30系列显卡抢不到,为了训练大型CNN,我该不该入手2080 Ti?

作者 | 青暮
1
参数
所有测试均采用了自动混合精度训练,也称为FP16训练。如今,按照测试数据来看,至少在Volta系列显卡上训练已经没有比较意义。
显卡
TensorFlow Docker容器
批量大小
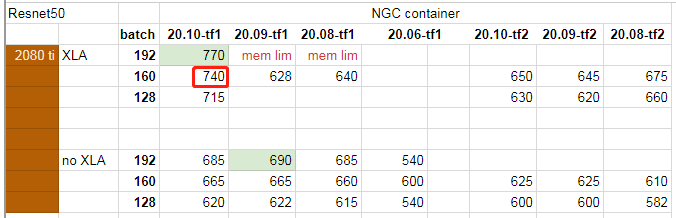
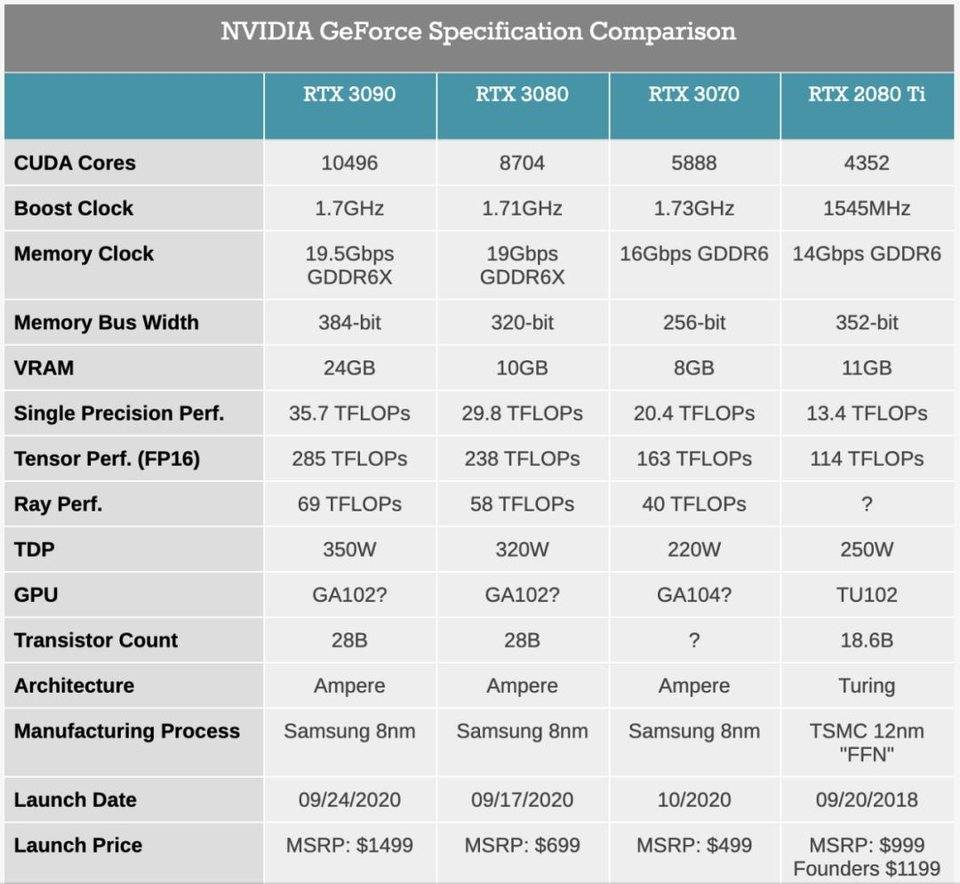 30系列显卡和2080 Ti的参数表
30系列显卡和2080 Ti的参数表
XLA优化
A100/V100
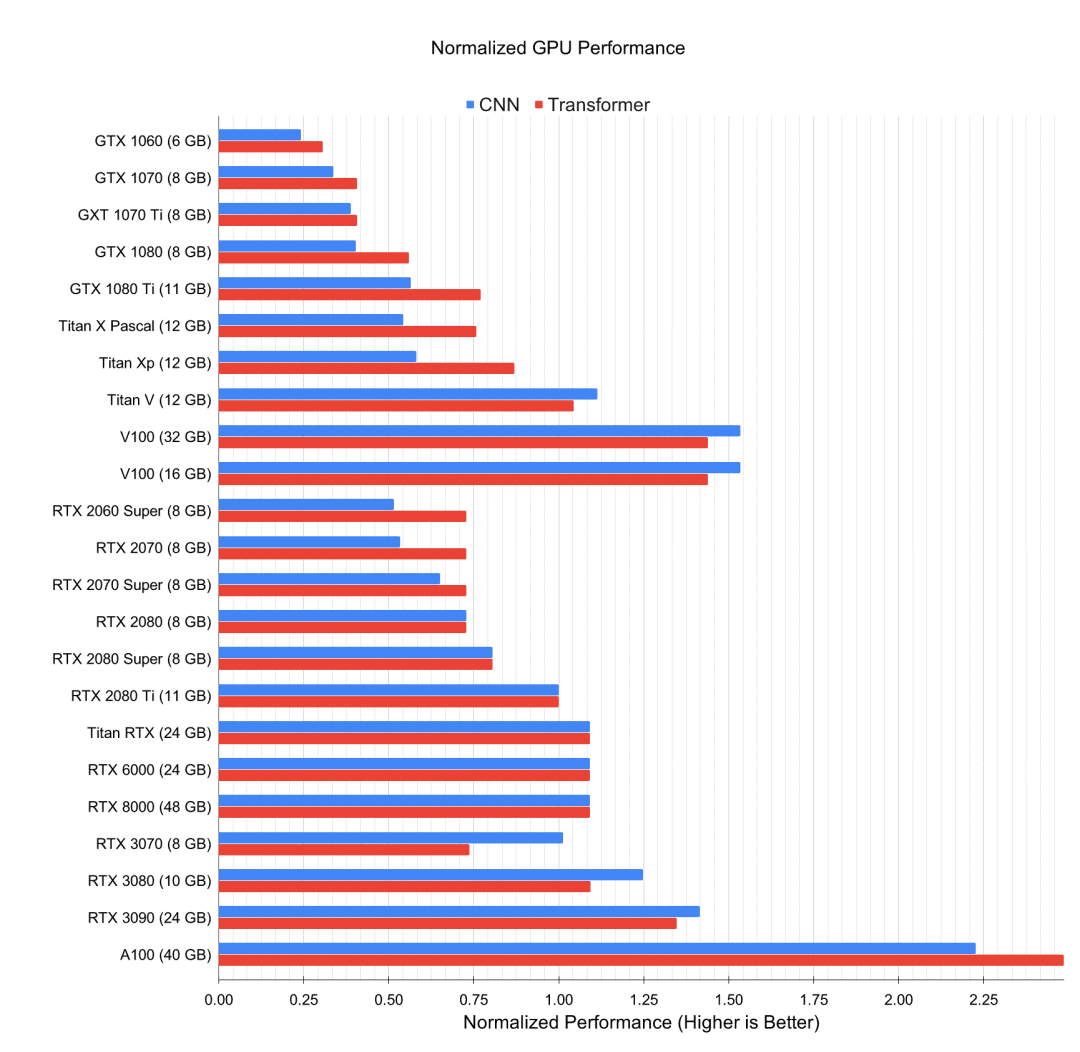 相对于RTX 2080 Ti的归一化GPU深度学习性能。
相对于RTX 2080 Ti的归一化GPU深度学习性能。
2
结论
3
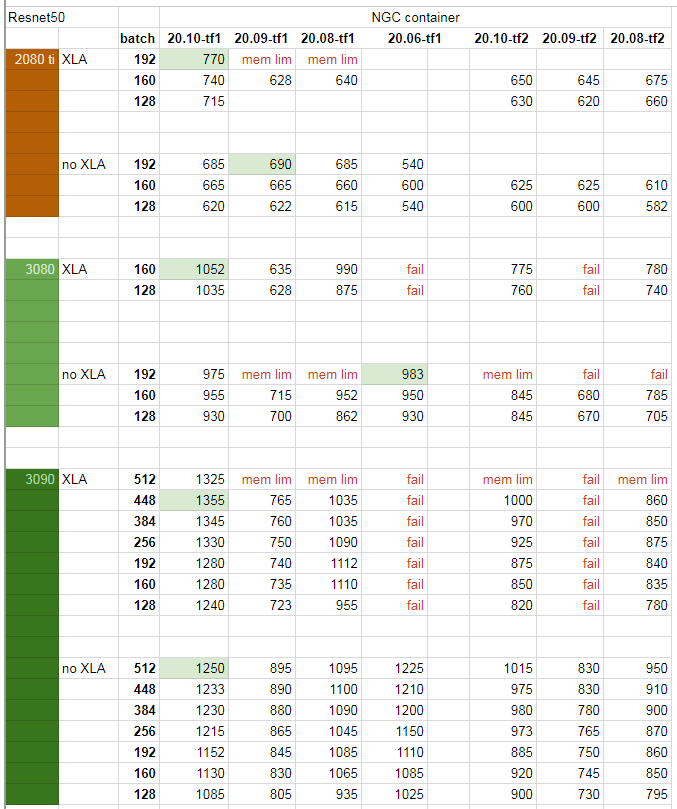
完整测试数据

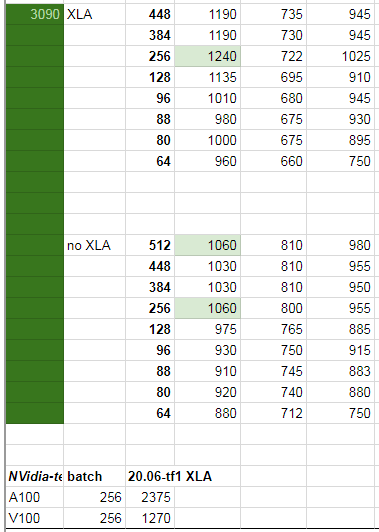
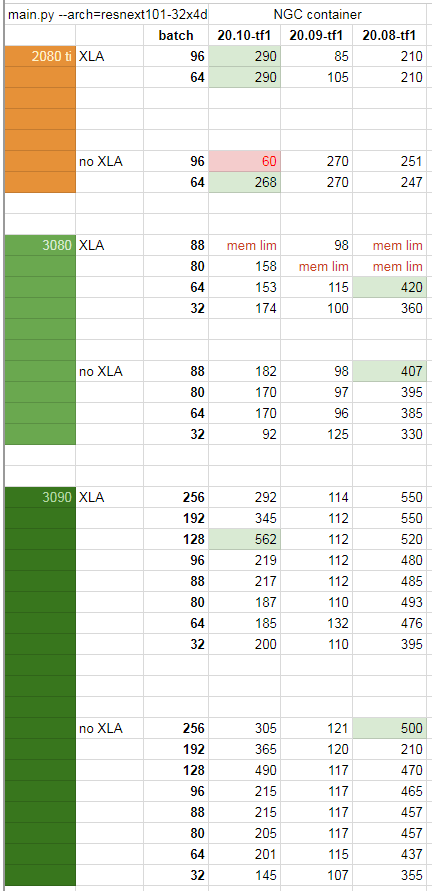

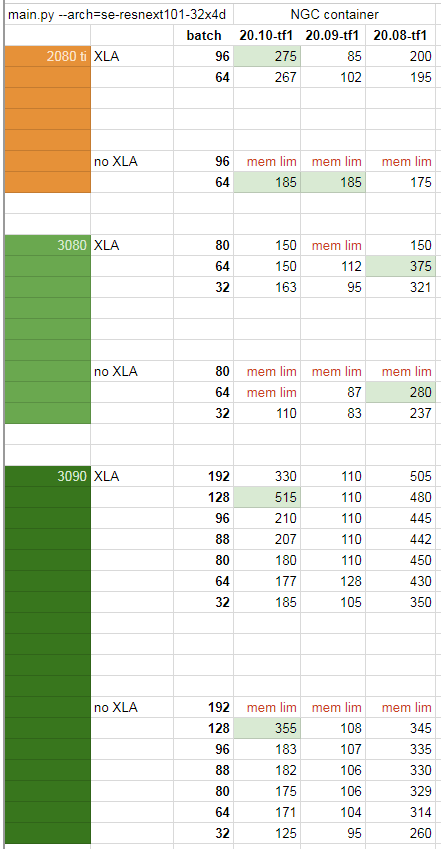

https://www.reddit.com/r/MachineLearning/comments/jrj6ry/r_extensive_rtx_3080_and_3090_benchmarks_on/
https://fsymbols.com/3080-3090-benchmarks/
https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/#How_do_I_cool_4x_RTX_3090_or_4x_RTX_3080


点击阅读原文,直达ICLR小组~
登录查看更多
相关内容
专知会员服务
54+阅读 · 2020年2月4日




相关VIP内容
专知会员服务
54+阅读 · 2020年2月4日
相关资讯
相关论文