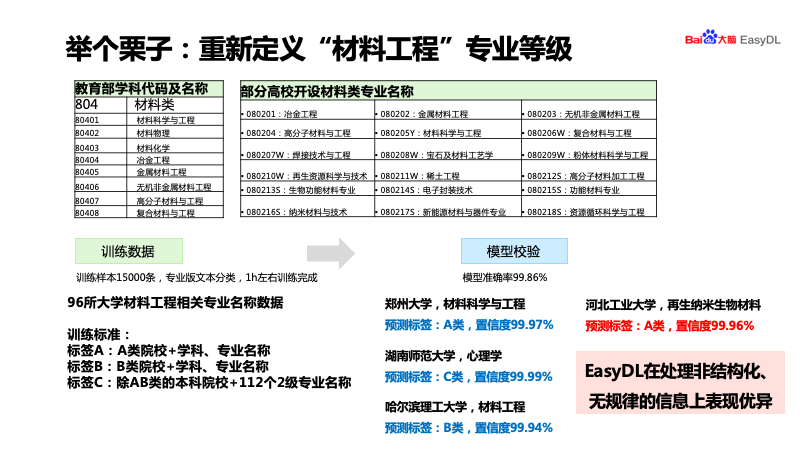
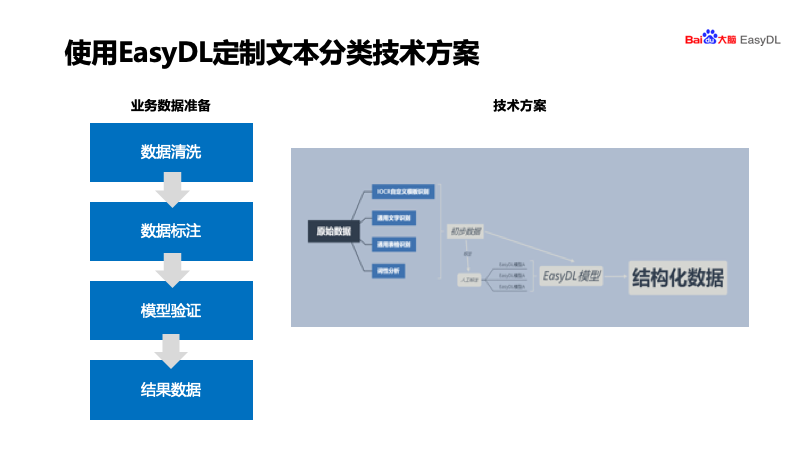
学会智能标注与海量复杂文本分类

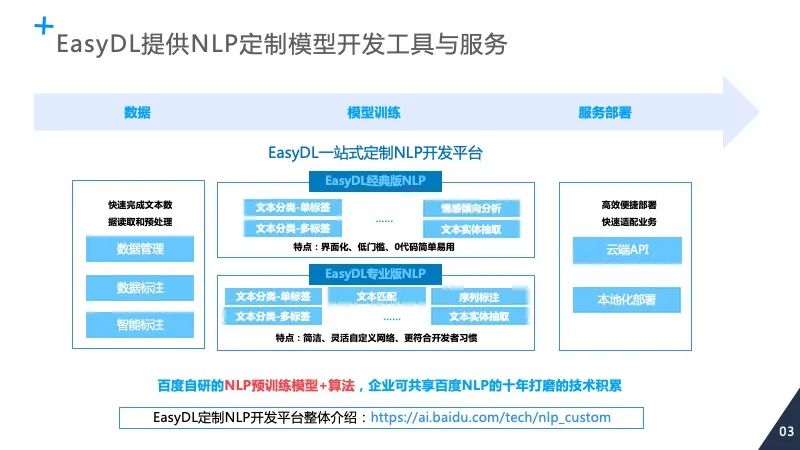
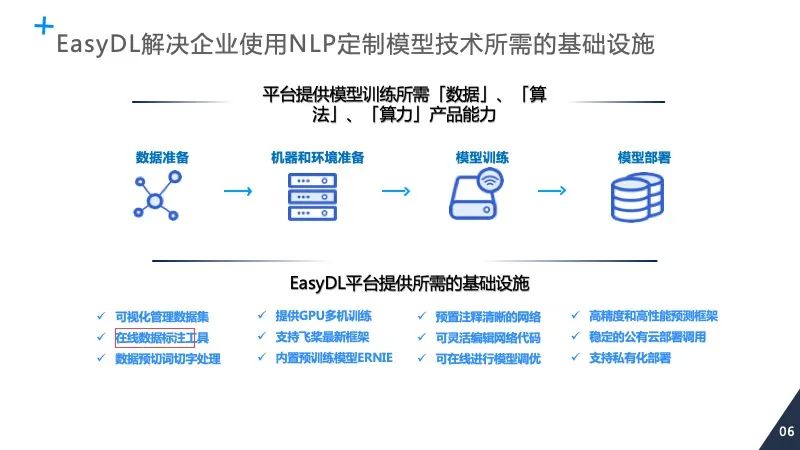
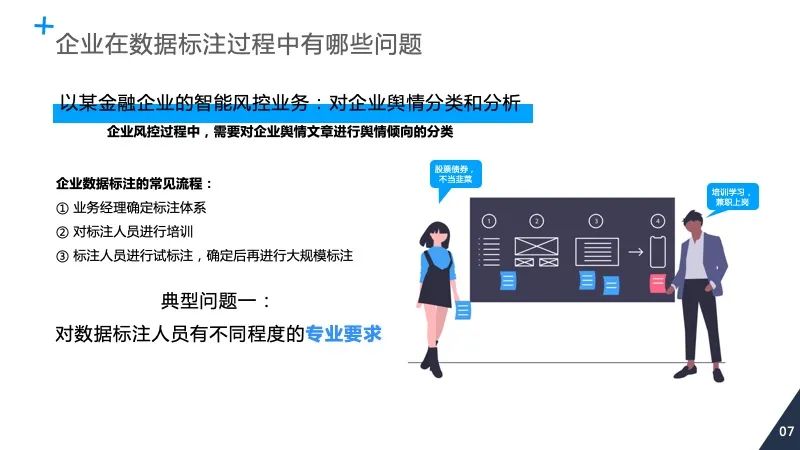
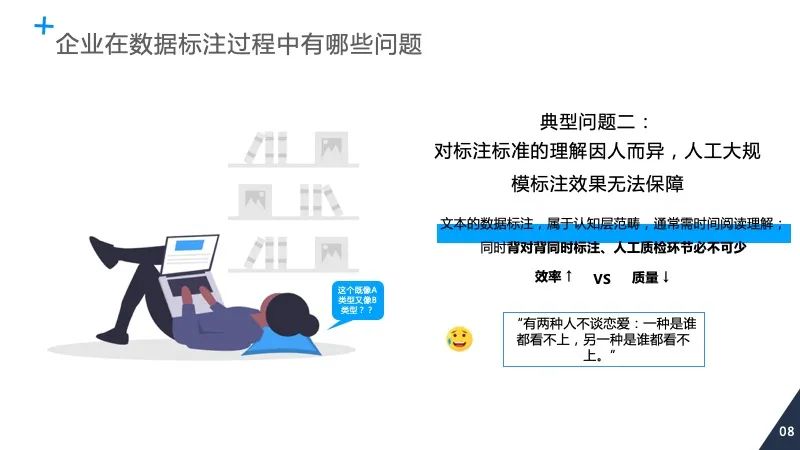

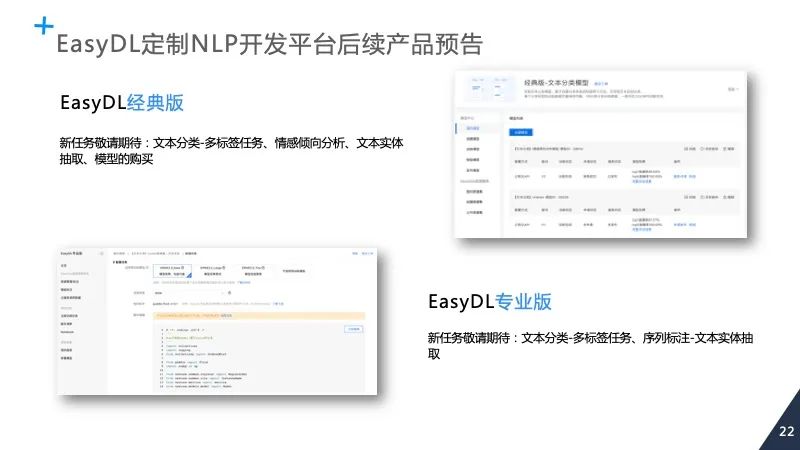


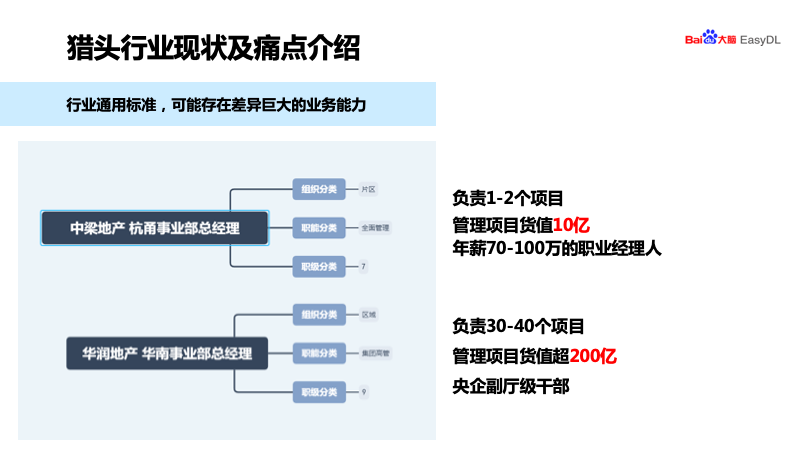
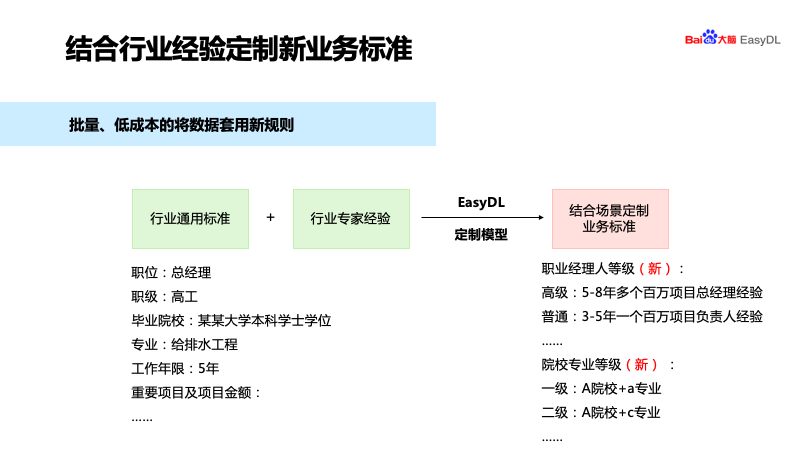
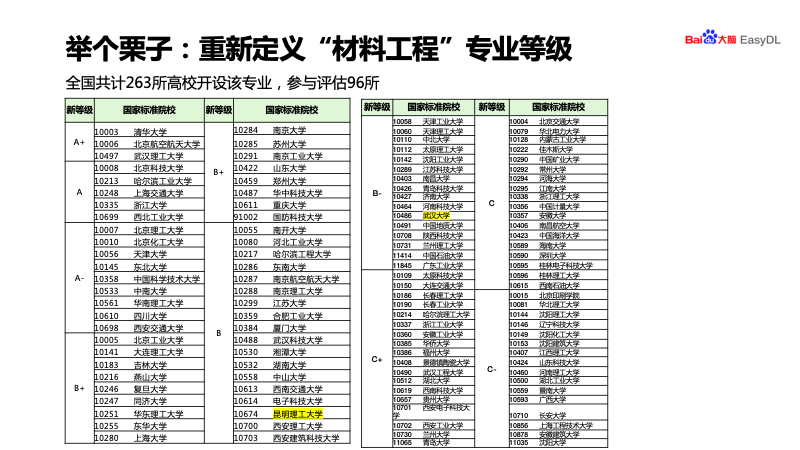




登录查看更多
相关内容

Arxiv
4+阅读 · 2019年10月29日
Arxiv
4+阅读 · 2018年10月15日



相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年10月29日
Arxiv
4+阅读 · 2018年10月15日