
在训练模型时,计算测试集的损失值和精确度
"""
loss_arr = []
accuracy_arr = []
# 开始迭代测试loss和acc
for test_data in test_reader():
# 在Paddle中推理计算loss和acc
_loss, _acc = executor.run(test_program,
feed=test_feeder.feed(test_data),
fetch_list=[avg_loss, acc])
loss_arr.append(float(_loss))
accuracy_arr.append(float(_acc))
# 获得测试数据集上的准确率和损失值的均值
loss_mean = np.array(loss_arr).mean()
accuracy_mean = np.array(accuracy_arr).mean()
return loss_mean, accuracy_mean
将数据集分成多个batch,根据计算得来。
通过batch返回数据集的总数量除以64的每批次数,所以:
训练集的batch的数量就是 60000 / 64 = 937.5 向上取整等于938。
测试集的batch的数量就是 10000 / 64 = 156.25 向上取整等于157。
BATCH_SIZE = 64
train_reader = paddle.batch(paddle.reader.shuffle(train, buf_size=500), batch_size=BATCH_SIZE)
test_reader = paddle.batch(paddle.reader.shuffle(test, buf_size=500), batch_size=BATCH_SIZE)
train_reader_length = len([1 for _ in train_reader()])
test_reader_length = len([1 for _ in test_reader()])
print("train_reader分了{}个batch,test_reader分了{}个batch。".format(train_reader_length, test_reader_length))
输出:
train_reader分了938个batch,test_reader分了157个batch。
训练模型
我们通过5个epoch就可以训练出一个Accuracy还不错的模型;
在训练模型期间,总是保存模型到指定路径,即saved_model_filename变量;
在每训练100个进度的时候,我们打印一次日志显示它的训练效果,训练集和测试的loss和acc;
最后训练完,我们也通过fluid.io.save_inference_mode()函数将模型保存了起来。
epochs = 5
saved_model_filename = "mnist.inference.model"
result_arr = []
step = 0
# 开始迭代训练模型
for epoch_id in range(epochs):
# 遍历训练集数据
for step_i, data in enumerate(train_reader()):
# 训练模型
metrics = executor.run(main_program,
feed=feeder.feed(data),
fetch_list=[avg_loss, acc])
# 每训练100次打印一次日志
if step % 100 == 0:
loss_train, accuracy_train = metrics[0][0], metrics[1][0]
print("Train Epoch {}, step_i {}, loss {}, acc {}".format(epoch_id,
step,
metrics[0][0],
metrics[1][0]))
# 评估测试集的分类效果
loss_val, accuracy_val = test_loss_acc(test_program, test_reader, feeder)
print("Valid Epoch {}, step_i {},loss {},acc {}".format(epoch_id,
step,
loss_val,
accuracy_val))
step += 1
result_arr.append((epoch_id, loss_val, accuracy_val, loss_train, accuracy_train))
# 保存训练好的模型参数用于预测
fluid.io.save_inference_model(saved_model_filename,
["img"],
[predict],
executor,
model_filename=None,
params_filename=None)
输出:
Train Epoch 0, step_i 0, loss 3.662783145904541, acc 0.0625
Valid Epoch 0, step_i 0,loss 0.9381991980751608,acc 0.7200437898089171
Train Epoch 0, step_i 100, loss 0.4590408504009247, acc 0.890625
......
Train Epoch 4, step_i 4500, loss 0.350452721118927, acc 0.90625
Valid Epoch 4, step_i 4500,loss 0.19813986520051577,acc 0.9416799363057324
Train Epoch 4, step_i 4600, loss 0.1873813271522522, acc 0.9375
Valid Epoch 4, step_i 4600,loss 0.19667905686529957,acc 0.9430732484076433
最后一次训练获得了训练集精确度是93.75%,验证集精确度是94.30%,
然后我们看下整个训练过程的loss和acc的绘图。
先获取最佳的loss和acc:
best_predict = sorted(result_arr, key=lambda ele:float(ele[1]))[0]
print("Valid Loss {}, Acc {:.5f}%.".format(best_predict[1], float(best_predict[2])*100))
print("Train Loss {}, Acc {:.5f}%.".format(best_predict[3], float(best_predict[4])*100))
输出:
Valid Loss 0.19667905686529957, Acc 94.30732%.
Train Loss 0.1873813271522522, Acc 93.75000%.
绘图显示:
import matplotlib.pyplot as plt
%matplotlib inline
# 将训练时记录的loss和acc的数组的每一列都取出来
result_np = np.array(result_arr)
# 索引为1的就是验证集loss
loss_val = result_np[:,1]
# 索引为2的就是验证集的acc
accuracy_val = result_np[:,2]
# 索引为3的就是训练集loss
loss_train = result_np[:,3]
# 索引为4的就是训练集acc
accuracy_train = result_np[:,4]
# 绘制训练集和验证集的损失值
plt.plot(loss_train)
plt.plot(loss_val)
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# 绘制训练集和验证集的精确度
plt.plot(accuracy_val)
plt.plot(accuracy_train)
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
输出:
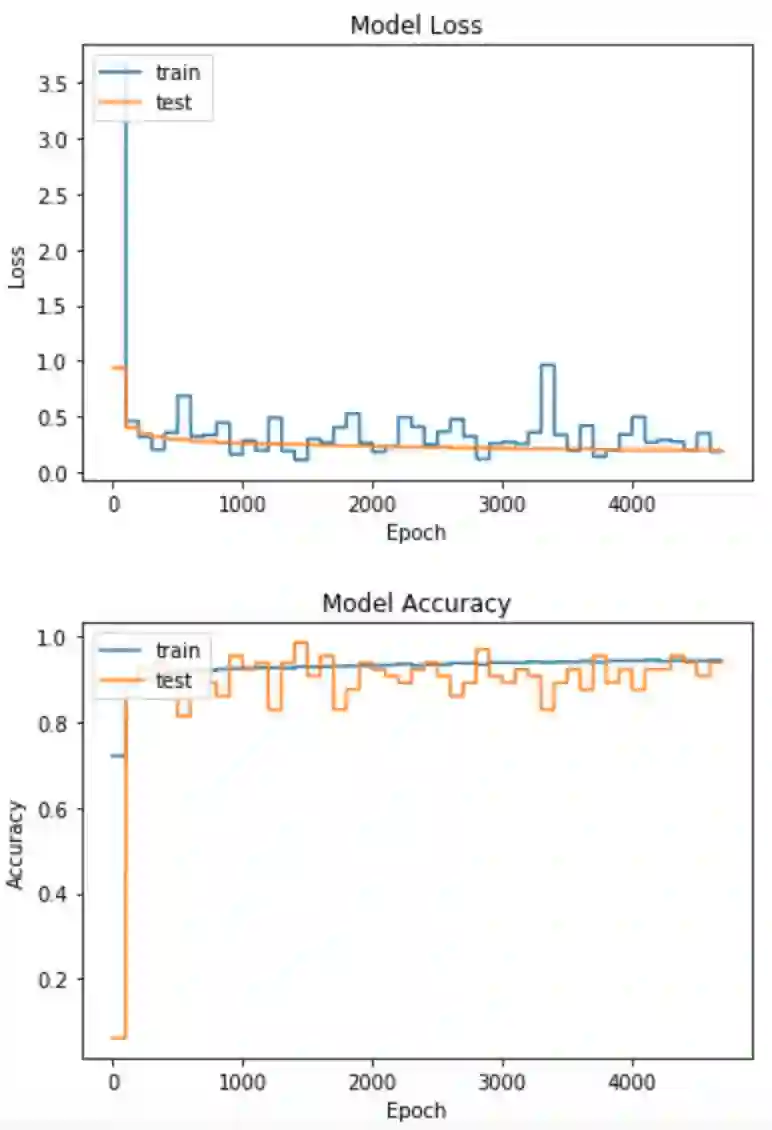
2、TensorFlow代码
我们使用了100个epoch来训练所有的图像数据集,每个batch分成了128个大小。
跟PaddlePaddle一样,通过两次for循环,外循环是来训练在一次epoch内,所有的MNIST图像都需要训练一遍,然后共训练100次;内循环是来将一个epoch,所有的MNIST图像,根据batch_size大小分成多个批次,来一批次批次的训练。
最后将训练好的模型检查点通过saver.save()函数保存到本地硬盘:
import math
epochs = 100
batch_size = 128
iteration = 0
# 定义训练时的检查点
saver = tf.train.Saver()
valid_feed_dict = { x: x_valid, y_: y_valid }
test_feed_dict = { x: x_test, y_: y_test }
history_train = []
history_valid = []
# 创建一个TensorFlow的会话
with tf.Session() as sess:
# 初始化全局变量
sess.run(tf.global_variables_initializer())
# 根据每批次训练128个样本,计算出一共需要迭代多少次
batch_count = int(math.ceil(mnist.train.labels.shape[0] / 128.0))
# 开始迭代训练样本
for e in range(epochs):
# 每个样本都需要在TensorFlow的会话里进行运算,训练
for batch_i in range(batch_count):
# 样本的索引,间隔是128个
batch_start = batch_i * batch_size
# 取出图像样本
batch_x = mnist.train.images[batch_start:batch_start+batch_size]
# 取出图像对应的标签
batch_y = mnist.train.labels[batch_start:batch_start+batch_size]
# 训练模型
loss, acc, _ = sess.run([cost, accuracy, optimizer], feed_dict={x: batch_x, y_: batch_y})
# 每100个批次时输出一次训练损失等日志信息
if batch_i % 100 == 0:
print("Epoch: {}/{}".format(e+1, epochs),
"Iteration: {}".format(iteration),
"Train loss: {:.5f}".format(loss),
"Train acc: {:.5f}".format(acc))
history_train.append((iteration, loss, acc))
iteration += 1
# 每128个样本时,验证一下训练的效果如何,并输出日志信息
if iteration % batch_size == 0:
valid_loss, valid_acc = sess.run([cost, accuracy], feed_dict=valid_feed_dict)
print("Epoch: {}/{}".format(e, epochs),
"Iteration: {}".format(iteration),
"Valid Loss: {:.5f}".format(valid_loss),
"Valid Acc: {:.5f}".format(valid_acc))
history_valid.append((iteration, valid_loss, valid_acc))
# 保存训练模型的检查点
saver.save(sess, "checkpoints/mnist_mlp_tf.ckpt")
输出:
Epoch: 1/100 Iteration: 0 Train loss: 2.30259 Train acc: 0.11719
Epoch: 1/100 Iteration: 100 Train loss: 2.08399 Train acc: 0.50781
Epoch: 0/100 Iteration: 128 Valid Loss: 1.97898 Valid Acc: 0.63220
......
Epoch: 100/100 Iteration: 42870 Train loss: 1.50794 Train acc: 0.96875
Epoch: 99/100 Iteration: 42880 Valid Loss: 1.54402 Valid Acc: 0.92800
Epoch: 100/100 Iteration: 42970 Train loss: 1.57890 Train acc: 0.89062
最后一次训练获得了训练集精确度是89.06%,验证集精确度是92.80%。然后我们将训练时记录的loss和acc绘图出来:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
# 绘制训练集和验证集的损失值
plt.plot(np.array(history_train)[:,1])
plt.plot(np.array(history_valid)[:,1])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# 绘制训练集和验证集的精确度
plt.plot(np.array(history_train)[:,2])
plt.plot(np.array(history_valid)[:,2])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
输出:
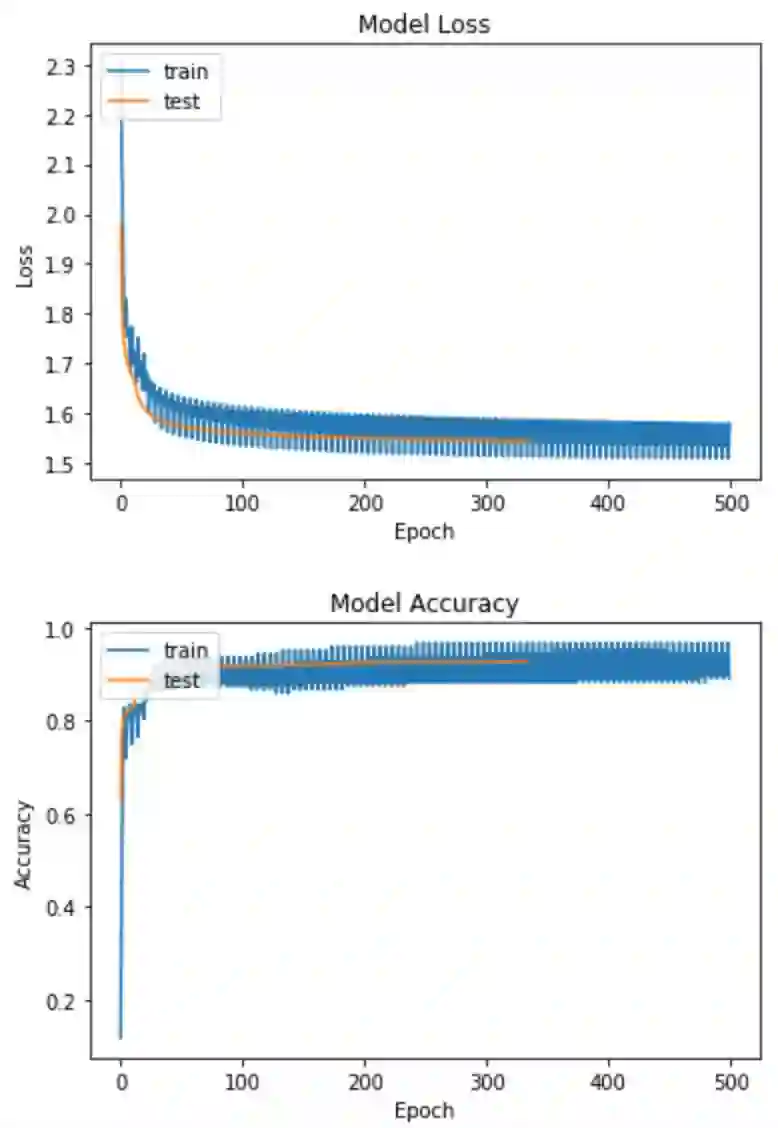
3、Keras代码
先编译模型,编译模型时,指定优化器、损失函数和度量方式的参数:
from keras.optimizers import RMSprop
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])
然后训练模型:
epochs = 20
batch_size = 128
history = model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1, validation_data=(X_valid, y_valid))
输出:
Train on 60000 samples, validate on 5000 samples
Epoch 1/20
60000/60000 [==============================] - 9s 150us/step - loss: 0.2438 - acc: 0.9242 - val_loss: 0.1313 - val_acc: 0.9592
Epoch 2/20
60000/60000 [==============================] - 9s 146us/step - loss: 0.1012 - acc: 0.9691 - val_loss: 0.1032 - val_acc: 0.9692
Epoch 3/20
......
60000/60000 [==============================] - 9s 146us/step - loss: 0.0190 - acc: 0.9948 - val_loss: 0.1506 - val_acc: 0.9756
Epoch 19/20
60000/60000 [==============================] - 9s 145us/step - loss: 0.0174 - acc: 0.9953 - val_loss: 0.1456 - val_acc: 0.9776
Epoch 20/20
60000/60000 [==============================] - 9s 152us/step - loss: 0.0182 - acc: 0.9955 - val_loss: 0.1736 - val_acc: 0.9758
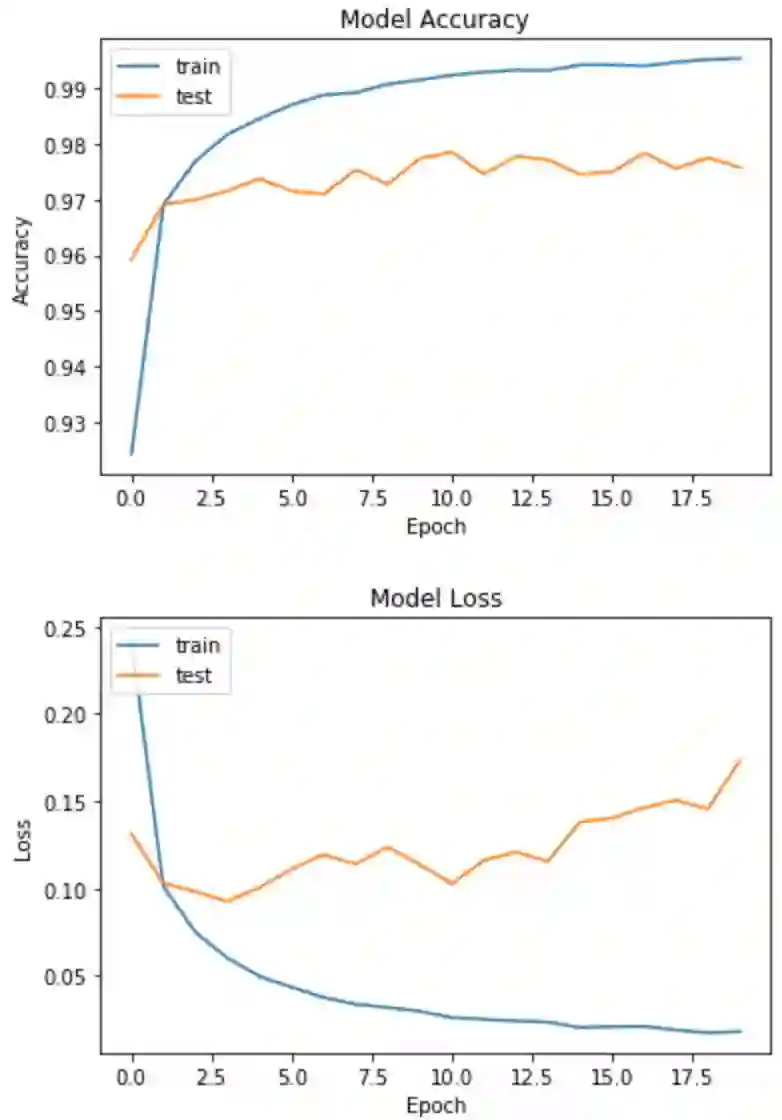
最后一次训练获得了训练集精确度是99.55%,验证集精确度是97.58%。然后我们将训练时记录的loss和acc绘图出来:
import matplotlib.pyplot as plt
%matplotlib inline
# 绘制训练集和验证集的精确度
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# 绘制训练集和验证集的损失值
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
输出:
测试模型
1、PaddlePaddle代码
比如我们选择一张图像,看看它是几?
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img_matrix = next(train())[0].reshape(28, 28)
img_label = next(train())[1]
imgplot = plt.imshow(img_matrix, cmap="gray")
plt.show()
print("这张图像的标签是{}。".format(img_label))
输出:
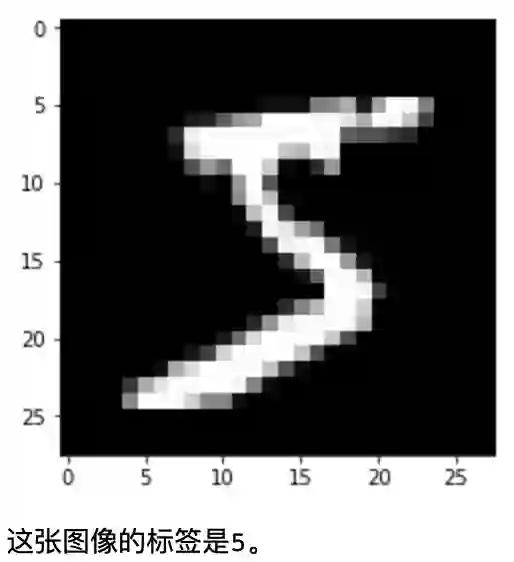
然后推理这张图像是多少。首先创建执行器,然后把上面训练的模型文件加载进来,再通过run()函数来推理计算识别到的概率。
最后推理出来的概率是标签5,跟真实的标签一致,这就完全正确!
# 创建执行器
test_executor = fluid.Executor(place)
test_executor.run(fluid.default_startup_program())
inference_scope = fluid.core.Scope()
with fluid.scope_guard(inference_scope):
# 加载模型
[inference_program, feed_target_names, fetch_targets] = \
fluid.io.load_inference_model(saved_model_filename, test_executor, None, None)
# 运行推理图像
results = test_executor.run(inference_program,
feed={feed_target_names[0]: img_matrix.reshape(1,1,28,28)},
fetch_list=fetch_targets)
# 预测的标签
predicted_label = np.argmax(results[0][0])
# 预测概率
predicted_prob = max(results[0][0])
print("Accuracy = {}, Label = {}".format(predicted_prob, predicted_label))
输出
Accuracy = 0.9278314113616943, Label = 5
2、TensorFlow代码
假设我们就读取测试集中索引为21的图像,看看它是几?
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
target_label_index = 21
index_21_img = x_test[target_label_index].reshape(28, 28)
imgplot = plt.imshow(index_21_img, cmap="gray")
plt.show()
输出:
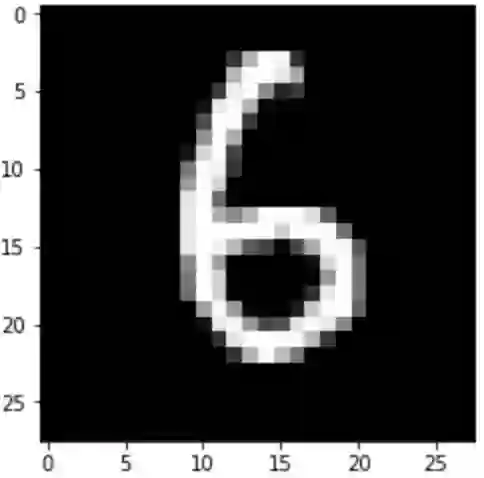
它对应的标签是多少了?
target_label_arr = y_test[target_label_index]
target_label = np.argmax(target_label_arr)
print("索引为21的图像是数字{}。".format(target_label))
输出:索引为21的图像是数字6。
然后推理计算,将模型检查点文件加载进来,构建计算图,然后从模型架构中所有的operation中查找最后的分类器,因为我们的模型最后一层是softmax激活函数,所以我们通过graph.get_operations()函数遍历出来,找到Softmax那一层,将它读取出来,就是我们要放到run()函数的第一个参数,即classifier。
最后得到的预测是数字6,完全正确!
checkpoint_file = tf.train.latest_checkpoint("checkpoints")
graph = tf.get_default_graph()
with graph.as_default():
sess = tf.Session()
with sess.as_default():
saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
saver.restore(sess,checkpoint_file)
# for op in graph.get_operations():
# print(op.name)
softmax_classifer = graph.get_operation_by_name("Softmax").outputs[0]
index_10_img_to_predict = x_test[target_label_index].reshape((1, 784))
predicted_result = sess.run([softmax_classifer], feed_dict={x: index_10_img_to_predict})
print(predicted_result)
print("预测的数字是{}。".format(np.argmax(predicted_result)))
输出
INFO:tensorflow:Restoring parameters from checkpoints/mnist_mlp_tf.ckpt
[array([[1.6478752e-07, 1.8716774e-10, 1.4367420e-05, 7.6656121e-08,
7.3713923e-06, 2.4220503e-04, 9.9968493e-01, 6.0247163e-13,
5.0681083e-05, 1.7343659e-07]], dtype=float32)]
预测的数字是6。
3、Keras代码
假设我们就读取测试集中索引为10的图像,看看它是几?
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
index_10_img = X_test[10].reshape(28, 28)
imgplot = plt.imshow(index_10_img, cmap="gray")
plt.show()
输出:
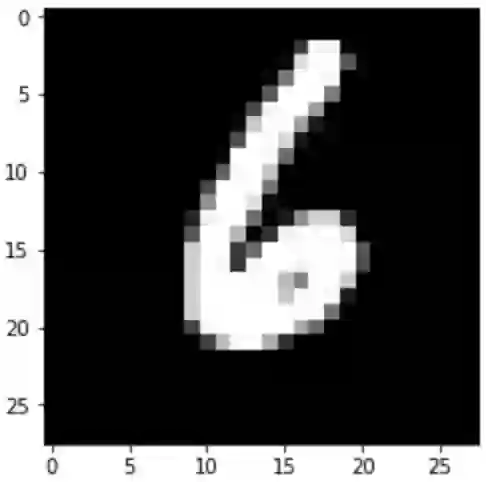
然后看下这张图像的真实标签是多少:
target_label_arr = y_test[10]
target_label = np.argmax(target_label_arr)
print("索引为10的图像是数字{}。".format(target_label))
输出:
索引为10的图像是数字6。
最后使用Keras来的模型predict()函数来计算概率,跟真实的标签是一致的,模型预测的完全正确!
index_10_img_to_predict = X_test[10].reshape((1, 784))
predictions = model.predict(index_10_img_to_predict)
print("预测的结果是{}。".format(np.argmax(predictions[0])))
输出:
预测的结果是6。
总结
一开始我们通过PaddlePaddle、TensorFlow和Keras各自的API读取MNIST数据集,然后又各自预览了5张随机图像,然后就创建神经网络模型,PaddlePaddle和TensorFlow都是一层神经网络模型,而Keras是三层神经网络模型。
然后我们通过各自的API来训练模型,PaddlePaddle和TensorFlow都是能高度自定义模型的,所以代码略微多;而Keras训练模型就比较简单,通过一个fit()函数就能完成。
接着,对于三种模型,我们在训练时记录了它们的loss和acc,所以就绘图展示了各自的训练表现。
最后,我们将各自训练的模型都通过任意选择一张图片来识别它是数字几,概率是多少?
关于本篇的三个代码文件,可以去百度AI Studio上上手操作,地址是:
https://aistudio.baidu.com/aistudio/#/education/teacher/dashboard
登录后,进入这个2019年的班级,在线训练模型,显示的有效期时间是5月份,其实这个是平台的限制,我会将这个时间调整始终有效,它快到时间了我们再次增加/调整时间。
作者简介:张强,CSDN博客专家,现任特拉字节(北京)科技有限公司创始人兼CTO,曾任职奇虎360企业安全集团蓝信团队高级研发工程师,知乎主前端高级研发工程师,多家国内一线互联网知名企业任职研发部门。
【END】

作为码一代,想教码二代却无从下手:
听说少儿编程很火,可它有哪些好处呢?
孩子多大开始学习比较好呢?又该如何学习呢?
最新的编程教育政策又有哪些呢?
下面给大家介绍CSDN新成员:极客宝宝(ID:geek_baby)
戳他了解更多↓↓↓

热 文 推 荐
☞ 移动互联网这十年
☞ 调查 10,000 名学生开发者:65% 自学成才,学 6 门编程语言!
☞ 独家! 币安被盗原因找到了! 7074枚比特币竟是这样丢掉的
☞ 补偿100万?Oracle裁900+程序员,新方案已出!