批量生产数学猜想,这样的自动算法学会了探索基本常数
机器之心报道
参与:思源、张倩、一鸣
印度历史上有一位著名的天才数学家拉姆努金,他留下了很多伟大的公式。虽然有些没有证明,只能称之为猜想,但后来还是被应用到了很多意想不到的领域。他思维跳脱、运算能力极强,常常得出自己也证明不了的公式,哈达将其与欧拉和雅克比相比。然而,这种天才数学家百年难遇,那么,在我们这个时代,由谁去提出这些猜想呢?近日,以色列理工学院和谷歌的研究者公布了自己的一项工作,并将其称之为「拉姆努金机器」,表示他们可以用算法批量生产数学猜想……
e、π等基本常数普遍存在于物理、生物、化学、几何学、抽象数学等各个学科,在这些学科中发挥辅助性作用。然而,几个世纪以来,有关基本常数的新数学公式很少,通常是通过数学直觉或独创性偶然发现的。
但最近,来自以色列理工学院和谷歌的研究者发现了一种利用算法生成基本常数猜想的新方法,并将其命名为「拉姆努金机器」(Ramanujan Machine)。Ramanujan Machine 利用计算机的算力进行数学计算,目前已经发现了几十个新的猜想。

研究者表示,他们利用算法搜寻新的数学猜想公式。社区可以为这些猜想提供证明,还可以提出或开发新的算法。任何新的猜想、证明或算法都将以提出者的名字命名。
也许我们高中或大学偶尔发现过什么,例如 liqui_date_me 在 Reddit 上表明,他在刚学习无穷级数的时候,就发现 ∑n!/n^n 会收敛到约为 1.8 的随机数,新研究也许会告诉我们这些值都有什么意义。Ramanujan Machine 就是将这些「发现」总结起来,形成合理的猜想。
Slash Sero 在 Reddit 上也评论说:「这些发现的猜想都是已知等式的变体,它们在技术上是新的,但是在语义上并不是新的,我们可以通过分数的重新分布定义任何数学常数。不过这种算法非常有意思,它能自动化搜索和测试新表达式,这原本都是需要人力完成的。」
不管怎么说,这项研究都旨在激励大家进行数学和人工智能驱动的科学研究。
论文链接:https://arxiv.org/pdf/1907.00205.pdf
什么是基本常数猜想
基本常数的简单公式通常散发着简洁的数学之美。比较有名的基本常数包括欧拉恒等式(Euler's identity)——e^iπ + 1 = 0,还有黄金比例的连续分数表示:
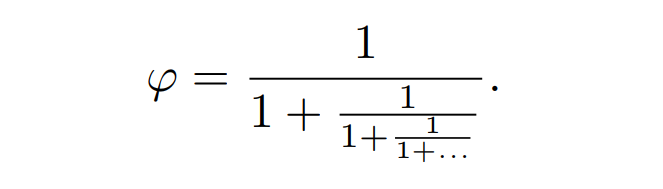
这些规律公式(Regular Formula,RF)的发现通常是零星的,常被归功于数学独创性或深刻的直觉。一个比较著名的例子是高斯发现数列规律的能力,他发现的规律带来了新的分析领域(如椭圆函数和模函数)和关于质数定理的假设。他甚至说过一句名言「我得到了结果,但我现在还不知道是怎么得出来的」(I have the result, but I do not yet know how to get it),从中可以看出发现数据规律和 RF 的重要性,它使数学发现成为可能。
为什么能自动搜索基本常数猜想
和物理学或其他学科的评价不同,数学常数可以用恰当的公式计算到特定的精确度(以位数为计),因此可以证明一个绝对的正确结果。在这种情况下,数学常数包括无限的数据(例如无理数的无限长度)。研究人员使用这个方式寻找新的规律公式,并将已有的精确表示作为标注真值。
由于基本常数的应用无所不在,寻找这种规律可以揭示很多可能的新数学结构,如 Rogers-Ramanujan 连分数(以模块化的形式)和 Dedekind η 和 j 函数。既然我们有了数据及结构,那么岂不是能通过梯度下降搜索到新数学猜想?
用机器学习自动学习新猜想?
Ramanujan Machine 到底是不是用机器学习搜索新的猜想,这就要看我们对机器学习的定义了。它同样采用梯度下降「学习」更合理的猜想,只不过是在一种独特的潜在空间中学习。论文作者表示,过一段时间他们将使用更直接的机器学习方法,并展示更多的可能性。
在 Ramanujan Machine 这项研究中,研究人员建立了一种新的机制,用于学习常数和一系列新猜想之间的关系。由于机制可以以许多种规律公式表示,研究人员提出了一种潜在的等式——广义连续分数:
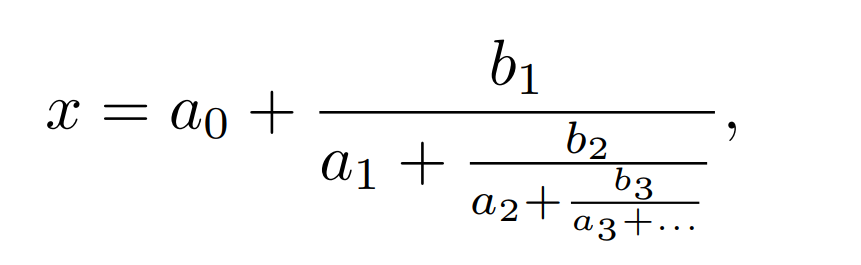
如图,b_n ∈ Z,n = 1, 2, . . .,分别是部分分子和分母。广义连续分数中的这种分子和分母的多项式表达方式是数学界几个世纪以来一直研究的问题。
研究人员提出,他们的思路是找到广义连续分数和基本常数之间的函数关系。简单来说,列举和表达具有美感,因此研究人员将实数多项式加在等式两边。他们总共提出了两种搜索算法。
第一种方法是中间逼近(Meet-In-The-Middle,MITM)算法,从而以相对小的精度降低搜索空间、减少错配。这种算法提升了很大一部分广义连续分数在剩余次数中的迭代,用于检验它们是否成为新的猜想中的规律公式。因此,这种算法称为 MITM-RF。第二种算法使用基于优化的策略,研究人员称之为 Descent&Repel,通过转换为实数网格点来定义猜想中的正则公式。
MITM-RF 算法提出了一些新的猜想,如图:
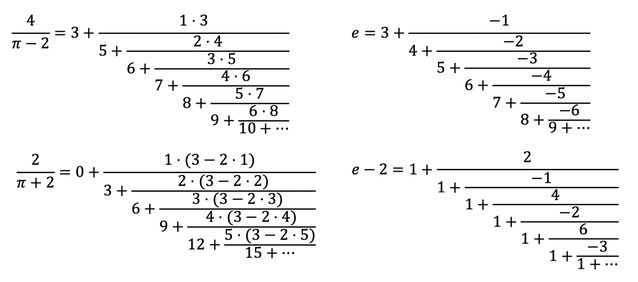
猜想 1-4:自动生成的数学公式猜想,它们都是应用 MITM-RF 算法,并通过该论文提出的 Ramanujan Machine 生成的。
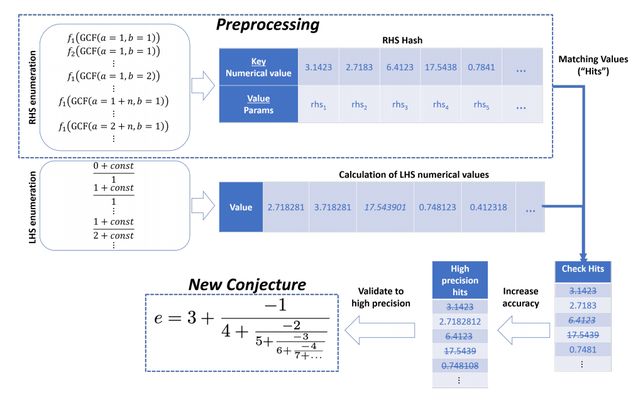
如上图所示为 MITM-RF 方法。研究者首先会低精度地枚举等式右边的表达式 RHS(Right-Hand-Side),值会储存在哈希表中。然后研究者会枚举等式左边的表达式 LHS,并搜索与 RHS 相匹配的项。随后模型会重新计算匹配,并获得更高精度的结果。这个重计算的过程会一直进行下去,直到达到了某种精度,我们就能将其作为新提出的猜想。
学习的新猜想只是巧合?
我们可能会疑惑,模型找出来的猜想是数学上的恒等关系,还是说只是数值上的巧合?如果是数值上的巧合,那岂不是说前面很多步都是准确的,但随着数值计算越来越多,它总会出错而崩溃。然而,这项工作中提出的方法使得猜想非常鲁棒:对于 10^9 大小的枚举空间,以及小数点后 50 位的数值精度,随机找到能匹配的猜想概率要小于 10 的负 40 次方。
这个极小的概率可以让我们相信,新的猜想也许是等待严格数学证明的「真理」。在过去一段时间中,这种猜想的证明会带来很多新发现,例如费马大定理(Fermat's Last Theorem)被证明后,得出来的新数学架构。研究者相信这些批量生成的新猜想也有相同的地位,它们的证明会带来全新的技术进步。
学习的参数猜想有什么用
与本文提出的方法相比,很多已知的基本常数的 RF 都是通过传统的数学证明(即从这些常数的已知特性中推导出的序列逻辑步骤)发现的。在本文中,研究者旨在反转这一过程,在没有关于基本常数数学结构先验知识的条件下,仅用它们的数值数据为其找到新的 RF。每个 RF 都可能使产生该 RF 的数学结构的逆向工程成为可能,并为该领域提供新的见解。本文中的方法在经验常数中尤其有效,如混沌理论中的费根鲍姆常数(Feigenbaum constant)(见表 2),该常数是从模拟中通过数值推导出来的,没有解析表示。
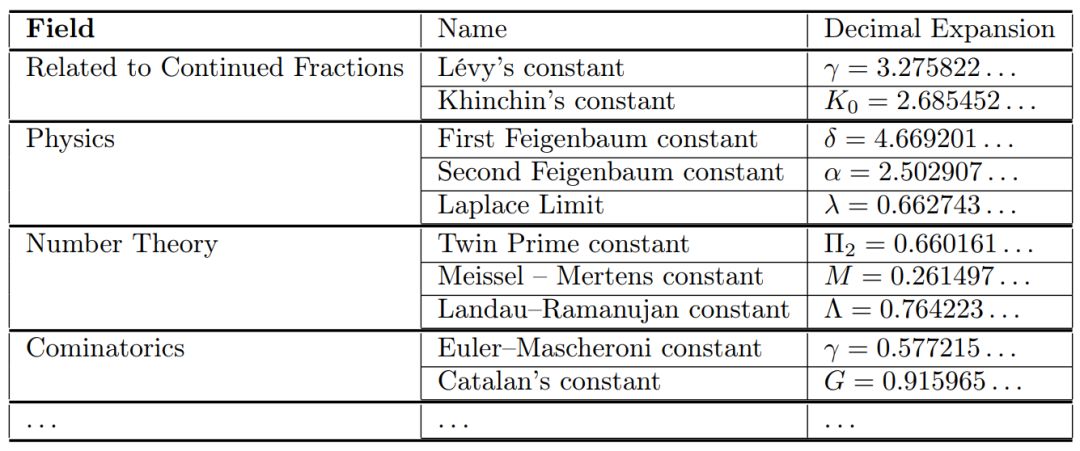
表 2:来自不同领域的基本常数示例,这些都是本文方法的相关目标。
新的 RF 猜想可能会有有趣的应用,快速收敛的 GCF 和其他恒等式用于高效计算不同的常数。例如,计算π最高效的方法之一就是基于 Ramanujan 提供的一个公式。更广泛地来说,新的 RF 可以帮助我们更快地计算其他常数,如上面展示的 e 的超指数收敛。新 RF 的另一个潜在应用是证明基本常数的内在特性。
深度Pro
理论详解 | 工程实践 | 产业分析 | 行研报告
机器之心最新上线深度内容栏目,汇总AI深度好文,详解理论、工程、产业与应用。这里的每一篇文章,都需要深度阅读15分钟。
今日深度推荐

点击图片,进入小程序深度Pro栏目
PC点击阅读原文,访问官网
更适合深度阅读
www.jiqizhixin.com/insight
每日重要论文、教程、资讯、报告也不想错过?




