reddit网友吵爆!算力和数据真能解决一切?

新智元报道
【新智元导读】近日,一位reddit用户发起一个讨论帖:如果我们只有更多的数据和计算能力而停止理论工作的发展,今天的哪些问题可以解决?哪些问题绝对无法解决?这个帖子引发了网友热烈讨论。来新智元AI朋友圈 和AI大咖们一起讨论吧。
众所周知,算力和数据非常重要,但只有它们就够了吗?
近日,一位reddit用户发起一个讨论帖:如果我们只有更多的数据和计算能力而停止理论工作的发展,今天的哪些问题可以解决?哪些问题绝对无法解决?
这个问题引发了reddit网友的热烈讨论:

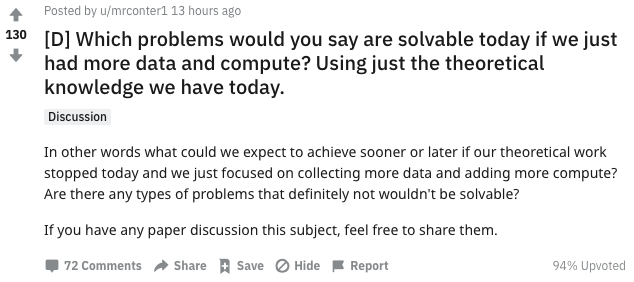
MrAcurite表示:我猜想任何涉及罕见疾病诊断的事情。我们没有更多数据,因为数据不存在。但这只是一个猜测,也许小样本学习还是可以解决这个问题的。

MichaelMMeskhi回复道:小样本学习并不解决任何问题。如果我们有数据,那么以往的的深度学习就可以了。但是从理论上讲,小样本学习可能能做到。

pm-me-your-covfefes表示:
我想说的是,有了足够的数据,我们可以找到大多数问题的解决方案,但这并不能使问题解决(或更容易解决)。
我是美国最大的医疗保健公司的高级数据科学总监。我们很庞大。我们基本上有你想知道的任何事情的数据。我怀疑除了中国的医疗体系之外,没有其他机构拥有比我们更多的医疗数据。
有了这些数据,我们就可以制作成千上万的生产模型,这些模型比我在公开场合甚至私下里看到的任何东西都让人印象深刻。这包括那些试图进入医疗行业的“性感”科技公司所做的一切。
但是,这些模型对改善医疗保健并不重要。我们有一些模型可以很容易地预测出每种疾病(甚至是最罕见的疾病)。疾病预测模型根本不是新颖的。也许10到15年前。这些模型对改善医疗保健甚至没有真正的帮助。
以糖尿病预测模型为例。我不需要一个花哨的模型来告诉我,这个350磅重、每天吃两个汉堡的不听话的病人,将会得2型糖尿病。但是,即使当他们被告知“嗨,你应该改变你的饮食和生活方式”,他们的病情随着时间的推移只会变得越来越严重和恶化(90%的概率)。这只会让他们的健康状况恶化,花更多的钱。
长话短说,至少在医疗保健领域,即使没有无限的数据,我们也可以创建我们想要的所有幻想模型,但这无助于解决问题,因为在大多数情况下,问题只是人(患者和providers)。我想对于其他依赖于人们做出他们可能不想做的改变的行业来说,情况也是一样的。

DoorsofPerceptron表示:“基本上,我认为可以使用无限标记的数据和近邻取样解决任何问题。如果你有足够的数据,那么你应该已经看过这一场景,你只需查找答案即可。
我们也可以大幅改进现有的深度学习方法,仅仅通过在问题上抛出足够的计算来找到最优的架构和在搜索空间上的brute forcing,而不是试图想出一些聪明的东西。(在某种程度上,行业已经做到了这一点,这就是为什么很多最好的架构都来自谷歌这样的地方)。
如果你不需要担心计算或数据,则可以通过关注探索/利用tradeoff的探索部分来最佳地进行强化学习。
因此,将需要更多地限制问题。对于无限的数据和无限的计算,我认为我们甚至不需要现代方法来解决所有问题。”

m--w认为:对于现代计算而言,大规模贝叶斯推理仍然过于昂贵。
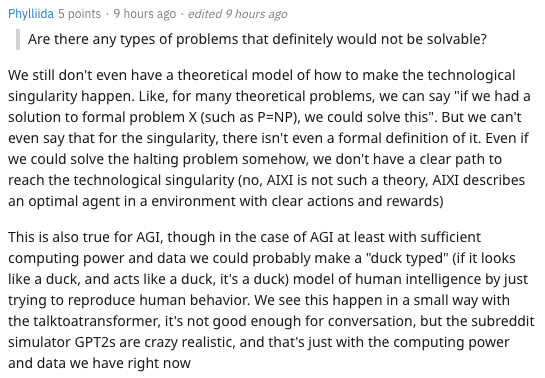
谈到哪些问题是绝对解决不了的,Phylliida表示:
我们甚至还没有一个理论模型来解释如何使技术奇点发生。例如,对于许多理论问题,我们可以说“如果我们有一个形式问题X(如P=NP)的解决方案,我们就可以解决这个问题”。对于奇点我们也不能说,因为它还没有一个正式的定义。即使我们能够以某种方式解决halting问题,我们也没有一条清晰的路径去达到技术奇点(不,AIXI不是这样的理论,AIXI描述了一个在一个有明确行动和回报的环境中的optimal agent)。
对于AGI来说也是如此,尽管在AGI的情况下,至少具有足够的计算能力和数据,我们可以通过试图复制人类行为来制作人类智能的“duck typed”(如果它看起来像鸭子,并且行为像鸭子,那就是鸭子)模型。我们认为这是使用talktoatransformer进行的小规模操作,尚不足以进行对话,但是subreddit模拟器GPT2非常逼真,而这正是我们目前拥有的计算能力和数据。

Turings_Ego则认为:我认为我们应该走另一条路。该领域在很大程度上受到数据集/基准测试的经验支持。如果我们真的想解决更复杂的问题,就需要做大量的工作来理解收敛性和什么不是收敛性。我预感到拓扑数据分析将提供这些证明的一些关键方面。
人工智能进步来自计算力?周志华:绝对错误!
再来看看国内的AI大佬们是如何看待算力和数据的。
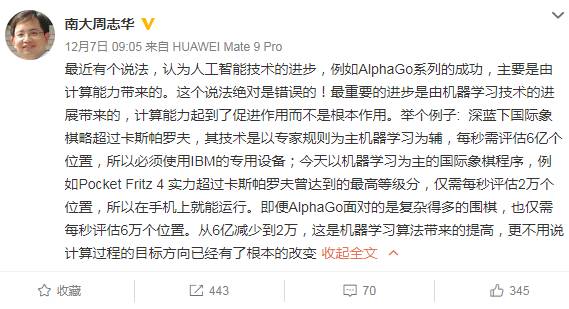
对于“人工智能进步是计算能力带来的”这种观点,南大周志华教授曾表示:这个说法绝对错误的!周老师将IBM深蓝和AlphaGo做对比,深蓝下国际象棋每秒需要评估6亿个位置,而AlphaGo面对更加复杂的围棋,每秒也仅需评估2万个位置,“从6亿到2万,这是机器学习算法带来的提高,更不用说是计算过程的目标方向已经有了根本的改变”。
对此,中科院计算所先进计算机系统研究中心主任包云岗回应,算法起到了至关重要的作用,而计算力的进步也不可或缺。包云岗用“登月”来类比两者相辅相成的关系。“AI进步中算法的作用是导航+一级火箭,计算能力的作用相当于二级+三级火箭”,对于登月缺一不可。包云岗还表示,周老师提供的数据,从IBM评估6亿个位置到AlphaGo评估2万个,“20年算法效率提高了3万倍”,客观展示了算法的进步。

对此,周志华教授表示,不是说计算能力的提升不重要,而是说人工智能技术取得的进展,绝对不是单纯由于“计算能力的提升造成的”。周老师做了进一步阐释:方向性的转变,不是能靠计算能力的提升实现的。如果算法没有取得突破,仍然依靠专家规则,哪怕是研发出量子计算机来加速也没有用。
此外,关于6亿和2万的位置评估,两者取得的结果并不一致。因此,不能简单地拿6亿除以2万来计算加速比。周志华教授说,算法的改变可能改变求解过程的性质,今天人工智能取得的进步恰恰是通过这一点,而且这是仅通过计算能力的提升无法实现的。

Hinton 认为未来的 AI 系统将主要是无监督的。无监督学习是机器学习的一个分支,可以从未标记、未分类的测试数据中提取知识 —— 在学习共性和对共性是否存在做出反应的能力方面,无监督学习的能力几乎达到人类水平。
Hinton 说:“如果你采用一个拥有数十亿参数的系统,对某个目标函数执行随机梯度下降,它的效果会比你想象的好得多…… 规模越大,效果越好。”
神经网络和深度学习在几十年前失败,但是现在却成功了,原因是什么?而它的局限又在什么地方?贾扬清曾谈到:
-
成功的原因,一点是大数据,一点是高性能计算。 -
局限的原因,一点是结构化的理解,一点是小数据上的有效学习算法。
阿里巴巴副总裁贾扬清认为:“大量的数据,比如说移动互联网的兴起,以及 AWS 这样低成本获得标注数据的平台,使机器学习算法得以打破数据的限制;由于 GPGPU 等高性能运算的兴起,又使得我们可以在可以控制的时间内(以天为单位甚至更短)进行 exaflop 级别的计算,从而使得训练复杂网络变得可能。要注意的是,高性能计算并不仅限于 GPU ,在 CPU 上的大量向量化计算,分布式计算中的 MPI 抽象,这些都和 60 年代就开始兴起的 HPC 领域的研究成果密不可分。
但是,我们也要看到深度学习的局限性。今天,很多深度学习的算法还是在感知这个层面上形成了突破,可以从语音、图像,这些非结构化的数据中进行识别的工作。在面对更加结构化的问题的时候,简单地套用深度学习算法可能并不能达到很好的效果。有的同学可能会问为什么 AlphaGo 和 Starcraft 这样的算法可以成功, 一方面,深度学习解决了感知的问题,另一方面,我们也要看到还有很多传统的非深度学习算法,比如说 Q-learning 和其他增强学习的算法,一起支撑起了整个系统。而且,在数据量非常小的时候,深度学习的复杂网络往往无法取得很好的效果,但是很多领域,特别是类似医疗这样的领域,数据是非常难获得的,这可能是接下去的一个很有意义的科研方向。
接下去,深度学习或者更广泛地说,AI 这个方向会怎么走?我个人的感觉,虽然大家前几年一直关注 AI 框架,但是近年来框架的同质化说明了它不再是一个需要花大精力解决的问题,TensorFlow 这样的框架在工业界的广泛应用,以及各种框架利用 Python 在建模领域的优秀表现,已经可以帮助我们解决很多以前需要自己编程实现的问题,因此,作为 AI 工程师,我们应该跳出框架的桎梏,往更广泛的领域寻找价值。”
-
与国内外一线大咖、行业翘楚面对面交流的机会 -
掌握深耕人工智能领域,成为行业专家 -
远高于同行业的底薪 -
五险一金+月度奖金+项目奖励+年底双薪 -
舒适的办公环境(北京融科资讯中心B座) -
一日三餐、水果零食
新智元邀你2020勇闯AI之巅,岗位信息详见海报:




