【GNN】GN:更通用的 GNN 架构

今天学习的是 DeepMind 2018 年的工作《Relational inductive biases, deep learning, and graph network》,目前超 500 次引用。这篇论文是 DeepMind 联合谷歌大脑、MIT、爱丁堡大学等 27 名同学发表的重磅论文,同时提出了“图网络”的框架,将端到端学习与归纳推理相结合,并有望解决深度学习无法进行关系推理的问题。
这篇论文一部分是对过去的工作进行回顾,另一部分是过去的工作进行总结与统一。作者指出组合泛化能力(combinatorial generalization)是人工智能实现类人能力的首要任务,而结构化表示和计算是实现这一目标的关键。
至于组合泛化能力,就像生物学是利用先天和后天两者的协同作用。人类智慧的一个关键特征是“无限利用有限手段”的能力,其中一小部分元素(单词)可以用无限的方式有效地组合起来(组成句子等),这便是组合泛化的能力。放到计算机技术中,便应该综合“手工特征工程”和“端到端学习”两种方式进行优势互补,而不是一味的强调端到端学习。
在这篇论文中,作者提出了一种具有强相关性归纳偏置的 AI 框架——图网络(Graph Network),并讨论了图网络如何支持关系推理和组合泛化,从而为更复杂、可解释和灵活的推理模式奠定了基础。
1.Introduction
我们知道,人类的组合泛化能力很大程度上取决于表征关系结构和关系推理的认知机制。在学习时,我们要么将新知识放入现有的结构化知识体系中,要么调整结构本身来更好的适应新知识和旧知识。
那么,如何建立一个系统来表达这种组合泛化能力呢?这个问题从起源开始就一直是 AI 的核心问题,也是许多结构化方法的核心,早期的方法有语法、图模型、贝叶斯等,近期流行的方法有关系强化学习、统计关系学习等。
结构化对于早期的机器学习方法而言非常重要,其关键原因在于当时的数据和计算资源昂贵,而结构化方法的强归纳偏置所带来的样本和复杂度的改进是非常有价值的。
而现代以深度学习为代表的方法通常遵循这一种“端到端”的设计哲学,这种哲学强调最小的先验表征和计算假设,并试图避免显示结构和“手工特征工程”。这种极简主义与当前廉价的数据和计算资源非常吻合,并在诸多领域取得了显著的成绩。
然而,尽管深度学习取得了不错的成绩,但是其在一些复杂的语言和场景理解、结构化数据推理、少样本学习等方面仍然面临着非常大的挑战。而这些挑战更需要组合泛化能力。
近年来,深度学习和结构化方法的交叉领域出现了一类模型,他们关注于对显示的结构化数据进行推理的方法。这些方法的共同之处在于能够在离散的实体和他们之间的关系上进行计算,它们与经典方法的不同之处在于如何学习实体和关系的表示和结构以及相应的计算。值得注意的是,这些方法都带有强烈的关系归纳偏置,以特定的架构假设的形式来引导这些方法去学习实体和关系,这被认为是类人智能的一个重要组成部分。
接下来,本文将从关系归纳偏置视角来看待深度学习方法,并表明现有方法所带有的关系假设并不是总是明确的,随后,作者提出了一个基于实体和关系推理的通用框架——图网络(Graph Network),用于统一和扩展现有的操作图的方法,并描述了使用图网络作为 block 来构建强大架构的关键设计原则。
2.Relational Inductive Biases
这一节主要介绍关系归纳偏置(Relational inductive biases),以及其在深度学习中的推广。
2.1 Relational inductive biases
首先,我们来看下什么是关系归纳偏置。
在介绍这个概念之前,我们先来看下什么是关系推理(relational reasoning)和归纳偏置(inductive biases)。
2.1.1 Relational reasoning
我们将结构(structure)定义为组成一组已知构件的产物。“结构化表示”可以捕捉这个组成的元素分布,而“结构化计算”作为一个整体对元素及其组成进行操作。关系推理涉及操纵实体和关系的结构化表示,并使用其构成规则。我们可以使用这些术语来捕捉认知科学,理论计算机科学和人工智能的概念,如下所示:
-
「实体(entitiy)」:具有属性的元素,比如具有大小和质量的物体; -
「关系(relation)」:实体之间的属性。两个物体之间的关系,比如具有相同的尺寸,A比B更重等。这里我们关注实体之间的配对关系; -
「规则(rule)」:将实体和关系映射到新的实体和关系的函数。
比较经典的例子是图模型,可以通过随机变量明确随机条件独立性来表示复杂的联合分布,如隐马尔可夫模型等;或者明确表示变量之间的稀疏依赖关系,从而提供各种有效的推理和推理算法,如消息传递等。
2.1.2 Inductive biases
我们把实体之间关系和相互作用施加的约束称为归纳偏置。
我们知道,学习是通过观察和与世界互动来获取有用知识的过程,它包括搜索一个解决方案的空间,以期望提供更好的数据解释或获得更高的回报。但在许多情况下,会同时存在多个解决方案。归纳偏置的作用加入先验知识,使其具有优先顺序,而不会仅依赖于观察到的数据。
比如说,在贝叶斯模型中,归纳偏置通常通过先验分布的选择和参数化来表达;而在其他模型中,可能是为了避免过度拟合而添加的正则化项;也可能是编码在算法本身的体系结构中。
归纳偏置通过会以灵活性来换取样本复杂度来提高性能,可以用偏置-方差权衡(bias-variance tradeoff)来理解。归纳偏置既能在不显著降低性能的情况下改进对解决方案的搜索,也能帮助找到一个理想方式泛化的解决方案。然而,不合适的归纳偏置也可能会因为引入太强的约束而获得次优解。
归纳偏置可以表示关于数据生成过程或解决方案的假设空间。比如说,我们用一维函数对数据进行拟合时,线性最小二乘法遵循逼近函数为线性模型的约束,并且在平方损失的惩罚下使得逼近误差最小。这表示数据生成过程中可以简单地解释为加上了一个线性的高斯噪声。同样的,L2 正则化则优先考虑参数值较小的解,并能诱导出唯一解和全局结构来解决其泛化能力。
归纳偏置可以解释为一个关于学习过程的假设:当解决方案之间的模糊性减少时,就能更容易寻找好的解决方案。值得注意的是,这些假设并不需要很明确——它们折射的是模型与世界进行交互的方式。
此外也含有很多非关系归纳偏置,如:activation non-linearities、weight decay、Dropout、Normalization、data augmentation等。
所以,关系归纳偏置是应用关系推理的归纳偏置,是具有生成能力的。
2.2 Deep learning building blocks
接下来,我们探索下深度学习方法中表达的关系归纳偏置。在此,我们需要确定一些关键概念,比如说深度学习中什么是实体、什么是关系等,具体表现如下表所示:

我们可以看到,在不同的架构下,深度学习的实习、关系、规则等的表现形式是不同的。为了理解架构之间的差异,我们可以通过探究这些框架支持关系推理的方式来得到解答。
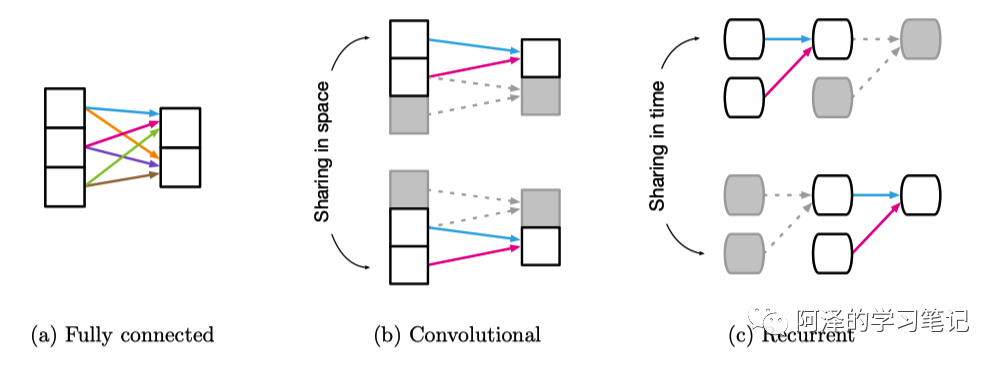
2.2.1 Fully connected layers
首先是全连接层,实体是神经元,关系是 all-to-all(全连接),规则由权重和偏置指定,其参数是完整的输入信号,没有重用也没有信息隔离。因此全连接层的隐式关系归纳偏置非常弱,所有输入单元都可以相互作用,从而确定输出单元的值。
2.2.2 Convolutional layers
然后是卷积层,其实体依然是神经元,不过神经元之间的关系比较稀疏,其和全连接层之间最大的区别在于「神经元」和「平移不变性」,局部性反映了关系规则的参数是那些在输入信号的坐标空间中彼此接近的实体,与远端实体隔离。平移不变性反映了同一规则在输入的不同位置之间的重用。这样的关系归纳偏置对于处理自然图像数据是非常有效的,因为图像在局部邻域内协方差很高,而协方差随着距离的增加而减小。
2.2.3 Recurrent layers
然后,我们再来看递归层,它是通过一系列的 step 实现的,所以我们把输入和隐藏状态视为实体,将当前隐藏状态和前一个时间步的隐藏状态之间马尔可夫依赖关系视为关系。其规则是复用每个时间步,反映了时间不变性的关系归纳偏置。
2.3 Computations over sets and graphs
我们知道集合中的元素是没有顺序的,但是集合中元素的一些特征可以用来指定顺序,比如说质量体积等。因此用来处理集合的深度学习模型应该是在不同的排序方式下都能有同样的结果,也就是对排序不变性(invariance to ordering)。
此外,处理集合的模型,其关系归纳偏置并不是因为有什么关系的存在,而恰恰是由于缺乏顺序,比如说,一个太阳系的中心位置,就是把各个行星的位置进行求平均,每个行星都是对称的。如果使用 MLP 来处理这个问题,那么可能需要大量的训练集才能训练出一个求平均的函数(因为 MLP 对每个输入都是按照单独的方式进行 处理,而不是一视同仁)。
但有的时候又不能仅仅考虑这种排序不变性,因为行星之间也可能会存在影响,而现实生活中也是的,任何两个事物之间可能是存在存在联系的,也可能是不存在联系的,这其实就是 Graph 模型,每个物体只与一部分其它物体进行相互作用。
通常来说,图是一种支持任意关系结构的表示形式,对图的计算提供了强大的关系归纳偏置,超出了卷积层和递归层所能提供的偏置。
3.Graph Networks
图网络模型遍布监督学习,半监督学习,无监督学习,强化学习等领域。并能在视觉理解、小样本学习、动态物理结构、多代理系统、知识图谱推理、预测化学分子和图像分割等领域具有诸多应用。
近年来比较经典的研究图神经网络的主体包括:
-
2009年,Scarselli 等人提供了早期 GNN 方法的权威概述; -
2017 年,Bronstein 等人提供了关于非欧空间中深度学习的调研,并探索了 GNN、GCN 和相关的谱方法; -
2017 年,Gilmer 等人引入了消息传递神经网络(MPNN),统一了各种 GNN 和 GCN 方法; -
2018 年,Wang 等人引入了非局部神经网络(NLNN),统一了各种“Self-attention”风格的方法。
3.1 GN
接下来作者将定义一个更加通用的图网络(GN)框架,用于图结构表示的关系推理。GN 框架可以概括和扩展各种 GNN、MPNN 和 NLNN 方法,并支持用简单的组建(building blocks)来构建复杂的网络结构(architectures)。
值得注意的是,GN 并没有提出 Neural 这个术语,也就是说 GN 不仅仅可以在神经网络中使用,也可以用于其他模型。
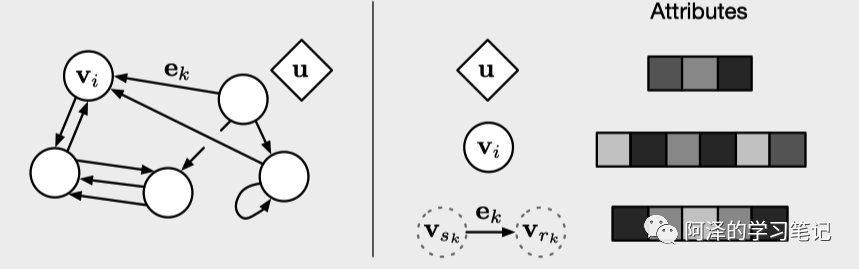
GN 框架的主要计算单元是 GN block,这是一个 Graph2Graph 的模块,以图形为输入,在其结构上进行计算,并返回图形作为输出。下图为图的简单结构,节点和边都是包括图本身都是分布表示:
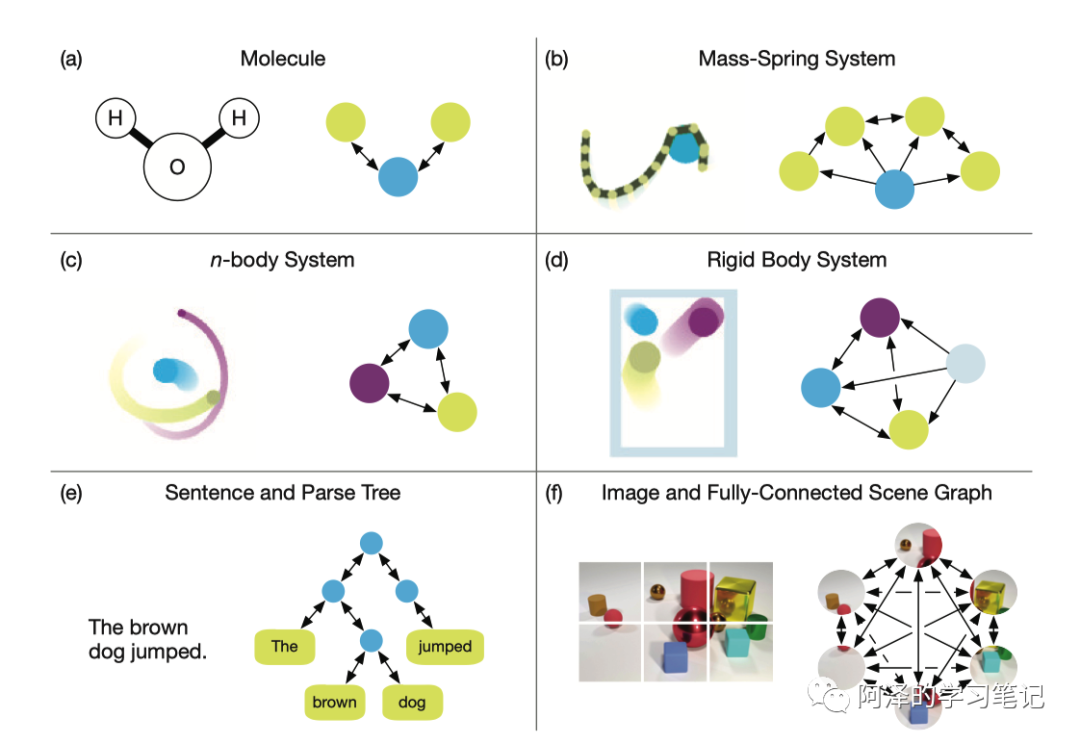
下图为自然场景下的各种不同的图结构:
GN 架构的 block 模块强调可定制性,并支持定制的关系归纳偏差。其关键的设计原则有三点,包括灵活的表现形式、可配置的 block 结构,以及可组合的 multi-block 结构。这三个设计原则,我们将在第 4 节进行介绍。
GN 模块包括三个更新函数 和三个聚合函数 :
其中, 为节点 i 的向量, 为连接 k 的向量, 为全局向量,
下图为 GN 模块的计算步骤,旁边有说明就不进行介绍了:
下图为 GN 模块的计算步骤,旁边有说明就不进行介绍了:

下图为 GN 更新的示意图:
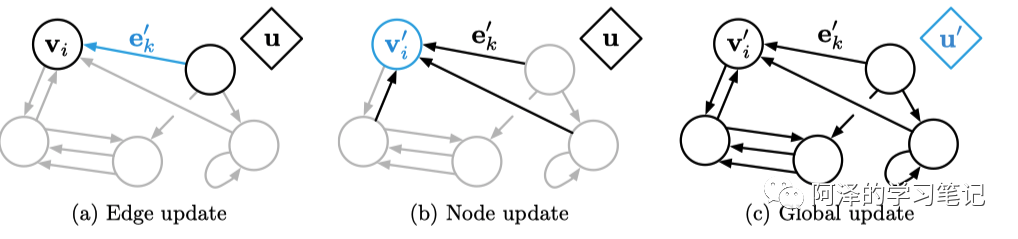
需要注意的是,这种更新顺序也是可以改变的。
3.2 Relational inductive biases in GN
我们再来分析下 GN 中的关系归纳偏置。
首先,图网络可以表示实体之间的任意关系,这意味着 GN 的输入决定了节点表示的交互于隔离,而不是由固定的体系结构决定的;
其次,图将实体及其关系表示为集合,集合对排列是不变的。这意味着 GN 不受这些元素的顺序的影响(场景中的对象没有自然顺序);
最后,GN 的每边函数和每节点函数分别跨所有边和节点重用。这意味着 GN 自动支持一种组合泛化形式(因为图是由边、节点和全局特征组成的,GN 可以操作不同数量的边和节点)
4.Design Principles
有了 GN 架构,我们再来看下基于 GN 结构设计模型的原则。
一般来说,GN 架构并不局限于属性的表示和函数的形式,但是在这里我们更关注深度学习,所以这里将介绍 GN 设计为 Graph2Graph 的方法。
4.1 Flexible representations
首先要考虑灵活性,GN 的灵活性体现在两点:属性值的表征灵活性与图结构本身的灵活性。
4.1.1 Attributes
首先来看属性。
GN 支持 GLobal,Node,Edge 三种表现形式,且属性可以使用任意的形式进行表达。属性的表示通常跟着问题的需求来决定,如,输入数据为图像,属性就是像素点的张量;如果数据是文本,则属性可能是句子对应的单词序列。
GN 的输出也可以根据任务进行调整,如边输出、节点输出和全局输出。
当然也可以三者混合。
4.1.2 Graph structure
对于图结构来说,通常有两种情况,一种是输入显式的指定关系结构;另一种是需要推断或者假设其关系结构。
前者是具有更明确指定实体和关系的数据示例,包括知识图、社会网络、解析树、优化问题、化学图、道路网络和具有已知交互的物理系统。
后者的关系结构不明确,必须推断或假设的数据示例,包括可视场景、文本语料库、编程语言源代码等。在这些类型的设置中,数据可以被格式化为一组没有关系的实体,甚至只是一个向量或张量(如图像)。如果没有显式地指定实体,可以假设实体是一个节点,例如,将一个句子中的每个单词或CNN输出特征图中的每个局部特征向量视为一个节点,或者可以使用单独的学习机制从非结构化信号中推断实体。
4.2 Configurable within-block structure
GN block 中的结构和功能可以以不同的方式进行定制,这便提供了信息的输入和输出,以及更新的灵活性。通过这样的个性化定制,我们可以得到不同的网络模型。如下图所示:
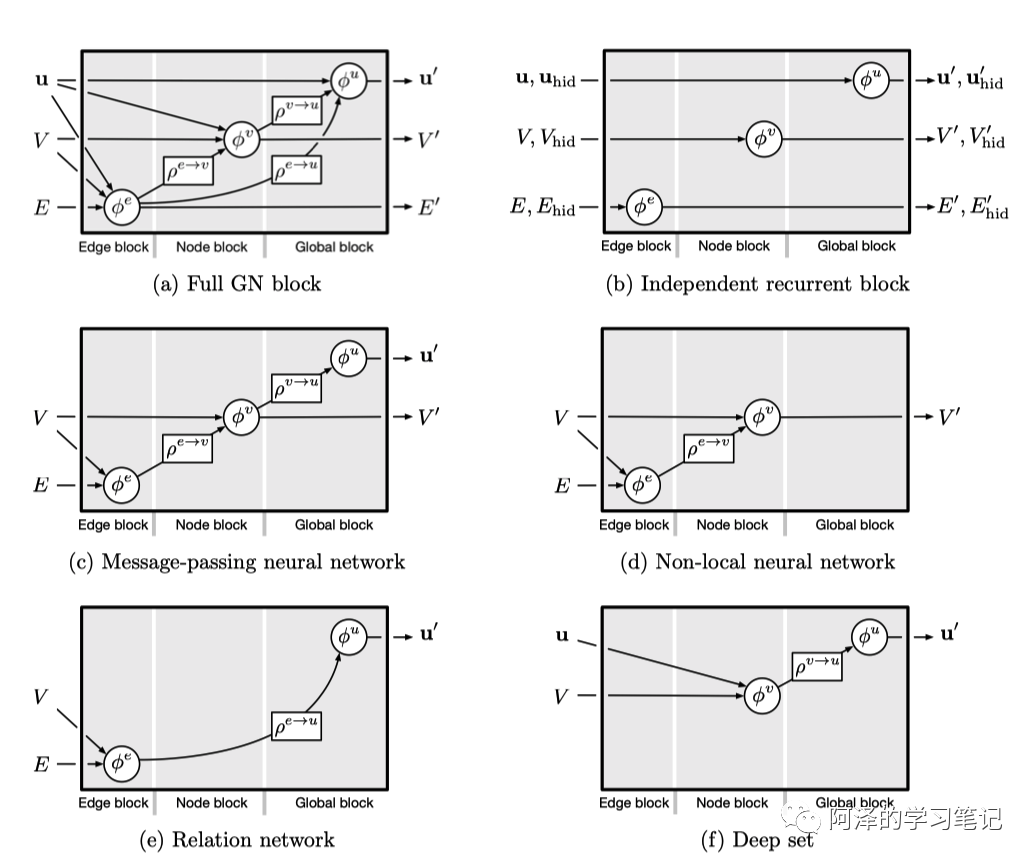
我们举几个例子,对于 MPNN 来说:
-
消息函数 在 GN 中为 ,但是不考虑全局信息 作为输入; -
信息聚合对应于 GN 中的 ; -
更新函数 为 GN 中的 ; -
读出函数 R 为 GN 中的 ,不考虑全局信息 和 作为输入;
对于 NLNN 来说:
其中, 是一个未经过归一化的权重系数, 是一个向量。
和前面的 GN 框架进行对比时会发现顺序发生了一点变化,刚刚也说了,顺序是可以调整的。
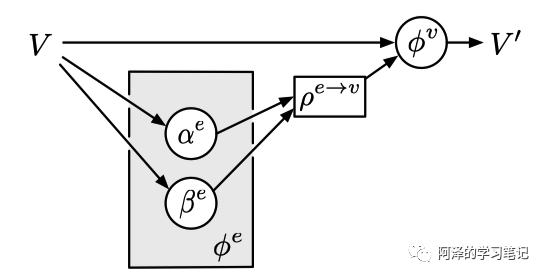
当然我们还可以有很多其他的变种,这里就不一一介绍了。
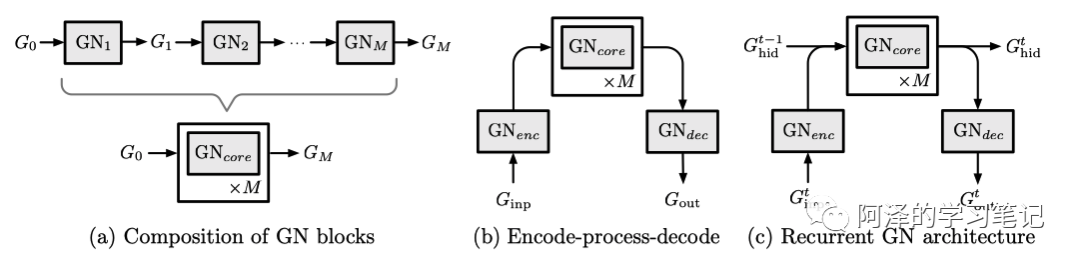
4.3 Composable multi-block architectures
由于 GN 的输入输出都是 Graph,所以我们可以直接对其进行组合: 。
不同的 GN block 组合起来可以复用内部的函数,可以像 LSTM 和 GRU 一样,而不是简单的合并起来。
GN 的一些堆叠结构如下图所示:
5.Discussion
本文作者分析了关系归纳偏置在深度学习架构中存在的程度,如 MLP、GNN 和 RNN,并得出结论:虽然 CNN 和 RNN 存在关系归纳偏差,但是它们并不能处理更结构化的表示,如集合或图。所以作者提出了深度学习体系结构中具有更强的关系归纳偏置的图网络 GN,可以在 Graph 数据上执行计算,并且 GN 统一了目前的很多方法,并为 GN 组装成更复杂的体系结构提供了一个简单的结构。
关于组合泛化能力,作者指出 GN 的结构天然支持泛化,因为其计算并不是在整个系统的宏观层面上执行的,并且在计算各个实体和关系上具有复用性,这是的之前从来没有见过的节点也能够对其进行处理。
但 GN 也有一些局限性,一方面是指有些问题无法解决,如无法区分非同构的 Graph 等;另一方面是有些问题并不能直接用 Graph 表示,比如说递归、控制流、条件迭代等。
由于 GN 的行为和人类对世界的理解类似,都是将世界解释成物体和相互关系组成的,因此 GN 的行为可能会更加容易解释,也更加易于分析和可视化。探索 GN 的可解释性也是未来一个有趣的方向。
6.Reference
-
Battaglia P W, Hamrick J B, Bapst V, et al. Relational inductive biases, deep learning, and graph networks[J]. arXiv preprint arXiv:1806.01261, 2018. -
Github: deepmind/graph_nets -
《Relational inductive biases, deep learning, and graph networks》
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

