2020 年了,深度学习接下来到底该怎么走?

作者 | Ajit Rajasekharan
编译 | 亚希伯恩•菲
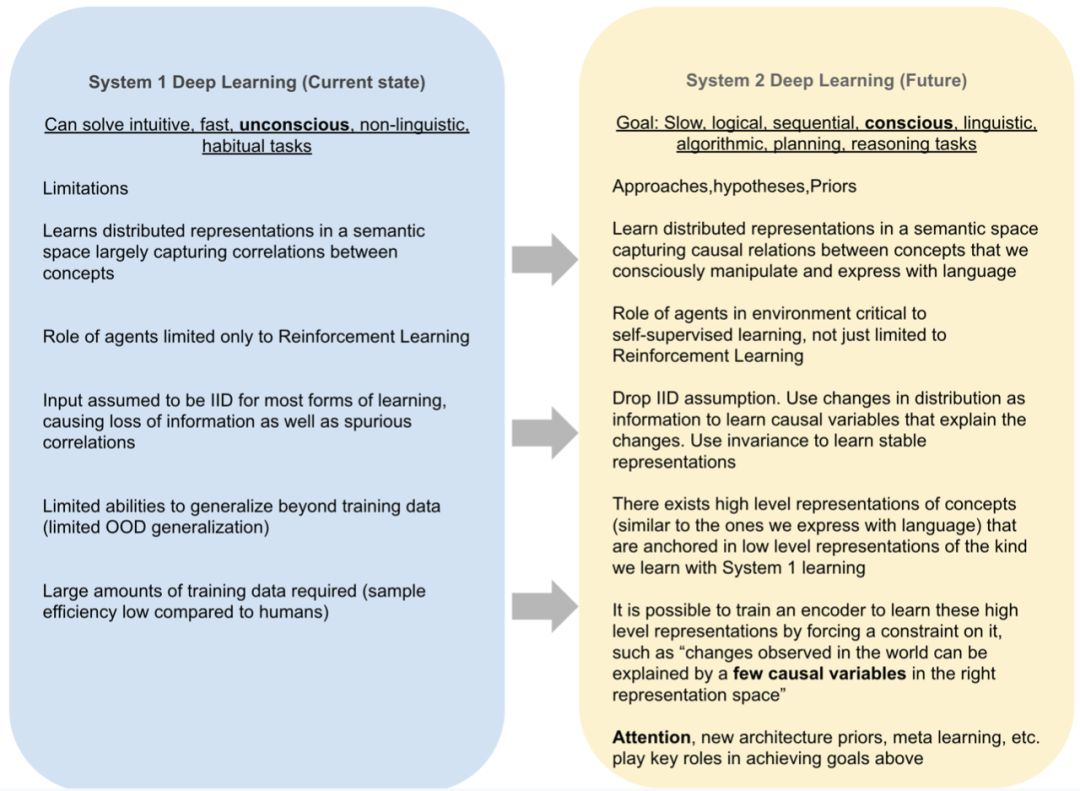
一、深度学习1.0 的局限性

二、如何实现接近人类水平的 AI ?
自监督学习:
通过预测输入进行学习
利用分布式表示的组合能力
去掉IID(独立同分布)随机变量假设
两种自监督表示学习方法
注意力机制的作用
多时间尺度的终身学习
架构先验

大脑大约有1014个突触,而我们仅能存活109秒。 这启发了人类肯定需要大量无监督学习的想法。 因为感官输入是我们能获得每秒105维度约束的唯一处所。
它提供了更多的反馈数据(由于重构类型不同,反馈即使不是关于全部输入数据,也是关于输入数据的一部分),而典型的监督学习(反馈是类别值或对每个输入的几个数字)或强化学习(反馈是对模型预测的标量奖励)的反馈数据较少。
来自环境的传感器数据流是非平稳的。这会迫使学习器,更具体地是嵌入在学习器中的编码器,去学习对象的稳定表示以及在不断变化的环境中基本不变的概念。环境固有的非平稳性也为学习变化的原因提供了机会。分布外泛化(预测事件未在训练分布中出现)和因果关系习得对于学习器做出生存必需的预测至关重要。本质上,环境的非平稳性通过不断评估和完善概念的表示和概念之间的因果关系为持续学习提供了机会。
传感器流包括在学习中起关键作用的智能体(包括学习器在内)。智能体是环境的组成部分,并通过干预来改变环境。在 DL 1.0 中,仅将智能体纳入强化学习中。DL 2.0 模型要实现其目标,将智能体纳入自监督学习中可能是重要的一步。即使是被动的学习者(例如新生儿),在刚出生的几个月里,也主要通过观察环境中其他主体的交互作用来学习。
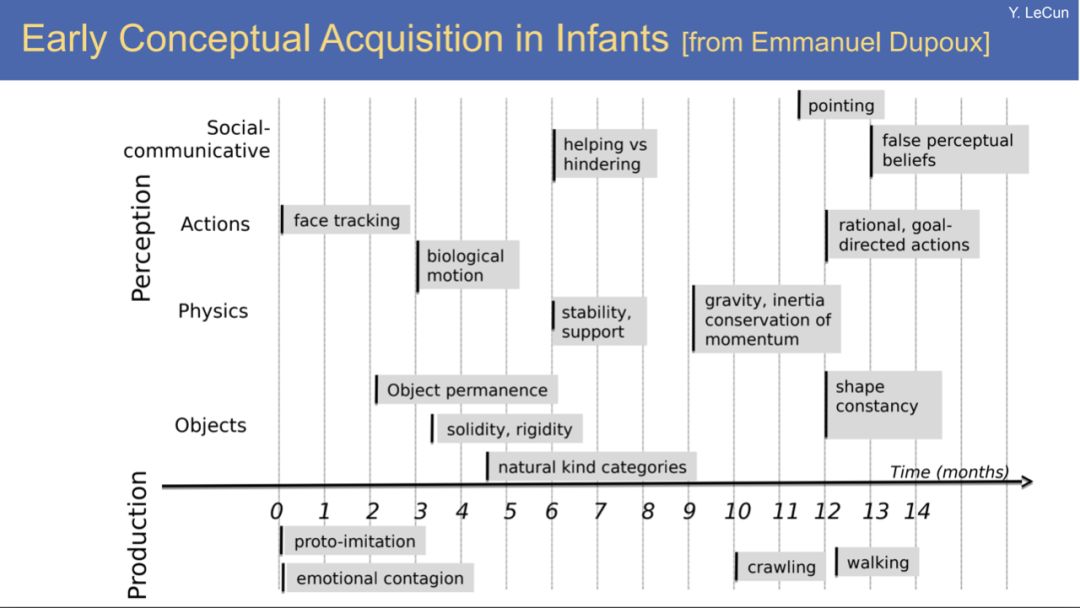
学习捕获因果关系的概念的稳定表示,使学习者能够在其计算能力之内通过模拟合理的动作序列来预测未来的几个时间步长的序列,并规划未来的动作,以趋利避害(例如学开车时避免在下山时冲下悬崖)。
分布式表示的每个特征可以参与所有概念的表示,从而实现指数组合。特征组成的表示是自动学得的。将分布式表示可视化为实值(浮点数/双精度数)向量可使其变得具体。向量可以是稠密的(大多数分量具有非零值)或稀疏的(大多数分量为零,最极端情况是独热向量)。
DL 模型的每一计算层都可进一步组合,每层的输出是前一层输出的组合。DL 1.0模型充分利用了这种组合性来学习具有多个层次的表示(例如,NLP模型学会在不同层中捕获不同层面上的句法和语义相似性)
语言具有 DL 1.0 尚未完全利用的其他可组合级别。例如,语言能编写出不可能从训练分布中提取的原创句子,也就是说不仅仅是在训练分布中出现的概率很小,出现概率甚至可能为零。这是一种比分布外(OOD)泛化更进一步的系统化泛化。最近的语言模型可以生成连贯的新颖文章,具有很高的独创性,但模型缺乏对基本概念的理解,特别是当这些文章由诸如工程概念组成时。如前所述,这种缺陷可能在一定程度上是由于缺乏扎实的语言理解,并且可能在DL 2.0中得以克服。
组合性无需仅限于创造新的句子,如下图所示,它也可以是先前概念的原创性组成(尽管语言在某种程度上可以用于描述任何概念)。

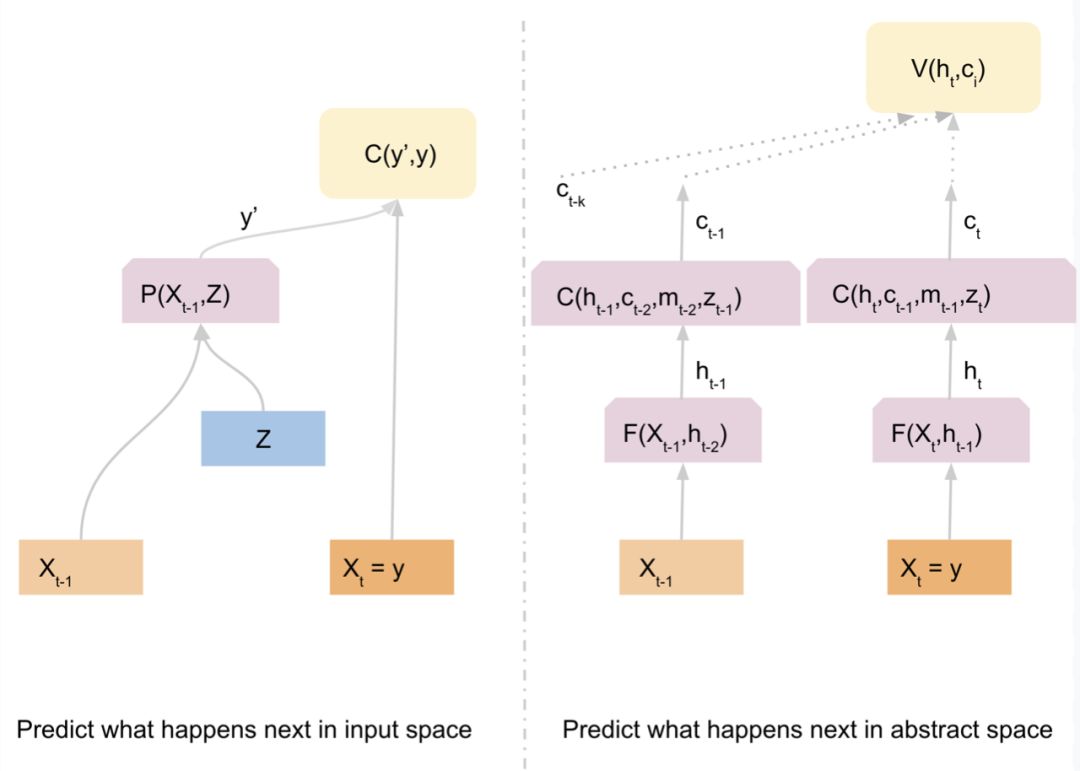
在输入空间中预测接下来会发生什么。
在抽象空间中预测接下来会发生什么。
注意力集中在哪里?
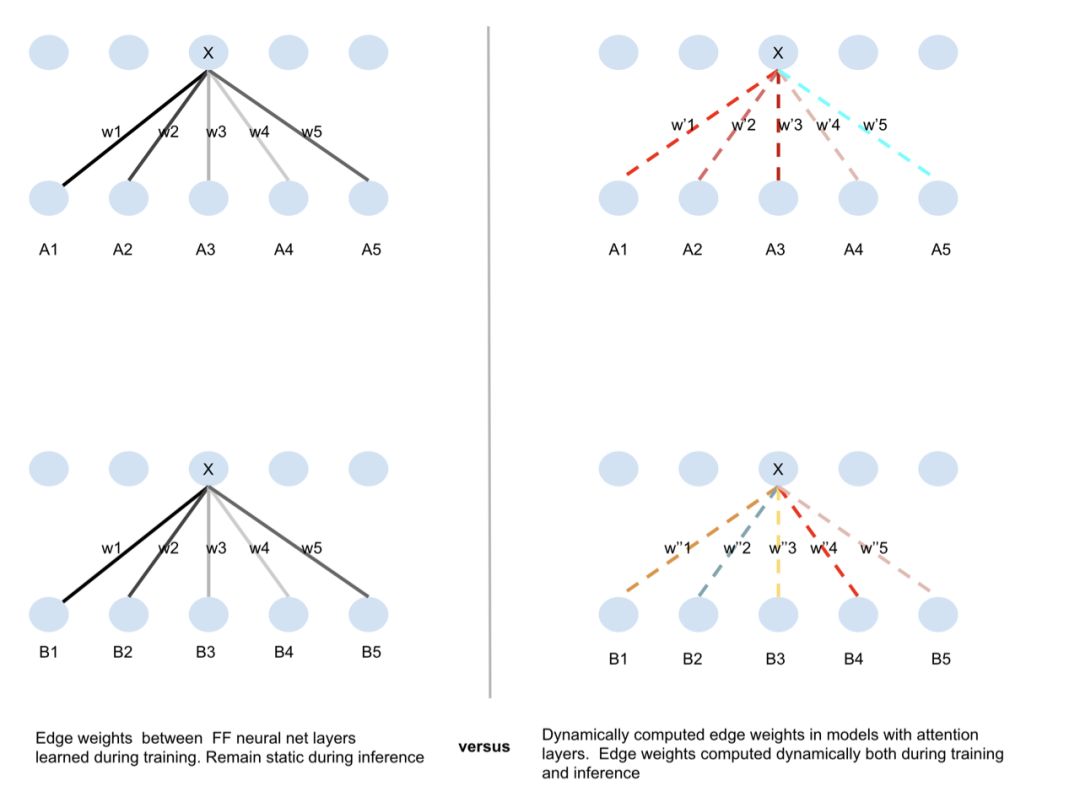
什么时候集中注意力?
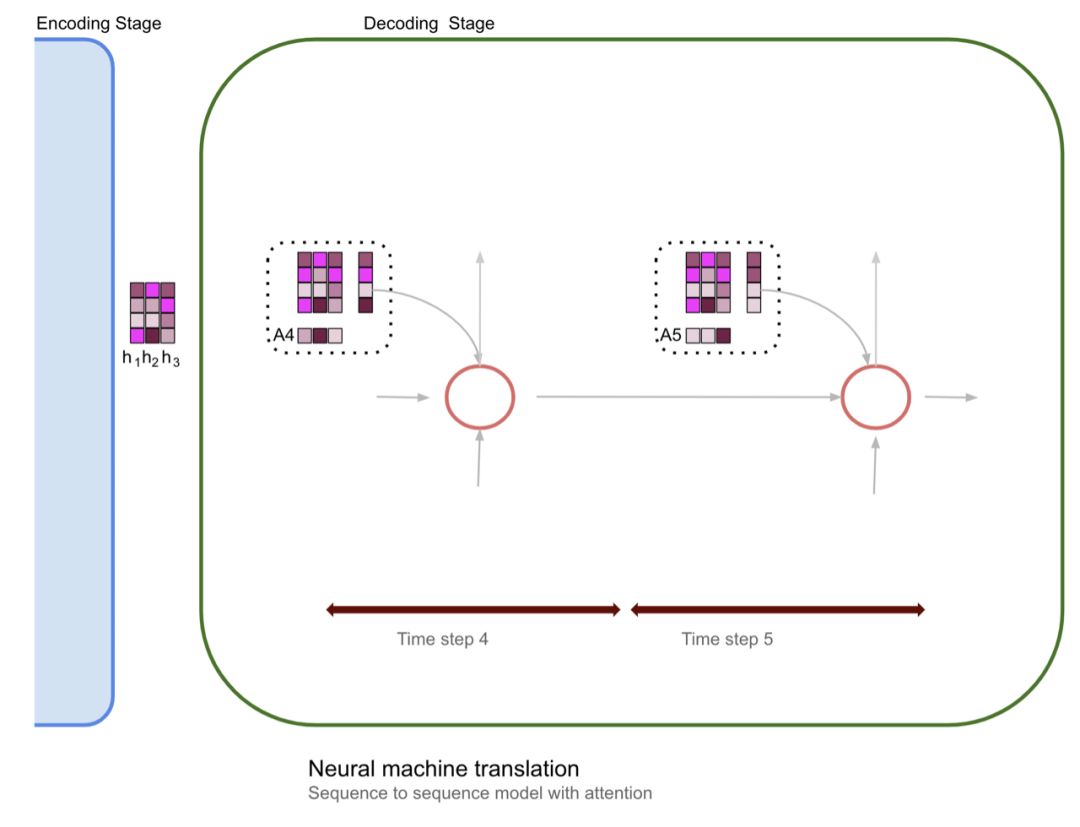
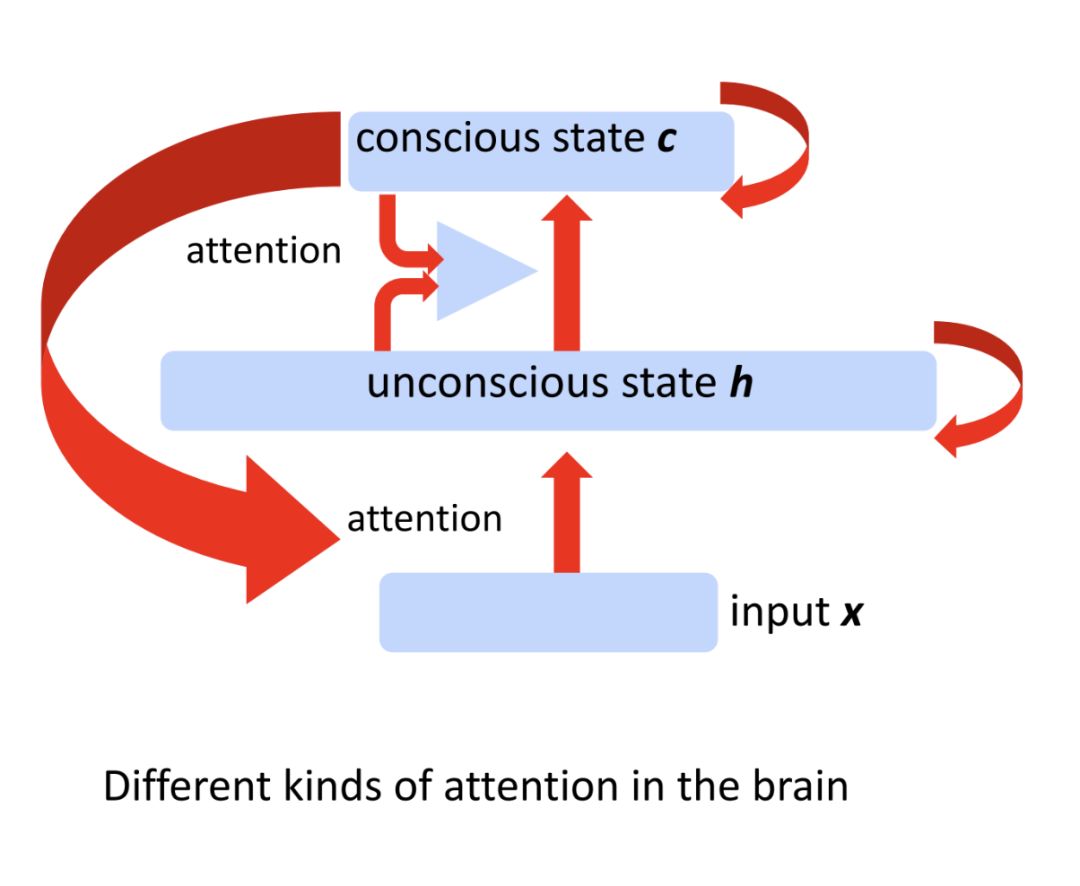
三、实现接近人类水平的 AI 的其他方法
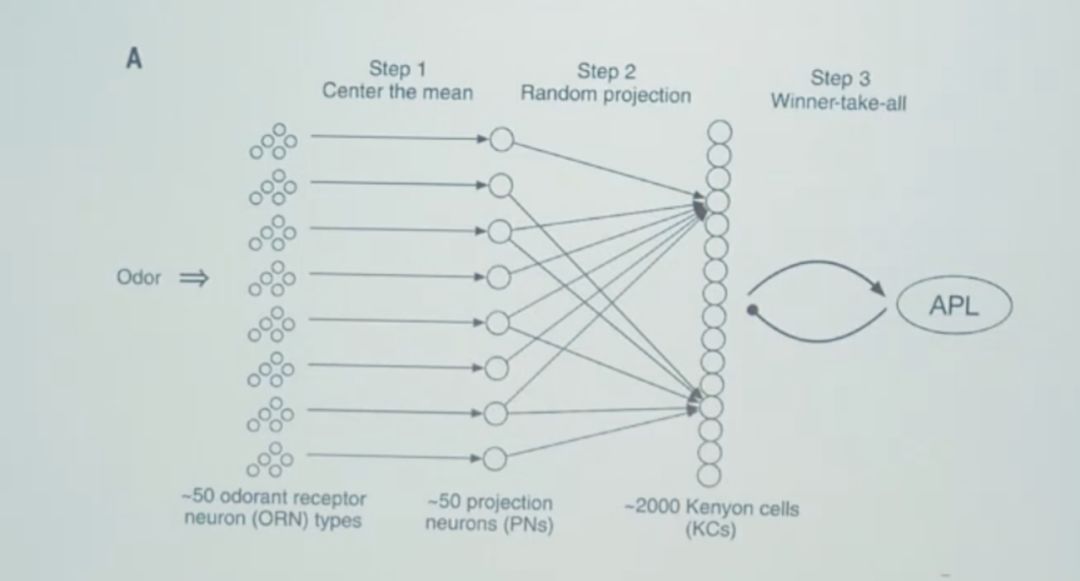

四、最后一点思考






